Introduction
base de données relationnelle a été proposé par Edgar Codd (D’IBM Research) vers 1969. Il est depuis devenu le modèle de base de données dominant pour les applications commerciales (en comparaison avec d’autres modèles de base de données tels que les modèles hiérarchiques, réseau et objets). Aujourd’hui, il existe de nombreux systèmes de gestion de base de données relationnelle commerciale (SGBDR), tels que Oracle, IBM DB2 et Microsoft SQL Server., Il existe également de nombreux SGBDR gratuits et open-source, tels que MySQL, mSQL (mini-SQL) et le JavaDB intégré (Apache Derby).
Une base de données relationnelle organise les données dans des tableaux (ou des relations). Un tableau est composé de lignes et de colonnes. Une ligne est également appelée un enregistrement (ou tuple). Une colonne est également appelée champ (ou attribut). Une table de base de données est similaire à une feuille de calcul. Cependant, les relations qui peuvent être créées entre les tables permettent à une base de données relationnelle de stocker efficacement une énorme quantité de données et de récupérer efficacement les données sélectionnées.,
un langage appelé SQL (Structured Query Language) a été développé pour fonctionner avec des bases de données relationnelles.
objectif de conception de la base de données
Une base de données bien conçue doit:
- éliminer la redondance des données: la même donnée ne doit pas être stockée à plus d’un endroit. En effet, les données en double non seulement gaspillent des espaces de stockage, mais conduisent également facilement à des incohérences.
- assurer L’intégrité et la précision des données:
- Plus
processus de conception de base de données relationnelle
La conception de base de données est plus un art qu’une science, car vous devez prendre de nombreuses décisions., Les bases de données sont généralement personnalisées en fonction d’une application particulière. Il n’y a pas deux applications personnalisées qui se ressemblent et, par conséquent, il n’y a pas deux bases de données qui se ressemblent. Des directives (généralement en termes de ce qu’il ne faut pas faire au lieu de ce qu’il faut faire) sont fournies pour prendre ces décisions de conception, mais les choix reposent finalement sur vous – le concepteur.
Étape 1: Définir le but de la base de données (Analyse des exigences)
rassemblez les exigences et définissez l’objectif de votre base de données, par exemple …
la rédaction d’exemples de formulaires de saisie, de requêtes et de rapports est souvent utile.,
Étape 2: rassemblez les données, organisez-les dans des tables et spécifiez les clés primaires
Une fois que vous avez décidé de l’objectif de la base de données, rassemblez les données qui doivent être stockées dans la base de données. Divisez les données en tableaux par sujet.
Choisissez une colonne (ou quelques colonnes) comme clé primaire, qui identifie de manière unique chacune des lignes.
clé primaire
dans le modèle relationnel, une table ne peut pas contenir de lignes en double, car cela créerait des ambiguïtés dans la récupération., Pour garantir l’unicité, chaque table doit avoir une colonne (ou un ensemble de colonnes), appelé clé primaire, qui identifie de manière unique tous les enregistrements de la table. Par exemple, un numéro unique customerID peut être utilisé en tant que clé primaire de la Customers tableau; productCode par Products tableau; isbn par Books tableau. Une clé primaire est appelé une simple clé si c’est une seule colonne; il est appelé une clé composite si elle est composée de plusieurs colonnes.,
la plupart des SGBDR construisent un index sur la clé primaire pour faciliter la recherche et la récupération rapides.
la clé primaire est également utilisée pour référencer d’autres tables (à élaborer plus tard).
Vous devez décider quelles colonnes doivent être utilisées pour la clé primaire. La décision peut ne pas être simple, mais la clé primaire doit avoir ces propriétés:
- Les valeurs de la clé primaire doivent être uniques (c.-à-d., aucune valeur en double)., Par exemple,
customerNamepeut ne pas être approprié pour être utilisé comme clé primaire pour la tableCustomers, car il pourrait y avoir deux clients avec le même nom. - La clé primaire doit toujours avoir une valeur. En d’autres termes, il ne doit pas contenir NULL.
de Considérer les points suivants à choisir la clé primaire:
- La clé primaire doit être simple et familière, par exemple, la balise
employeeIDparemployeestable etisbnparbookstableau., - La valeur de la clé primaire ne devrait pas changer. La clé primaire est utilisée pour référencer d’autres tables. Si vous modifiez sa valeur, vous devez changer toutes ses références; sinon, les références seront perdues. Par exemple,
phoneNumberpeut ne pas être approprié pour être utilisé comme clé primaire pour la tableCustomers, car il pourrait changer. - La clé primaire utilise souvent le type entier (ou nombre). Mais il pourrait aussi s’agir d’autres types, tels que des textes. Cependant, il est préférable d’utiliser le numérique colonne comme clé primaire pour plus d’efficacité.
