Einführung
Relationale Datenbank wurde von Edgar Codd (von IBM Research) um 1969 vorgeschlagen. Es hat sich seitdem zum dominierenden Datenbankmodell für kommerzielle Anwendungen entwickelt (im Vergleich zu anderen Datenbankmodellen wie hierarchischen, Netzwerk-und Objektmodellen). Heute gibt es viele kommerzielles Relationales Datenbank Management System (RDBMS) wie Oracle, IBM DB2 und Microsoft SQL Server., Es gibt auch viele kostenlose und Open-Source-RDBMS wie MySQL, mSQL (Mini-SQL) und das eingebettete JavaDB (Apache Derby).
Eine relationale Datenbank organisiert Daten in Tabellen oder Relationen). Eine Tabelle besteht aus Zeilen und Spalten. Eine Zeile wird auch als Datensatz (oder Tupel) bezeichnet. Eine Spalte wird auch als Feld (oder Attribut) bezeichnet. Eine Datenbanktabelle ähnelt einer Tabelle. Die Beziehungen, die zwischen den Tabellen erstellt werden können, ermöglichen es einer relationalen Datenbank jedoch, große Datenmengen effizient zu speichern und ausgewählte Daten effektiv abzurufen.,
Für die Arbeit mit relationalen Datenbanken wurde eine Sprache namens SQL (Structured Query Language) entwickelt.
Ziel des Datenbankdesigns
Eine gut gestaltete Datenbank muss:
- Datenredundanz beseitigen: Dieselben Daten dürfen nicht an mehr als einem Ort gespeichert werden. Dies liegt daran, dass doppelte Daten nicht nur Speicherplatz verschwenden, sondern auch leicht zu Inkonsistenzen führen.
- Gewährleisten Daten Integrität und Genauigkeit:
- mehr
Relationale Datenbank Design Prozess
Datenbank design ist mehr kunst als wissenschaft, wie sie haben zu machen viele entscheidungen., Datenbanken werden normalerweise an eine bestimmte Anwendung angepasst. Keine zwei angepasste Anwendungen sind gleich, und daher sind keine zwei Datenbank gleich. Richtlinien (in der Regel in Bezug darauf, was nicht zu tun ist, anstatt was zu tun ist) werden bei der Entscheidungsfindung für diese Designentscheidungen bereitgestellt, aber die Entscheidungen beruhen letztendlich auf dem Sie – dem Designer.
Schritt 1: Definieren Sie den Zweck der Datenbank (Anforderungsanalyse)
Erfassen Sie die Anforderungen und definieren Sie das Ziel Ihrer Datenbank, z…
Das Erstellen der Beispieleingabeformulare, Abfragen und Berichte hilft oft.,
Schritt 2: Daten sammeln, in Tabellen organisieren und die Primärschlüssel angeben
Sobald Sie sich für den Zweck der Datenbank entschieden haben, sammeln Sie die Daten, die in der Datenbank gespeichert werden müssen. Teilen Sie die Daten in themenbasierte Tabellen auf.
Wählen Sie eine Spalte (oder einige Spalten) als sogenannten Primärschlüssel, der die einzelnen Zeilen eindeutig identifiziert.
Primärschlüssel
Im relationalen Modell kann eine Tabelle keine doppelten Zeilen enthalten, da dies zu Mehrdeutigkeiten beim Abrufen führen würde., Um die Eindeutigkeit zu gewährleisten, sollte jede Tabelle über eine Spalte (oder eine Reihe von Spalten) verfügen, die als Primärschlüssel bezeichnet wird und alle Datensätze der Tabelle eindeutig identifiziert. Zum Beispiel kann eine eindeutige Nummer customerID als Primärschlüssel für die Customers Tabelle verwendet werden; productCode für Products Tabelle; isbn für Books Tabelle. Ein Primärschlüssel wird als einfacher Schlüssel bezeichnet, wenn es sich um eine einzelne Spalte handelt; es wird zusammengesetzter Schlüssel genannt, wenn es aus mehreren Spalten besteht.,
Die meisten RDBMSs erstellen einen Index für den Primärschlüssel, um das schnelle Suchen und Abrufen zu erleichtern.
Der Primärschlüssel wird auch verwendet, um auf andere Tabellen zu verweisen (die später ausgearbeitet werden sollen).
