Inleiding
Relational database werd rond 1969 voorgesteld door Edgar Codd (van IBM Research). Het is sindsdien het dominante databasemodel voor commerciële toepassingen geworden (in vergelijking met andere databasemodellen zoals hiërarchische, netwerk-en objectmodellen). Tegenwoordig zijn er veel commercial Relational Database Management System (RDBMS), zoals Oracle, IBM DB2 en Microsoft SQL Server., Er zijn ook veel gratis en open-source RDBM ‘ s, zoals MySQL, mSQL (mini-SQL) en de embedded JavaDB (Apache Derby).
een relationele database organiseert gegevens in tabellen (of relaties). Een tabel bestaat uit rijen en kolommen. Een rij wordt ook wel een record (of tupel) genoemd. Een kolom wordt ook wel een veld (of attribuut) genoemd. Een database tabel is vergelijkbaar met een spreadsheet. Echter, de relaties die kunnen worden gemaakt tussen de tabellen in staat stellen een relationele database om efficiënt enorme hoeveelheid gegevens op te slaan, en effectief geselecteerde gegevens op te halen.,
een taal genaamd SQL (Structured Query Language) werd ontwikkeld om te werken met relationele databases.
databaseontwerp doelstelling
Een goed ontworpen database moet:
- gegevensredundantie elimineren: hetzelfde stuk gegevens mag niet op meer dan één plaats worden opgeslagen. Dit komt omdat dubbele gegevens niet alleen afval opslagruimten, maar ook gemakkelijk leiden tot inconsistenties.
- zorg voor gegevensintegriteit en nauwkeurigheid:
- meer
relationeel databaseontwerp proces
databaseontwerp is meer kunst dan wetenschap, omdat je veel beslissingen moet nemen., Databases worden meestal aangepast aan een bepaalde toepassing. Geen twee aangepaste toepassingen zijn hetzelfde, en dus, geen twee database zijn hetzelfde. Richtlijnen (meestal in termen van wat niet te doen in plaats van wat te doen) zijn voorzien in het maken van deze ontwerpbeslissing, maar de keuzes uiteindelijk berusten op de U – de ontwerper.
Stap 1: Definieer het doel van de Database (Requirement Analysis)
Verzamel de vereisten en definieer het doel van uw database, bijvoorbeeld …
Het opstellen van de voorbeeldinvoerformulieren, query ‘ s en rapporten helpt vaak.,
Stap 2: Verzamel gegevens, organiseer in tabellen en specificeer de primaire sleutels
zodra u het doel van de database hebt bepaald, verzamel de gegevens die nodig zijn om in de database te worden opgeslagen. Verdeel de gegevens in op onderwerpen gebaseerde tabellen.
Kies één kolom (of enkele kolommen) als de zogenaamde primaire sleutel, die elk van de rijen uniek identificeert.
primaire sleutel
in het relationele model kan een tabel geen dubbele rijen bevatten, omdat dat dubbelzinnigheden zou creëren bij het ophalen., Om de uniciteit te garanderen, moet elke tabel een kolom (of een reeks kolommen) hebben, de zogenaamde primaire sleutel, die elke records van de tabel uniek identificeert. Bijvoorbeeld, een uniek nummer customerID kan worden gebruikt als de primaire sleutel voor de Customers tabel productCode voor Products tabel isbn voor Books tabel. Een primaire sleutel wordt een eenvoudige sleutel genoemd als het een enkele kolom is; het wordt een samengestelde sleutel genoemd als het uit meerdere kolommen bestaat.,
De meeste RDBMSs ‘ s bouwen een index op de primaire sleutel om snel zoeken en ophalen te vergemakkelijken.
de primaire sleutel wordt ook gebruikt om te verwijzen naar andere tabellen (die later zullen worden uitgewerkt).