- clé Primaire peut prendre un nombre arbitraire., La plupart des SGBDR prennent en charge l’incrément automatique (ou le type
AutoNumber) pour la clé primaire entière, où (valeur maximale actuelle + 1) est affectée au nouvel enregistrement. Ce nombre arbitraire est sans fait, car il ne contient aucune information factuelle. Contrairement aux informations factuelles telles que le numéro de téléphone, le numéro sans faits est idéal pour la clé primaire, car il ne change pas. - la clé Primaire est généralement une seule colonne (par exemple,
customerIDouproductCode). Mais il pourrait aussi se composer de plusieurs colonnes. Vous devez utiliser le moins de colonnes possible.,
Let’s illustrate with an example: a table customers contains columns lastName, firstName, phoneNumber, address, city, state, zipCode. The candidates for primary key are name=(lastName, firstName), phoneNumber, Address1=(address, city, state), Address1=(address, zipCode). Name may not be unique. Phone number and address may change., Par conséquent, il est préférable de créer un nombre d’incrément automatique sans faits, disons customerID, comme clé primaire.
Étape 3: Créer des relations entre les Tables
Une base de données composée de tables indépendantes et non apparentées ne sert à rien (vous pouvez envisager d’utiliser une feuille de calcul à la place). La puissance de la base de données relationnelle réside dans la relation qui peut être définie entre les tables. L’aspect le plus crucial dans la conception d’une base de données relationnelle est d’identifier les relations entre les tables., Les types de relation:
- un-à-plusieurs
- plusieurs-à-plusieurs
- un-à-un
Un-à-Plusieurs
Dans une « liste » de la base de données, un professeur peut enseigner zéro, une ou plusieurs classes, alors qu’une classe est enseignée par un (et un seul) des enseignants. Dans une base de données « entreprise », un gestionnaire gère zéro ou plusieurs employés, tandis qu’un employé est géré par un (et un seul) gestionnaire. Dans une base de données « ventes de produits », un client peut passer plusieurs commandes; alors qu’une commande est passée par un client particulier. Ce type de relation est connu comme un à plusieurs.,
la relation un à plusieurs ne peut pas être représentée dans une seule table. Par exemple, dans une « liste » de la base de données, nous pouvons commencer avec une table appelée Teachers, qui stocke des informations sur les enseignants (name, office, phone et email). Pour stocker les classes enseignées par chaque enseignant, nous avons pu créer des colonnes class1, class2, class3, mais il est confronté à un problème immédiatement sur le nombre de colonnes à créer., D’autre part, si nous commençons avec une table appelée Classes, qui stocke des informations sur une classe (courseCode, dayOfWeek, timeStart et timeEnd); on pourrait créer des colonnes supplémentaires pour stocker des informations sur le (un) enseignant (name, office, phone et email). Cependant, comme un enseignant peut enseigner de nombreuses classes, ses données seraient dupliquées dans de nombreuses lignes du tableau Classes.,
pour prendre en charge une relation un à plusieurs, nous devons concevoir deux tables: une table Classespour stocker des informations sur les classes avec classIDcomme clé primaire; et une table Teacherspour stocker des informations sur les enseignants avec teacherID comme clé primaire. Nous pouvons ensuite créer la relation un à plusieurs en stockant la clé primaire de la table Teacher (c’est-à-dire,, teacherID) (la « une »de fin ou de la table parent) dans la table classes (le « beaucoup »ou de la table d’enfant), comme illustré ci-dessous.
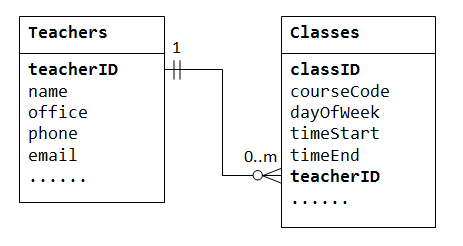
La colonne teacherID dans la table enfant Classes est connu comme la clé étrangère. Une clé étrangère d’une table d’enfant est une clé primaire d’une table parent, utilisé pour faire référence à la table parent.
notez que pour chaque valeur de la table parent, il peut y avoir zéro, une ou plusieurs lignes dans la table enfant., Pour chaque valeur dans la table enfant, il y a une et une seule ligne dans la table parent.
plusieurs à plusieurs
dans une base de données « ventes de produits », la commande d’un client peut contenir un ou plusieurs produits; et un produit peut apparaître dans de nombreuses commandes. Dans une base de données « librairie », un livre est écrit par un ou plusieurs auteurs; alors qu’un auteur peut écrire zéro ou plusieurs livres. Ce genre de relation est connu comme plusieurs à plusieurs.
illustrons avec une base de données « product sales ». Nous commençons avec deux tables: Products et Orders., La table products contient des informations sur les produits (tels que le name, description et quantityInStock) avec productID comme clé primaire. La table orders contient les commandes des clients (customerID, dateOrdered, dateRequired et status). Encore une fois, nous ne pouvons pas stocker les éléments commandés dans la table Orders, car nous ne savons pas combien de colonnes réserver pour les éléments., Nous ne pouvons pas non plus stocker les informations de commande dans la table Products.