Sie müssen entscheiden, welche Spalte(n) für den Primärschlüssel verwendet werden soll. Die Entscheidung mag nicht einfach sein, aber der Primärschlüssel muss diese Eigenschaften haben:
- Die Werte des Primärschlüssels müssen eindeutig sein (dh kein doppelter Wert)., Beispielsweise ist
customerNamemöglicherweise nicht geeignet, als Primärschlüssel für die TabelleCustomersverwendet zu werden, da es zwei Kunden mit demselben Namen geben könnte. - Der Primärschlüssel muss immer einen Wert haben. Mit anderen Worten, es darf nicht NULL enthalten.
Beachten Sie bei der Auswahl des Primärschlüssels Folgendes:
- Der Primärschlüssel muss einfach und vertraut sein, z. B.
employeeIDfüremployeesTabelle undisbnfürbooksTabelle., - Der Wert des Primärschlüssels sollte sich nicht ändern. Primärschlüssel wird verwendet, um auf andere Tabellen zu verweisen. Wenn Sie seinen Wert ändern, müssen Sie alle Referenzen ändern; Andernfalls gehen die Referenzen verloren. Beispielsweise ist
phoneNumbermöglicherweise nicht geeignet, als Primärschlüssel für die TabelleCustomersverwendet zu werden, da dies sich möglicherweise ändert. - Primärschlüssel verwendet oft Integer (oder Zahl) Typ. Es könnten aber auch andere Arten sein, wie Texte. Es ist jedoch am besten, numerische Spalte als Primärschlüssel für die Effizienz zu verwenden.
- Primärschlüssel könnte eine beliebige Zahl annehmen., Die meisten RDBMSs unterstützen das sogenannte Auto-Increment (oder
AutoNumbertype) für den ganzzahligen Primärschlüssel, wobei dem neuen Datensatz (aktueller Maximalwert + 1) zugewiesen wird. Diese willkürliche Zahl ist faktenlos, da sie keine sachlichen Informationen enthält. Im Gegensatz zu Sachinformationen wie Telefonnummer, faktenlose Nummer ist ideal für Primärschlüssel, da es sich nicht ändert. - Primärschlüssel ist normalerweise eine einzelne Spalte (z. B.
customerIDoderproductCode). Es könnte aber auch aus mehreren Spalten bestehen. Sie sollten so wenige Spalten wie möglich verwenden.,
Let’s illustrate with an example: a table customers contains columns lastName, firstName, phoneNumber, address, city, state, zipCode. The candidates for primary key are name=(lastName, firstName), phoneNumber, Address1=(address, city, state), Address1=(address, zipCode). Name may not be unique. Phone number and address may change., Daher ist es besser, eine faktenlose automatische Inkrementnummer, z. B. customerID, als Primärschlüssel zu erstellen.
Schritt 3: Beziehungen zwischen Tabellen erstellen
Eine Datenbank, die aus unabhängigen und nicht verwandten Tabellen besteht, dient wenig Zweck (Sie können stattdessen eine Tabelle verwenden). Die Macht der relationalen Datenbank liegt in der Beziehung, die zwischen Tabellen definiert werden kann. Der wichtigste Aspekt beim Entwerfen einer relationalen Datenbank besteht darin, die Beziehungen zwischen Tabellen zu identifizieren., Die Beziehungstypen umfassen:
- eins-zu-viele
- viele-zu-viele
- eins-zu-eins
Eins-zu-Viele
In einer „Klassenliste“ – Datenbank kann ein Lehrer null oder mehr Klassen unterrichten, während eine Klasse von einem (und nur einem) Lehrer unterrichtet wird. In einer“ Unternehmensdatenbank “ verwaltet ein Manager null oder mehr Mitarbeiter, während ein Mitarbeiter von einem (und nur einem) Manager verwaltet wird. In einer“ Produktverkaufsdatenbank “ kann ein Kunde viele Bestellungen aufgeben; während eine Bestellung von einem bestimmten Kunden aufgegeben wird. Diese Art von Beziehung ist als Eins-zu-viele bekannt.,
Eine Eins-zu-Viele-Beziehung kann nicht in einer einzigen Tabelle dargestellt werden. In einer „Klassenliste“ – Datenbank können wir beispielsweise mit einer Tabelle mit dem Namen Teachers beginnen, in der Informationen zu Lehrern gespeichert werden (z. B. name, office, phone und email). Um die von jedem Lehrer gelehrten Klassen zu speichern, können wir Spalten erstellen class1, class2, class3, hat jedoch sofort ein Problem damit, wie viele Spalten erstellt werden sollen., Wenn wir andererseits mit einer Tabelle mit dem Namen Classes beginnen, in der Informationen zu einer Klasse gespeichert sind (courseCode, dayOfWeek, timeStart und timeEnd); Wir könnten zusätzliche Spalten erstellen, um Informationen über den (einen) Lehrer zu speichern (z. als name, office, phone und email). Da ein Lehrer jedoch viele Klassen unterrichten kann, werden seine Daten in vielen Zeilen in der Tabelle Classesdupliziert.,
Um eine Eins-zu-Viele-Beziehung zu unterstützen, müssen wir zwei Tabellen entwerfen: eine Tabelle Classes zum Speichern von Informationen über die Klassen mit classID als Primärschlüssel; und eine Tabelle Teachers zum Speichern von Informationen über Lehrer mit teacherID als Primärschlüssel. Wir können dann die Eins-zu-Viele-Beziehung erstellen, indem wir den Primärschlüssel der Tabelle Teacher (dh,, teacherID) (das“eine“-Ende oder die übergeordnete Tabelle) in der Tabelle classes (das“viele“ -Ende oder die untergeordnete Tabelle), wie unten dargestellt.