u moet beslissen welke kolom(s) gebruikt moet worden voor de primaire sleutel. De beslissing is misschien niet eenvoudig, maar de primaire sleutel moet deze eigenschappen hebben:
- de waarden van de primaire sleutel moeten uniek zijn (d.w.z. geen dubbele waarde)., Bijvoorbeeld,
customerNamekan niet geschikt zijn om te worden gebruikt als de primaire sleutel voor deCustomerstabel, omdat er twee klanten met dezelfde naam kunnen zijn. - de primaire sleutel moet altijd een waarde hebben. Met andere woorden, het mag geen NULL bevatten.
overweeg het volgende in kies de primaire sleutel:
- de primaire sleutel moet eenvoudig en vertrouwd zijn, bijvoorbeeld
employeeIDvooremployeestabel enisbnvoorbookstabel., - de waarde van de primaire sleutel mag niet veranderen. Primaire sleutel wordt gebruikt om te verwijzen naar andere tabellen. Als u de waarde ervan wijzigt, moet u alle referenties wijzigen; anders zullen de verwijzingen verloren gaan. Bijvoorbeeld,
phoneNumberkan niet geschikt zijn om te worden gebruikt als primaire sleutel voor tabelCustomers, omdat het kan veranderen. - primaire sleutel gebruikt vaak integer (of getal) type. Maar het kunnen ook andere types zijn, zoals teksten. Het is echter het beste om numerieke kolom te gebruiken als primaire sleutel voor efficiëntie.
- primaire sleutel kan een willekeurig getal aannemen., De meeste RDBMS ‘ en ondersteunen zogenaamde auto-increment (of
AutoNumbertype) voor integer primaire sleutel, waarbij (huidige maximale waarde + 1) is toegewezen aan het nieuwe record. Dit willekeurige getal is feiten-minder, omdat het geen feitelijke informatie bevat. In tegenstelling tot feitelijke informatie zoals telefoonnummer, fact-less nummer is ideaal voor primaire sleutel, omdat het niet verandert. - primaire sleutel is meestal een enkele kolom (bijvoorbeeld
customerIDofproductCode). Maar het kan ook bestaan uit verschillende kolommen. Gebruik zo weinig mogelijk kolommen.,
Let’s illustrate with an example: a table customers contains columns lastName, firstName, phoneNumber, address, city, state, zipCode. The candidates for primary key are name=(lastName, firstName), phoneNumber, Address1=(address, city, state), Address1=(address, zipCode). Name may not be unique. Phone number and address may change., Daarom is het beter om een fact-less auto-increment getal aan te maken, zeg customerID, als de primaire sleutel.
Stap 3: Creëer relaties tussen tabellen
een database bestaande uit onafhankelijke en niet-gerelateerde tabellen heeft weinig nut (u kunt overwegen om in plaats daarvan een spreadsheet te gebruiken). De kracht van relationele database ligt in de relatie die kan worden gedefinieerd tussen tabellen. Het meest cruciale aspect bij het ontwerpen van een relationele database is het identificeren van de relaties tussen tabellen., De soorten relaties zijn:
- one-to-many
- many-to-many
- one-to-one
One-to-Many
in een “class roster” database kan een leraar nul of meer klassen onderwijzen, terwijl een klasse wordt onderwezen door één (en slechts één) leraar. In een” bedrijf ” – database beheert een manager nul of meer werknemers, terwijl een werknemer wordt beheerd door één (en slechts één) manager. In een” product sales ” database, een klant kan veel bestellingen plaatsen; terwijl een bestelling wordt geplaatst door een bepaalde klant. Dit soort relatie staat bekend als één-op-velen.,
Een-tot-veel relatie kan niet worden weergegeven in een enkele tabel. Bijvoorbeeld, in een “class roster” database, kunnen we beginnen met een tabel genaamd Teachers, die informatie over leraren opslaat (zoals name, office, phone en email). Om de lessen van elke leraar op te slaan, kunnen we kolommen maken class1, class2, class3, maar er is direct een probleem met het aantal kolommen dat moet worden aangemaakt., Aan de andere kant, als we beginnen met een tabel met de naam Classes, waarin informatie wordt opgeslagen over een klasse (courseCode, dayOfWeek, timeStart en timeEnd); we kunnen maken in een extra kolom om informatie op te slaan over de (één) docent (zoals name, office, phone en email). Aangezien een leraar echter vele klassen kan onderwijzen, zouden de gegevens in vele rijen in tabel Classesworden gedupliceerd.,
om een één-op-veel relatie te ondersteunen, moeten we twee tabellen ontwerpen: een tabel Classes om informatie op te slaan over de klassen met classID als primaire sleutel; en een tabel Teachers om informatie op te slaan over leraren met teacherID als de primaire sleutel. We kunnen dan de een-op-veel relatie creëren door de primaire sleutel van de tabel Teacher (d.w.z.,, teacherID) (de”one”-end of de oudertabel) in de tabel classes (De”many” -end of de dochtertabel), zoals hieronder geïllustreerd.