À l’appui de plusieurs-à-plusieurs relations, nous avons besoin de créer une troisième table (appelée table de jonction), dire OrderDetails (ou OrderLines), où chaque ligne représente un élément d’un ordre particulier. Pour la tableOrderDetails, la clé primaire se compose de deux colonnes:orderID EtproductID, qui identifient de manière unique chaque ligne., Les colonnes orderID et productID dans un OrderDetails table de référence Orders et Products tables, par conséquent, ils sont également les clés étrangères dans le OrderDetails tableau.
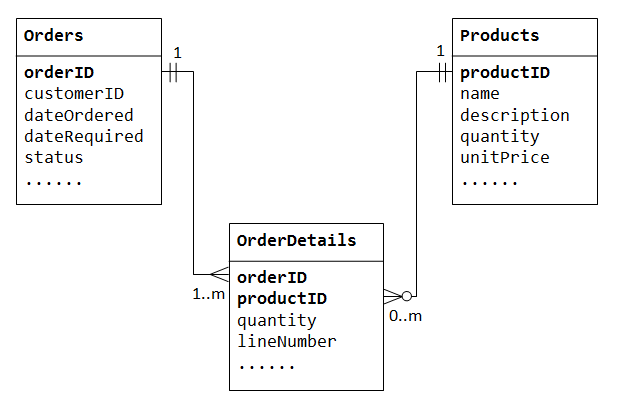
la relation plusieurs à plusieurs est, en fait, implémentée comme deux relations un à plusieurs, avec l’introduction de la table de jonction.
- Une commande contient de nombreux éléments dans
OrderDetails. Un élémentOrderDetailsappartient à une commande particulière., - Un produit peut apparaître dans de nombreux
OrderDetails. Chaque élémentOrderDetailsspécifiait un produit.
un-à-Un
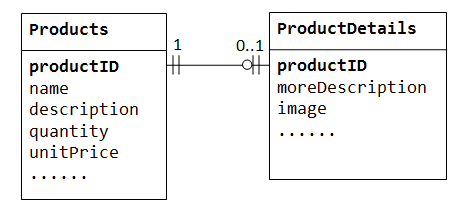
Dans une « vente de produits » de base de données, un produit peut avoir en option des informations supplémentaires telles que image, moreDescription et comment. Les conserver dans la table Products entraîne de nombreux espaces vides (dans ces enregistrements sans ces données facultatives). De plus, ces données volumineuses peuvent dégrader les performances de la base de données.,
au Lieu de cela, nous pouvons créer une autre table (disons ProductDetails, ProductLines ou ProductExtras) pour stocker les données en option. Un enregistrement ne sera créé que pour les produits avec des données facultatives. Les deux tables,Products EtProductDetails, présentent une relation un à un. C’est, pour chaque ligne dans la table parent, il y a au plus une ligne (éventuellement zéro) dans la table enfant. La même colonne productID doit être utilisée comme clé primaire pour les deux tables.,
certaines bases de données limitent le nombre de colonnes pouvant être créées dans une table. Vous pouvez utiliser une relation un à un pour diviser les données en deux tables. La relation un à un est également utile pour stocker certaines données sensibles dans une table sécurisée, tandis que les non sensibles dans la table principale.
Types de Données des Colonnes
Vous devez choisir un type de données approprié pour chaque colonne. Généralement, les types de données incluent: entiers, nombres à virgule flottante, chaîne (ou texte), date/heure, binaire, collection (comme l’énumération et set).,
Étape 4: Affiner & Normaliser la Conception
Par exemple,
- ajout de plusieurs colonnes,
- créer une nouvelle table pour l’option données à l’aide de l’un de relation,
- diviser une grande table en deux petites tables,
- les autres.
