introduktion
relationsdatabas föreslogs av Edgar Codd (av IBM Research) runt 1969. Det har sedan dess blivit den dominerande databasmodellen för kommersiella applikationer (i jämförelse med andra databasmodeller som hierarkiska, nätverks-och objektmodeller). Idag finns det många kommersiella relationsdatabashanteringssystem (RDBMS), såsom Oracle, IBM DB2 och Microsoft SQL Server., Det finns också många gratis och öppen källkod RDBMS, såsom MySQL, mSQL (mini-SQL) och den inbyggda JavaDB (Apache Derby).
en relationsdatabas organiserar data i tabeller (eller relationer). En tabell består av rader och kolumner. En rad kallas också en post (eller tuple). En kolumn kallas också ett fält (eller attribut). En databastabell liknar ett kalkylblad. De relationer som kan skapas bland tabellerna gör det möjligt för en relationsdatabas att effektivt lagra stor mängd data och effektivt hämta valda data.,
ett språk som heter SQL (Structured Query Language) utvecklades för att fungera med relationsdatabaser.
Databasdesignmål
en väl utformad databas ska:
- eliminera dataredundans: samma datastycke får inte lagras på mer än en plats. Detta beror på att dubbla data inte bara avfallslagringsutrymmen utan också lätt leder till inkonsekvenser.
- säkerställa dataintegritet och noggrannhet:
- mer
Relationsdatabasdesign Process
databasdesign är mer konst än vetenskap, eftersom du måste fatta många beslut., Databaser är vanligtvis anpassade för att passa en viss applikation. Inga två anpassade applikationer är likadana, och därför är ingen två databas likadana. Riktlinjer (vanligtvis när det gäller vad man inte ska göra istället för vad man ska göra) tillhandahålls för att göra dessa designbeslut, men valen vilar i slutändan på dig – designern.
Steg 1: definiera syftet med databasen (kravanalys)
samla in kraven och definiera målet för din Databas, t .ex….
utarbetande av urvalsinmatningsformulär, frågor och rapporter hjälper ofta.,
steg 2: Samla in Data, organisera i tabeller och ange Primärnycklarna
När du har bestämt dig för syftet med databasen, samla in data som behövs för att lagras i databasen. Dela upp uppgifterna i ämnesbaserade tabeller.
Välj en kolumn (eller några kolumner) som den så kallade primärnyckeln, som unikt identifierar var och en av raderna.
primärnyckel
i relationsmodellen kan en tabell inte innehålla dubbla rader, eftersom det skulle skapa tvetydigheter vid hämtning., För att säkerställa unikhet bör varje tabell ha en kolumn (eller en uppsättning kolumner), kallad primärnyckel, som unikt identifierar alla poster i tabellen. Till exempel kan ett unikt nummer customerID användas som primärnyckel för tabellen Customers; productCode för tabellen Products; isbn för tabellen Books. En primär nyckel kallas en enkel nyckel om det är en enda kolumn; Det kallas en sammansatt Nyckel om den består av flera kolumner.,
de flesta RDBMSs bygger ett index på primärnyckeln för att underlätta snabb sökning och hämtning.
den primära nyckeln används också för att referera till andra tabeller (som ska utarbetas senare).
Du måste bestämma vilken kolumn(er) som ska användas för primärnyckel. Beslutet får inte vara rakt fram, men huvudnyckeln ska ha dessa egenskaper:
- värdena för primärnyckeln ska vara unika (dvs. inget dubblettvärde)., Till exempel kan
customerNameinte vara lämpligt att använda som primärnyckel för tabellenCustomers, eftersom det kan finnas två kunder med samma namn. - huvudnyckeln ska alltid ha ett värde. Med andra ord får den inte innehålla NULL.
överväga följande I välj primärnyckel:
- primärnyckeln ska vara enkel och välbekant, t. ex.
employeeIDföremployeestabell ochisbnförbookstabell., - värdet på primärnyckeln bör inte ändras. Primärnyckel används för att referera till andra tabeller. Om du ändrar dess värde måste du ändra alla referenser; annars kommer referenserna att gå förlorade. Till exempel kan
phoneNumberinte vara lämpligt att använda som primärnyckel för tabellCustomers, eftersom det kan ändras. - primärnyckel använder ofta heltal (eller tal) typ. Men det kan också vara andra typer, såsom texter. Det är dock bäst att använda numerisk kolumn som primärnyckel för effektivitet.