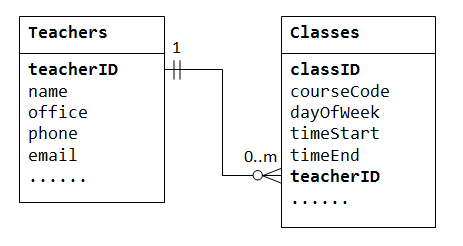
de kolom teacherID in de dochtertabel Classes staat bekend als de vreemde sleutel. Een vreemde sleutel van een dochtertabel is een primaire sleutel van een oudertabel, die wordt gebruikt om naar de oudertabel te verwijzen.
merk op dat er voor elke waarde in de bovenliggende tabel nul, één of meer rijen in de onderliggende tabel kunnen zijn., Voor elke waarde in de dochtertabel is er slechts één rij in de bovenliggende tabel.
Many-to-Many
in een” product sales ” – database kan de bestelling van een klant een of meer producten bevatten; een product kan in veel bestellingen voorkomen. In een” boekhandel ” database, een boek is geschreven door een of meer auteurs; terwijl een auteur kan schrijven nul of meer boeken. Dit soort relatie staat bekend als many-to-many.
laten we illustreren met een “product sales” database. We beginnen met twee tabellen: Products en Orders., De tabel products bevat informatie over de producten (zoals name, description en quantityInStock) met productID als primaire sleutel. De tabel orders bevat orders van klanten (customerID, dateOrdered, dateRequired en status). Nogmaals, we kunnen de bestelde items niet opslaan in de Orders tabel, omdat we niet weten hoeveel kolommen we moeten reserveren voor de items., We kunnen de orderinformatie ook niet opslaan in de Products tabel.
om veel-tot-veel relatie te ondersteunen, moeten we een derde tabel maken (bekend als een junction table), zeg OrderDetails (of OrderLines), waarbij elke rij een item van een bepaalde volgorde vertegenwoordigt. Voor de tabel OrderDetails bestaat de primaire sleutel uit twee kolommen: orderID en productID, die elke rij uniek identificeren., De kolommen orderID en productID in OrderDetails tabel worden gebruikt om te verwijzen naar Orders en Products tabellen, vandaar dat ze ook de vreemde sleutels zijn in de OrderDetails tabel.
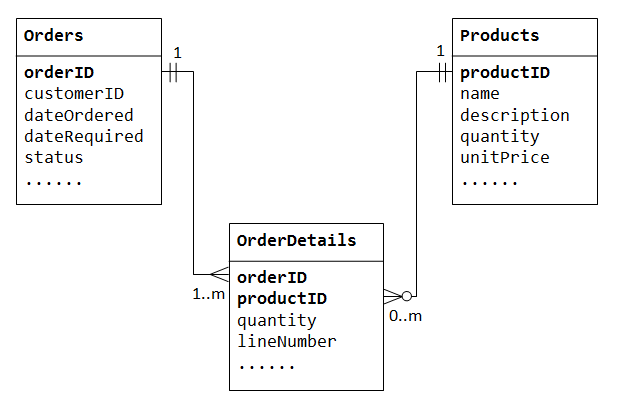
de veel-tot-veel relatie is in feite geïmplementeerd als twee een-tot-veel relaties, met de introductie van de junction table.