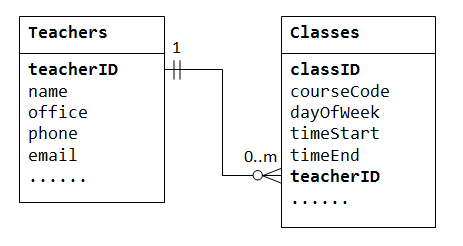
Die Spalte teacherID in der untergeordneten Tabelle Classes wird als Fremdschlüssel bezeichnet. Ein Fremdschlüssel einer untergeordneten Tabelle ist ein Primärschlüssel einer übergeordneten Tabelle, der zum Verweisen auf die übergeordnete Tabelle verwendet wird.
Beachten Sie, dass für jeden Wert in der übergeordneten Tabelle Null, eine oder mehrere Zeilen in der untergeordneten Tabelle vorhanden sein können., Für jeden Wert in der untergeordneten Tabelle gibt es eine und nur eine Zeile in der übergeordneten Tabelle.
Viele-zu-Viele
In einer „Produktverkaufsdatenbank“ kann die Bestellung eines Kunden ein oder mehrere Produkte enthalten; und ein Produkt kann in vielen Bestellungen erscheinen. In einer“ Buchhandlung “ – Datenbank wird ein Buch von einem oder mehreren Autoren geschrieben; während ein Autor null oder mehr Bücher schreiben kann. Diese Art von Beziehung ist als Viele-zu-Viele bekannt.
Veranschaulichen wir mit einer“ Product Sales “ – Datenbank. Wir beginnen mit zwei Tabellen: Products und Orders., Die Tabelle products enthält Informationen zu den Produkten (z. B. name, description und quantityInStock) mit productID als Primärschlüssel. Die Tabelle orders enthält Kundenaufträge (customerID, dateOrdered, dateRequired und status). Auch hier können wir die bestellten Elemente nicht in der Tabelle Orders speichern, da wir nicht wissen, wie viele Spalten für die Elemente reserviert werden sollen., Wir können die Bestellinformationen auch nicht in der Tabelle Products speichern.
Um eine Many-to-Many-Beziehung zu unterstützen, müssen wir eine dritte Tabelle (bekannt als Junction-Tabelle) erstellen, z. B. OrderDetails (oder OrderLines), wobei jede Zeile ein Element einer bestimmten Reihenfolge darstellt. Für die Tabelle OrderDetails besteht der Primärschlüssel aus zwei Spalten: orderID und productID, die jede Zeile eindeutig identifizieren., Die Spalten orderID und productID in OrderDetails Tabelle werden verwendet, um auf Orders und Products Tabellen zu verweisen, daher sind sie auch die Fremdschlüssel in der OrderDetails Tabelle.
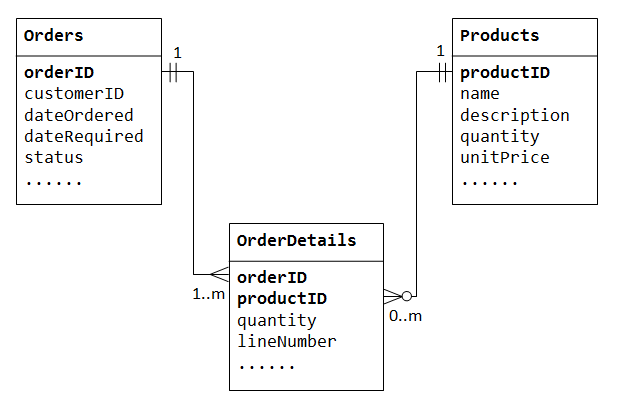
Die many-to-Many-Beziehung wird mit der Einführung der Junction-Tabelle tatsächlich als zwei Eins-zu-Viele-Beziehungen implementiert.