- primärnyckel kunde ta ett godtyckligt tal., De flesta rdbmss stöder så kallad auto-inkrement (eller
AutoNumbertyp) för heltals primärnyckel, där (nuvarande högsta värde + 1) tilldelas den nya posten. Detta godtyckliga antal är faktiskt mindre, eftersom det inte innehåller någon faktisk information. Till skillnad från faktainformation som telefonnummer är faktamindre nummer idealiskt för primärnyckel, eftersom det inte ändras. - primärnyckel är vanligtvis en enda kolumn (t.ex.
customerIDellerproductCode). Men det kan också utgöra flera kolumner. Du bör använda så få kolumner som möjligt.,
Let’s illustrate with an example: a table customers contains columns lastName, firstName, phoneNumber, address, city, state, zipCode. The candidates for primary key are name=(lastName, firstName), phoneNumber, Address1=(address, city, state), Address1=(address, zipCode). Name may not be unique. Phone number and address may change., Därför är det bättre att skapa ett faktumlöst Auto-inkrementnummer, säg customerID som primärnyckel.
steg 3: skapa relationer mellan tabeller
en databas som består av oberoende och orelaterade tabeller tjänar lite syfte (du kan överväga att använda ett kalkylblad istället). Kraften i relationsdatabasen ligger i förhållandet som kan definieras mellan tabeller. Den mest avgörande aspekten i utformningen av en relationsdatabas är att identifiera relationerna mellan tabeller., De typer av relation inkluderar:
- en-till-många
- många-till-många
- en-till-en
en-till-många
i en ”klass roster” Databas, en lärare kan lära noll eller fler klasser, medan en klass undervisas av en (och endast en) lärare. I en ”företagsdatabas” hanterar en chef noll eller flera anställda, medan en anställd hanteras av en (och endast en) chef. I en” produktförsäljning ” Databas, en kund kan placera många beställningar; medan en order är placerad av en viss kund. Denna typ av relation är känd som en-till-många.,
en-till-många relation kan inte representeras i en enda tabell. Till exempel, i en ”class roster” – databas kan vi börja med en tabell som heter Teachers, som lagrar information om lärare (till exempel name, office, phone och email). För att lagra klasserna som lärs ut av varje lärare kan vi skapa kolumner class1, class2, class3, men står inför ett problem omedelbart på hur många kolumner som ska skapas., Å andra sidan, om vi börjar med en tabell som heter Classes, som lagrar information om en klass (courseCode, dayOfWeek, timeStart och timeEnd); vi kan skapa ytterligare kolumner för att lagra information om (en) läraren (till exempel name, office, phone och email). Eftersom en lärare kan lära ut många klasser, skulle data dupliceras i många rader i tabell Classes.,
för att stödja ett en-till-många-förhållande måste vi utforma två tabeller: en tabell Classes för att lagra information om klasserna med classID som primärnyckel; och en tabell Teachers för att lagra information om lärare med teacherID som primärnyckel. Vi kan sedan skapa en-till-många relation genom att lagra den primära nyckeln i tabellen Teacher (dvs.,, teacherID) (”one”-end eller modertabellen) i tabellen classes (”many” -end eller underordnade tabellen), som visas nedan.
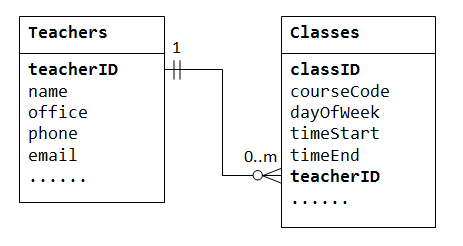
kolumnenteacherID I barntabellenClasses kallas den utländska nyckeln. En främmande nyckel i en underordnad tabell är en primär nyckel i en överordnad tabell som används för att referera till överordnad tabell.
Observera att för varje värde i överordnad tabell kan det finnas noll, en eller flera rader i underordnad tabell., För varje värde i underordnade tabellen finns en och endast en rad i överordnade tabellen.
många till många
i en ”produktförsäljning”-databas kan en kunds order innehålla en eller flera produkter; och en produkt kan visas i många beställningar. I en” bokhandel ” – databas skrivs en bok av en eller flera författare; medan en författare kan skriva noll eller flera böcker. Denna typ av relation är känd som många till många.