- een order heeft veel items in
OrderDetails. EenOrderDetailsitem behoort tot één bepaalde volgorde., - een product kan voorkomen in vele
OrderDetails. ElkOrderDetailsitem specificeerde één product.
één-op-één
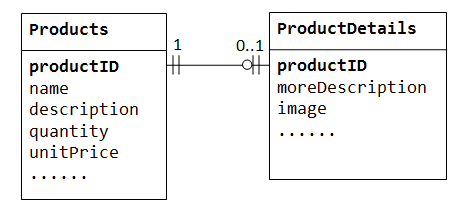
in een databank “product sales” kan een product facultatieve aanvullende informatie bevatten, zoals image, moreDescription en comment. Ze binnen de Products tabel houden resulteert in veel lege ruimtes (in die records zonder deze optionele gegevens). Bovendien kunnen deze grote gegevens de prestaties van de database aantasten.,
in plaats daarvan kunnen we een andere tabel maken (zeg ProductDetails, ProductLines of ProductExtras) om de optionele gegevens op te slaan. Er wordt alleen een record aangemaakt voor producten met optionele gegevens. De twee tabellen, Products en ProductDetails, vertonen een één-op-één relatie. Dat wil zeggen, voor elke rij in de oudertabel, is er maximaal één rij (mogelijk nul) in de dochtertabel. Dezelfde kolom productID moet worden gebruikt als de primaire sleutel voor beide tabellen.,
sommige databases beperken het aantal kolommen dat in een tabel kan worden gemaakt. U kunt een één-op-één relatie gebruiken om de gegevens in twee tabellen op te splitsen. Een-op-een relatie is ook nuttig voor het opslaan van bepaalde gevoelige gegevens in een veilige tabel, terwijl de niet-gevoelige in de hoofdtabel.
Kolomgegevenstypen
u moet voor elke kolom een geschikt gegevenstype kiezen. Veel voorkomende gegevenstypen zijn: gehele getallen, floating-point getallen, string( of tekst), datum/tijd, binair, verzameling (zoals opsomming en set).,
Stap 4: Verfijn & normaliseer het ontwerp
bijvoorbeeld
- voeg meer kolommen toe,
- Maak een nieuwe tabel voor optionele gegevens met behulp van een-op-een relatie,
- splits een grote tabel in twee kleinere tabellen,
- andere.
normalisatie
Pas de zogenaamde normalisatieregels toe om te controleren of uw database structureel correct en optimaal is.
eerste normale vorm (1NF): een tabel is 1NF als elke cel een enkele waarde bevat, niet een lijst met waarden. Deze eigenschappen staan bekend als atomair., 1NF verbiedt ook het herhalen van groepen kolommen zoals item1, item2.., itemN. In plaats daarvan, moet u een andere tabel met behulp van een-op-veel relatie.
tweede normale vorm (2NF): een tabel is 2NF, als het 1NF is en elke niet-sleutelkolom volledig afhankelijk is van de primaire sleutel. Indien de primaire sleutel uit meerdere kolommen bestaat, moet elke niet-sleutelkolom bovendien afhangen van de gehele verzameling en niet van een deel ervan.,
bijvoorbeeld de primaire sleutel van de tabelOrderDetails bestaande uitorderID enproductID. Indien unitPrice alleen afhankelijk is van productID, mag het niet worden bewaard in de OrderDetails tabel (maar in de Products tabel). Aan de andere kant, als de unitPrice afhankelijk is van het product en de specifieke volgorde, moet deze worden bewaard in de OrderDetails tabel.,
derde normale vorm (3NF): een tabel is 3NF, als het 2NF is en de niet-sleutelkolommen onafhankelijk van elkaar zijn. Met andere woorden, de niet-sleutelkolommen zijn afhankelijk van de primaire sleutel, alleen van de primaire sleutel en niets anders. Stel bijvoorbeeld dat we een Products tabel hebben met kolommen productID (primaire sleutel), name en unitPrice., De kolom discountRate mag niet tot Products tabel behoren indien deze ook afhankelijk is van de unitPrice, die geen deel uitmaakt van de primaire sleutel.