- Eine Bestellung enthält viele Elemente in
OrderDetails. EinOrderDetails– Element gehört zu einer bestimmten Reihenfolge., - Ein Produkt kann in vielen
OrderDetails. JedesOrderDetails– Element hat ein Produkt angegeben.
Eins zu eins
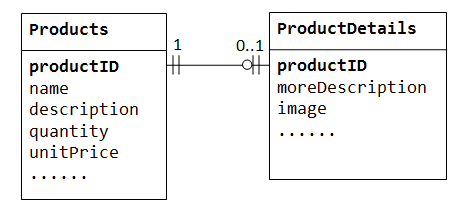
In einer“ product sales“ – Datenbank kann ein Produkt optionale Zusatzinformationen wie image, moreDescription und commententhalten. Wenn Sie sie in der Products Tabelle Products, werden viele leere Leerzeichen angezeigt (in diesen Datensätzen ohne diese optionalen Daten). Darüber hinaus können diese großen Daten die Leistung der Datenbank beeinträchtigen.,
Stattdessen können wir eine andere Tabelle erstellen (z. B. ProductDetails, ProductLines oder ProductExtras), um die optionalen Daten zu speichern. Ein Datensatz wird nur für diese Produkte mit optionalen Daten erstellt. Die beiden Tabellen, Products und ProductDetails, weisen eine eins-zu-eins-Beziehung. Das heißt, für jede Zeile in der übergeordneten Tabelle gibt es höchstens eine Zeile (möglicherweise Null) in der untergeordneten Tabelle. Dieselbe Spalte productID sollte als Primärschlüssel für beide Tabellen verwendet werden.,
Einige Datenbanken begrenzen die Anzahl der Spalten, die innerhalb einer Tabelle erstellt werden können. Sie können eine Eins-zu-Eins-Beziehung verwenden, um die Daten in zwei Tabellen aufzuteilen. Eine Eins-zu-Eins-Beziehung ist auch nützlich, um bestimmte vertrauliche Daten in einer sicheren Tabelle zu speichern, während die nicht vertraulichen in der Haupttabelle.
Spaltendatentypen
Sie müssen für jede Spalte einen geeigneten Datentyp auswählen. Häufig Datentypen umfassen: Ganzzahlen, Gleitkommazahlen, String (oder Text), Datum/Uhrzeit, Binär, Sammlung (wie Aufzählung und Satz).,
Schritt 4: verfeinern & Normalisieren Design
Beispiel:
- hinzufügen weiterer Spalten,
- erstellen einer neuen Tabelle für optionale Daten mit eins-zu-eins-Beziehung,
- split eine große Tabelle in zwei kleineren Tabellen,
- andere.
Normalisierung
Wenden Sie die sogenannten Normalisierungsregeln an, um zu überprüfen, ob Ihre Datenbank strukturell korrekt und optimal ist.
Erste Normalform (1NF): Eine Tabelle ist 1NF, wenn jede Zelle einen einzelnen Wert enthält, keine Liste von Werten. Diese Eigenschaft wird als atomar bezeichnet., 1NF verbietet auch wiederholte Gruppe von Spalten wie item1, item2,.., itemN. Stattdessen sollten Sie eine andere Tabelle mit einer Eins-zu-Viele-Beziehung erstellen.
Zweite Normalform (2NF): Eine Tabelle ist 2NF, wenn sie 1NF ist und jede Nichtschlüsselspalte vollständig vom Primärschlüssel abhängig ist. Wenn der Primärschlüssel aus mehreren Spalten besteht, hängt jede Nichtschlüsselspalte vom gesamten Satz und nicht von einem Teil davon ab.,
Zum Beispiel der Primärschlüssel der OrderDetails – Tabelle, bestehend aus orderID und productID. Wenn unitPrice ist nur abhängig von productID, es darf nicht gehalten werden in die OrderDetails Tabelle (aber in der Products Tabelle). Wenn andererseits die unitPrice sowohl vom Produkt als auch von der jeweiligen Reihenfolge abhängt, wird sie in der Tabelle OrderDetails gespeichert.,
Dritte Normalform (3NF): Eine Tabelle ist 3NF, wenn sie 2NF ist und die Nichtschlüsselspalten unabhängig voneinander sind. Mit anderen Worten, die Nichtschlüsselspalten sind vom Primärschlüssel abhängig, nur vom Primärschlüssel und sonst nichts. Angenommen, wir haben eineProducts – Tabelle mit den SpaltenproductID (Primärschlüssel),name undunitPrice., Die Spalte discountRate gehört nicht zur Products – Tabelle, wenn sie auch von der unitPrice abhängt, die nicht Teil des Primärschlüssels ist.