Normalization
appliquez les règles dites de normalisation pour vérifier si votre base de données est structurellement correcte et optimale.
première forme normale (1NF): une table est 1NF si chaque cellule contient une seule valeur, pas une liste de valeurs. Cette propriété est connue sous le nom d’atomique., 1FN interdit également la répétition d’un groupe de colonnes item1, item2,.., itemN. Au lieu de cela, vous devez créer une autre table en utilisant une relation un à plusieurs.
deuxième forme normale (2NF): une table est 2NF, si elle est 1NF et que chaque colonne non clé dépend entièrement de la clé primaire. En outre, si la clé primaire est composée de plusieurs colonnes, chaque colonne de la clé dépend de l’ensemble et n’en font pas partie.,
Par exemple, la clé primaire de la balise OrderDetails table composé de orderID et productID. Si unitPrice dépend seulement de productID, il ne doit pas être conservé dans le OrderDetails table (mais dans le Products tableau). D’autre part, si le unitPrice dépend du produit ainsi que de l’ordre particulier, alors il doit être conservé dans le OrderDetails tableau.,
troisième forme normale (3NF): une table est 3NF, si elle est 2NF et que les colonnes non clés sont indépendantes les unes des autres. En d’autres termes, les colonnes non clés dépendent de la clé primaire, uniquement de la clé primaire et rien d’autre. Par exemple, supposons que nous avons un Products table avec des colonnes productID (clé primaire), name et unitPrice., La colonne discountRate ne doit pas appartenir à la table Products si elle dépend également de la unitPrice, qui ne fait pas partie de la clé primaire.
Forme Normale Supérieure: 3NF a ses insuffisances, ce qui conduit à une forme normale supérieure, telle que la forme normale Boyce / Codd, la quatrième forme normale (4NF) et la cinquième forme normale (5NF), ce qui dépasse le cadre de ce tutoriel.
parfois, vous pouvez décider d’enfreindre certaines règles de normalisation, pour des raisons de performances (par exemple,, créez une colonne appelée totalPricedans Orderstable qui peut être dérivée des enregistrements orderDetails); ou parce que l’utilisateur final l’a demandé. Assurez-vous que vous en êtes pleinement conscient, développez une logique de programmation pour le gérer et documentez correctement la décision.
règles D’intégrité
Vous devez également appliquer les règles d’intégrité pour vérifier l’intégrité de votre conception:
règle D’intégrité D’entité: la clé primaire ne peut pas contenir NULL. Sinon, il ne peut pas identifier de manière unique la ligne., Pour la clé composite composée de plusieurs colonnes, aucune des colonnes ne peut contenir NULL. La plupart des SGBDR vérifient et appliquent cette règle.
règle D’intégrité référentielle: chaque valeur de clé étrangère doit correspondre à une valeur de clé primaire dans la table référencée (ou la table parent).
- Vous pouvez insérer une ligne de clé étrangère dans la table enfant uniquement si la valeur existe dans la table parent.
- Si la valeur de la clé change dans la table parent(par exemple, la ligne mise à jour ou supprimée), toutes les lignes avec cette clé étrangère dans la table enfant doivent être gérées en conséquence., Vous pouvez soit (a) interdire les modifications; (b) cascade la modification (ou supprimer les enregistrements) dans les tables enfants en conséquence; (c) définir la valeur de clé dans les tables enfants à NULL.
La plupart des SGBDR peuvent être configurés pour effectuer la vérification et assurer l’intégrité référentielle, de la manière spécifiée.
intégrité de la logique métier: outre les deux règles générales d’intégrité ci-dessus, il pourrait y avoir intégrité (validation) concernant la logique métier, par exemple,, le code postal doit être à 5 chiffres dans certaines plages, la date et l’Heure de livraison doivent tomber dans les heures ouvrables; la quantité commandée doit être égale ou inférieure à la quantité en stock, etc. Ceux-ci pourraient être effectués dans la règle de validation (pour la colonne spécifique) ou la logique de programmation.
indexation des colonnes
Vous pouvez créer un index sur la ou les colonnes sélectionnées pour faciliter la recherche et la récupération des données. Un index est un fichier structuré, qui accélère l’accès aux données pour les SELECT, mais peut ralentir INSERT, UPDATE et DELETE., Sans structure d’index, pour traiter une requêteSELECT avec un critère de correspondance (par exemple,SELECT * FROM Customers WHERE name='Tan Ah Teck'), le moteur de base de données doit comparer tous les enregistrements de la table. Un index spécialisé (par exemple, dans la structure BTREE) pourrait atteindre l’enregistrement sans comparer tous les enregistrements. Cependant, l’index doit être reconstruit chaque fois qu’un enregistrement est modifié, ce qui entraîne une surcharge associée à l’utilisation d’index.
L’Index peut être défini sur une seule colonne, un ensemble de colonnes (appelé index concaténé) ou une partie d’une colonne (par exemple,, les 10 premiers caractères d’unVARCHAR(100)) (appelé index partiel) . Vous pouvez construire plus d’un index dans une table. Par exemple, si vous avez souvent à la recherche pour un client en utilisant soit customerName ou phoneNumber, vous pouvez accélérer la recherche par la création d’un index sur la colonne customerName, ainsi que phoneNumber. La plupart des SGBDR construisent automatiquement l’index sur la clé primaire.
références & ressources
dernière version testée: MySQL 5.5.15
Dernière modification: septembre 2010