Hogere normale vorm: 3NF heeft zijn onvolkomenheden, wat leidt tot hogere normale vorm, zoals Boyce/Codd normale vorm, vierde normale vorm (4NF) en vijfde normale vorm (5NF), wat buiten het bestek van deze handleiding valt.
soms kunt u besluiten om een aantal van de normalisatieregels te breken, om redenen van prestatie (bijv.,, een kolom aanmaken met de naam totalPrice in Orders tabel die kan worden afgeleid van de orderDetails records); of omdat de eindgebruiker erom heeft gevraagd. Zorg ervoor dat je je er volledig van bewust bent, ontwikkel programmeerlogica om het te verwerken en documenteer de beslissing correct.
integriteitsregels
u moet de integriteitsregels ook toepassen om de integriteit van uw ontwerp te controleren:
Entity Integriteitsregel: de primaire sleutel kan geen NULL bevatten. Anders kan het de rij niet uniek identificeren., Voor samengestelde sleutel die uit meerdere kolommen bestaat, kan geen enkele kolom NULL bevatten. De meeste RDBMS controleren en handhaven deze regel.
referentiële Integriteitsregel: elke buitenlandse sleutelwaarde moet overeenkomen met een primaire sleutelwaarde in de tabel waarnaar wordt verwezen (of bovenliggende tabel).
- u kunt alleen een rij met een vreemde sleutel in de dochtertabel invoegen als de waarde in de bovenliggende tabel bestaat.
- als de waarde van de sleutel in de bovenliggende tabel verandert (bijvoorbeeld de rij bijgewerkt of verwijderd), moeten alle rijen met deze vreemde sleutel in de onderliggende tabel(en) dienovereenkomstig worden behandeld., U kunt ofwel (a) de wijzigingen niet toestaan; (b) de wijziging in een cascade plaatsen (of de records verwijderen) in de onderliggende tabellen; (c) de sleutelwaarde in de onderliggende tabellen instellen op NULL.
De meeste RDBM ‘ s kunnen worden ingesteld om de controle uit te voeren en de referentiële integriteit te garanderen, op de opgegeven manier.
Business logic Integrity: naast de bovenstaande twee algemene integriteitsregels, zou er integriteit (validatie) kunnen zijn met betrekking tot de business logic, bijv.,, postcode is 5-cijferig binnen een bepaald bereik, leveringsdatum en-tijd vallen in de kantooruren; bestelde hoeveelheid is gelijk of kleiner dan hoeveelheid in voorraad, enz. Deze kunnen worden uitgevoerd in validatieregel (voor de specifieke kolom) of programmeerlogica.
Kolomindexering
u kunt index maken op geselecteerde kolommen om het zoeken en ophalen van gegevens te vergemakkelijken. Een index is een gestructureerd bestand dat de toegang tot gegevens versnelt voor SELECT, maar INSERT, UPDATE, en DELETEkan vertragen., Zonder indexstructuur moet de database-engine alle records in de tabel vergelijken om een SELECT query te verwerken met een matchingcriterium (bijvoorbeeld SELECT * FROM Customers WHERE name='Tan Ah Teck'). Een gespecialiseerde index (bijvoorbeeld in btree-structuur) kan het record bereiken zonder elke records te vergelijken. Echter, de index moet worden herbouwd wanneer een record wordt gewijzigd, wat resulteert in overhead geassocieerd met het gebruik van indexen.
Index kan worden gedefinieerd op een enkele kolom, een verzameling kolommen (genaamd concatenated index), of een deel van een kolom (bijv.,, eerste 10 karakters van een VARCHAR(100)) (partiële index genoemd) . U kunt meer dan één index in een tabel bouwen. Als u bijvoorbeeld vaak naar een klant zoekt met customerName of phoneNumber, kunt u de zoekopdracht versnellen door een index op de kolom te bouwen customerName, evenals phoneNumber. De meeste RDBMS bouwt index op de primaire sleutel automatisch.
referenties & bronnen
Laatst getest: MySQL 5.5.15
Laatst gewijzigd: September 2010