Höhere Normalform: 3NF hat seine Unzulänglichkeiten, was zu einer höheren Normalform führt, wie Boyce / Codd Normalform, Vierte Normalform (4NF) und fünfte Normalform (5NF), die über den Rahmen dieses Tutorials hinausgeht.
Manchmal können Sie aus Leistungsgründen einige der Normalisierungsregeln brechen (z.,, erstellen Sie eine Spalte mit dem Namen totalPrice in Orders Tabelle, die aus den orderDetails Datensätzen abgeleitet werden kann); oder weil der Endbenutzer danach angefordert hat. Stellen Sie sicher, dass Sie sich dessen bewusst sind, entwickeln Sie eine Programmierlogik, um damit umzugehen, und dokumentieren Sie die Entscheidung ordnungsgemäß.
Integritätsregeln
Sie sollten auch die Integritätsregeln anwenden, um die Integrität Ihres Designs zu überprüfen:
Entitätsintegritätsregel: Der Primärschlüssel kann nicht NULL enthalten. Andernfalls kann die Zeile nicht eindeutig identifiziert werden., Bei zusammengesetzten Schlüsseln, die aus mehreren Spalten bestehen, kann keine der Spalten NULL enthalten. Die meisten RDBMS überprüfen und erzwingen diese Regel.
Referenzielle Integritätsregel: Jeder Fremdschlüsselwert muss mit einem Primärschlüsselwert in der referenzierten Tabelle (oder übergeordneten Tabelle) übereinstimmen.
- Sie können eine Zeile mit einem Fremdschlüssel nur dann in die untergeordnete Tabelle einfügen, wenn der Wert in der übergeordneten Tabelle vorhanden ist.
- Wenn sich der Wert des Schlüssels in der übergeordneten Tabelle ändert(z. B. die Zeile aktualisiert oder gelöscht), müssen alle Zeilen mit diesem Fremdschlüssel in den untergeordneten Tabellen entsprechend behandelt werden., Sie können entweder (a) die Änderungen nicht zulassen; (b) die Änderung kaskadieren (oder die Datensätze löschen) in den untergeordneten Tabellen entsprechend; (c) den Schlüsselwert in den untergeordneten Tabellen auf NULL setzen.
Die meisten RDBMS können eingerichtet werden, um die Überprüfung durchzuführen und die referenzielle Integrität auf die angegebene Weise sicherzustellen.
Integrität der Geschäftslogik: Neben den beiden oben genannten allgemeinen Integritätsregeln kann es zur Integrität (Validierung) der Geschäftslogik kommen, z.,, postleitzahl ist 5-stellige innerhalb einer bestimmten bereiche, lieferung datum und zeit wird fallen in die business stunden; menge bestellt werden gleich oder weniger als menge auf lager, etc. Diese können in der Validierungsregel (für die jeweilige Spalte) oder in der Programmierlogik ausgeführt werden.
Spaltenindizierung
Sie können einen Index für ausgewählte Spalten erstellen, um das Suchen und Abrufen von Daten zu erleichtern. Ein Index ist eine strukturierte Datei, die den Datenzugriff für SELECT beschleunigt, aber INSERT, UPDATE und DELETEverlangsamen kann., Ohne Indexstruktur muss das Datenbankmodul alle Datensätze in der Tabelle vergleichen, um eine SELECT – Abfrage mit einem übereinstimmenden Kriterium (z. B. SELECT * FROM Customers WHERE name='Tan Ah Teck') zu verarbeiten. Ein spezieller Index (z. B. in der BTREE-Struktur) könnte den Datensatz erreichen, ohne alle Datensätze zu vergleichen. Der Index muss jedoch bei jeder Änderung eines Datensatzes neu erstellt werden, was zu einem Overhead führt, der mit der Verwendung von Indizes verbunden ist.
Der Index kann für eine einzelne Spalte, einen Satz von Spalten (verketteter Index) oder einen Teil einer Spalte (z.,, erste 10 Zeichen einer VARCHAR(100)) (Teilindex genannt). Sie können mehr als einen Index in einer Tabelle erstellen. Wenn Sie beispielsweise häufig mit customerName oder phoneNumber nach einem Kunden suchen, können Sie die Suche beschleunigen, indem Sie einen Index für die Spalte customerName sowie phoneNumber. Die meisten RDBMS erstellt Index auf dem Primärschlüssel automatisch.
REFERENZEN & RESSOURCEN
die Letzte getestete version: MySQL 5.5.15
Last modified: September, 2010