låt oss illustrera med en ”produktförsäljning” – databas. Vi börjar med två tabeller: Products och Orders., Tabellen productsinnehåller information om produkterna (somname,descriptionochquantityInStock) medproductID som huvudnyckel. Tabellenorders innehåller kundens order (customerID,dateOrdered,dateRequired ochstatus). Återigen kan vi inte lagra de objekt som beställts i tabellenOrders, eftersom vi inte vet hur många kolumner som ska reserveras för objekten., Vi kan inte heller lagra orderinformationen i tabellen Products.
för att stödja många-till-många relationer måste vi skapa en tredje tabell (känd som en korsningstabell), säg OrderDetails (eller OrderLines), där varje rad representerar ett objekt av en viss ordning. För tabellenOrderDetails består huvudnyckeln av två kolumner: orderIDochproductID, som unikt identifierar varje rad., Kolumnerna orderID och productID I OrderDetails tabellen används för att referera Orders och Products tabeller, därav, de är också de utländska nycklarna i tabellen OrderDetails 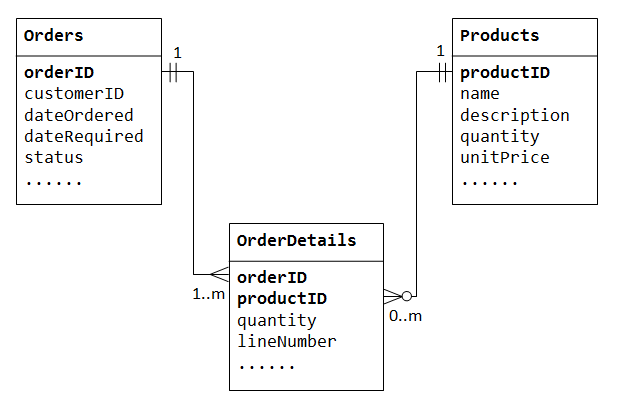
förhållandet mellan många och många är faktiskt implementerat som två en-till-många relationer, med införandet av korstabellen.
- en order har många objekt i
OrderDetails. EttOrderDetails– objekt tillhör en viss order., - en produkt kan visas i många
OrderDetails. VarjeOrderDetails– post specificerade en produkt.
One-to-One
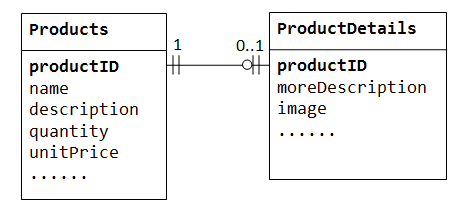
i en ”product sales” – databas kan en produkt ha kompletterande information somimage,moreDescription ochcomment. Att hålla dem inne i tabellenProducts resulterar i många tomma utrymmen (i dessa poster utan dessa valfria data). Dessutom kan dessa stora data försämra databasens prestanda.,
istället kan vi skapa en annan tabell (sägProductDetails,ProductLines ellerProductExtras) för att lagra valfria data. En post skapas endast för dessa produkter med valfria data. De två tabellerna,Products ochProductDetails, uppvisar ett förhållande mellan en och en. Det vill säga för varje rad i moderbordet finns det högst en rad (eventuellt noll) i barnbordet. Samma kolumnproductID ska användas som primärnyckel för båda tabellerna.,
vissa databaser begränsar antalet kolumner som kan skapas i en tabell. Du kan använda en en-till-en relation för att dela upp data i två tabeller. Ett-till-ett-förhållande är också användbart för att lagra vissa känsliga data i en säker tabell, medan de icke-känsliga i huvudtabellen.
Kolumndatatyper
Du måste välja en lämplig datatyp för varje kolumn. Vanliga datatyper inkluderar: heltal, flyttal, sträng (eller text), datum/tid, binär, samling (t.ex. uppräkning och uppsättning).,
steg 4: förfina& normalisera designen
till exempel
- lägga till fler kolumner,
- skapa en ny tabell för valfria data med en-till-en-relation,
- dela ett stort bord i två mindre tabeller,
- andra.
normalisering
tillämpa de så kallade normaliseringsreglerna för att kontrollera om din databas är strukturellt korrekt och optimal.
första normala formen (1NF): en tabell är 1NF om varje cell innehåller ett enda värde, inte en lista med värden. Dessa egenskaper är kända som atomic., 1NF förbjuder också upprepande grupp av kolumner som item1, item2.., itemN. Istället bör du skapa en annan tabell med hjälp av en-till-många relation.
andra normala Form (2NF): en tabell är 2NF, om den är 1NF och varje icke-nyckelkolumn är helt beroende av primärnyckeln. Om huvudnyckeln består av flera kolumner ska dessutom varje icke-nyckelkolumn bero på hela uppsättningen och inte en del av den.,
till exempel huvudnyckeln för tabellen OrderDetails som innehåller orderID och productID. OmunitPrice endast är beroende avproductID ska det inte hållas i tabellenOrderDetails (men i tabellenProducts). Å andra sidan, omunitPrice är beroende av produkten såväl som den särskilda ordningen, ska den behållas i tabellenOrderDetails.,
tredje normala formen (3NF): en tabell är 3NF, om det är 2NF och icke-nyckel kolumner är oberoende av varandra. Med andra ord är icke-nyckelkolumnerna beroende av primärnyckel, endast på primärnyckeln och inget annat. Anta till exempel att vi har en Products tabell med kolumner productID (primärnyckel), name och unitPrice., Kolumnen discountRateska inte tillhöra tabellen Productsom den också är beroende av tabellen unitPrice, som inte ingår i primärnyckeln.
Högre Normal Form: 3NF har sina brister, vilket leder till högre Normal form, såsom Boyce/Codd Normal form, Fjärde normalformen (4NF) och Femte Normal Form (5NF), som ligger utanför den här handledningens omfattning.
Ibland kan du välja att bryta några av normaliseringsreglerna, av prestandaskäl (t. ex.,, skapa en kolumn som hetertotalPrice IOrders tabell som kan härledas frånorderDetails poster); eller eftersom slutanvändaren begärt det. Se till att du är fullt medveten om det, utveckla programmeringslogik för att hantera det och dokumentera beslutet korrekt.
Integritetsregler
Du bör också tillämpa integritetsreglerna för att kontrollera integriteten för din design:
Entitetsintegritetsregel: den primära nyckeln kan inte innehålla NULL. Annars kan den inte unikt identifiera raden., För sammansatt nyckel består av flera kolumner, ingen av kolumnen kan innehålla NULL. De flesta av RDBMS kontrollera och verkställa denna regel.
Referensintegritetsregel: varje främmande nyckelvärde måste matchas med ett primärt nyckelvärde i tabellen som refereras (eller överordnad tabell).
- Du kan bara infoga en rad med en främmande nyckel i underordnade tabellen om värdet finns i överordnade tabellen.
- om värdet på nyckeln ändras i överordnad tabell (t.ex. raden Uppdaterad eller raderad), måste alla rader med denna främmande nyckel i underordnad tabell(er) hanteras i enlighet med detta., Du kan antingen (a) inte tillåta ändringarna; (b) kaskadera ändringen (eller ta bort posterna) i underordnade tabeller i enlighet därmed; (C) ange nyckelvärdet i underordnade tabeller till NULL.
de flesta RDBMS kan ställas in för att utföra kontrollen och säkerställa referensintegriteten på det angivna sättet.
Affärslogikens integritet: förutom ovanstående två allmänna Integritetsregler kan det finnas integritet (validering) som hänför sig till affärslogiken, t. ex.,, Postnummer skall vara femsiffrig inom ett visst intervall, leveransdatum och tid skall falla i öppettider; beställda kvantitet skall vara lika med eller mindre än kvantitet i lager, etc. Dessa kan utföras i valideringsregel (för den specifika kolumnen) eller programmeringslogik.
Kolumnindexering
Du kan skapa index på markerade kolumner för att underlätta datasökning och hämtning. Ett index är en strukturerad fil som snabbar upp dataåtkomst för SELECT, men kan sakta ner INSERT, UPDATE och DELETE., Utan en indexstruktur, för att bearbeta en SELECT – fråga med ett matchande kriterium (t.ex. SELECT * FROM Customers WHERE name='Tan Ah Teck'), måste databasmotorn jämföra alla poster i tabellen. Ett specialiserat index (t. ex. i btree struktur) kunde nå posten utan att jämföra alla poster. Indexet måste dock byggas om när en post ändras, vilket resulterar i overhead i samband med att man använder index.
Index kan definieras på en enda kolumn, en uppsättning kolumner (kallas sammanlänkat index) eller en del av en kolumn (t. ex.,, första 10 tecken i ettVARCHAR(100)) (kallat partiellt index) . Du kan bygga mer än ett index i en tabell. Om du till exempel ofta söker efter en kund med antingen customerName eller phoneNumber kan du snabba upp sökningen genom att bygga ett index på kolumnen customerName, samt phoneNumber. De flesta RDBMS bygger index på primärnyckeln automatiskt.
referenser & resurser
senaste versionen testad: MySQL 5.5.15
Senast ändrad: September, 2010