Introduzione
Database relazionale è stato proposto da Edgar Codd (di IBM Research) intorno al 1969. Da allora è diventato il modello di database dominante per le applicazioni commerciali (rispetto ad altri modelli di database come modelli gerarchici, di rete e di oggetti). Oggi, ci sono molti commercial Relational Database Management System (RDBMS), come Oracle, IBM DB2 e Microsoft SQL Server., Ci sono anche molti RDBM gratuiti e open source, come MySQL, mSQL (mini-SQL) e il JavaDB incorporato (Apache Derby).
Un database relazionale organizza i dati in tabelle (o relazioni). Una tabella è composta da righe e colonne. Una riga è anche chiamata record (o tupla). Una colonna è anche chiamata campo (o attributo). Una tabella di database è simile a un foglio di calcolo. Tuttavia, le relazioni che possono essere create tra le tabelle consentono a un database relazionale di archiviare in modo efficiente un’enorme quantità di dati e recuperare efficacemente i dati selezionati.,
Un linguaggio chiamato SQL (Structured Query Language) è stato sviluppato per lavorare con database relazionali.
Obiettivo di progettazione del database
Un database ben progettato deve:
- Eliminare la ridondanza dei dati: lo stesso pezzo di dati non deve essere memorizzato in più di un luogo. Questo perché i dati duplicati non solo gli spazi di archiviazione dei rifiuti, ma anche facilmente portare a incongruenze.
- Garantire l’integrità dei dati e la precisione:
- più
Relazionale Processo di progettazione di database
Progettazione di database è più arte che scienza, come si deve prendere molte decisioni., I database sono solitamente personalizzati per soddisfare una particolare applicazione. Non ci sono due applicazioni personalizzate sono uguali, e quindi, non ci sono due database sono uguali. Le linee guida (di solito in termini di cosa non fare invece di cosa fare) sono fornite nel prendere queste decisioni di progettazione, ma le scelte alla fine dipendono dal tu – il designer.
Passo 1: Definire lo scopo del database (Analisi dei requisiti)
Raccogliere i requisiti e definire l’obiettivo del database, ad esempio …
La stesura dei moduli di input di esempio, delle query e dei report, spesso aiuta.,
Passo 2: Raccogliere i dati, organizzare in tabelle e specificare le chiavi primarie
Una volta deciso lo scopo del database, raccogliere i dati che sono necessari per essere memorizzati nel database. Dividere i dati in tabelle basate sull’argomento.
Scegli una colonna (o alcune colonne) come la cosiddetta chiave primaria, che identifica in modo univoco ciascuna delle righe.
Chiave primaria
Nel modello relazionale, una tabella non può contenere righe duplicate, perché ciò creerebbe ambiguità nel recupero., Per garantire l’unicità, ogni tabella deve avere una colonna (o un insieme di colonne), chiamata chiave primaria, che identifica in modo univoco tutti i record della tabella. Per esempio, un numero unico tag customerID può essere utilizzato come chiave primaria per il Customers tabella productCode per Products tabella isbn per Books tabella. Una chiave primaria è chiamata chiave semplice se è una singola colonna; è chiamata chiave composita se è composta da più colonne.,
La maggior parte degli RDBMS crea un indice sulla chiave primaria per facilitare la ricerca e il recupero veloci.
La chiave primaria viene utilizzata anche per fare riferimento ad altre tabelle (da elaborare in seguito).
Devi decidere quali colonne devono essere utilizzate per la chiave primaria. La decisione può non essere semplice, ma la chiave primaria deve avere queste proprietà:
- I valori della chiave primaria devono essere unici (cioè nessun valore duplicato)., Ad esempio,
customerNamepotrebbe non essere appropriato per essere utilizzato come chiave primaria per la tabellaCustomers, poiché potrebbero esserci due clienti con lo stesso nome. - La chiave primaria deve sempre avere un valore. In altre parole, non deve contenere NULL.
prendere in Considerazione i seguenti nel scegliere la chiave primaria:
- La chiave primaria deve essere semplice e familiare, ad esempio,
employeeIDperemployeestabella eisbnperbookstabella., - Il valore della chiave primaria non deve cambiare. La chiave primaria viene utilizzata per fare riferimento ad altre tabelle. Se si modifica il suo valore, è necessario modificare tutti i suoi riferimenti; in caso contrario, i riferimenti andranno persi. Ad esempio,
phoneNumberpotrebbe non essere appropriato per essere utilizzato come chiave primaria per la tabellaCustomers, perché potrebbe cambiare. - La chiave primaria spesso utilizza il tipo integer (o number). Ma potrebbe anche essere altri tipi, come i testi. Tuttavia, è meglio usare la colonna numerica come chiave primaria per l’efficienza.
- Chiave primaria potrebbe prendere un numero arbitrario., La maggior parte degli RDBMS supporta il cosiddetto auto-incremento (o
AutoNumbertipo) per la chiave primaria intera, dove (valore massimo corrente + 1) è assegnato al nuovo record. Questo numero arbitrario è privo di fatti, in quanto non contiene informazioni fattuali. A differenza delle informazioni fattuali come il numero di telefono, il numero fact-less è l’ideale per la chiave primaria, in quanto non cambia. - La chiave primaria è solitamente una singola colonna (ad esempio,
customerIDoproductCode). Ma potrebbe anche essere costituito da diverse colonne. Dovresti usare il minor numero possibile di colonne.,
Let’s illustrate with an example: a table customers contains columns lastName, firstName, phoneNumber, address, city, state, zipCode. The candidates for primary key are name=(lastName, firstName), phoneNumber, Address1=(address, city, state), Address1=(address, zipCode). Name may not be unique. Phone number and address may change., Quindi, è meglio creare un numero di auto-incremento senza fatti, ad esempio customerID, come chiave primaria.
Passo 3: Creare relazioni tra tabelle
Un database costituito da tabelle indipendenti e non correlate serve a poco (si può considerare di utilizzare un foglio di calcolo invece). La potenza del database relazionale risiede nella relazione che può essere definita tra le tabelle. L’aspetto più cruciale nella progettazione di un database relazionale è quello di identificare le relazioni tra le tabelle., I tipi di relazione includono:
- one-to-many
- many-to-many
- one-to-one
One-to-Many
In un database “class roster”, un insegnante può insegnare zero o più classi, mentre una classe è insegnata da un (e solo un) insegnante. In un database “azienda”, un manager gestisce zero o più dipendenti, mentre un dipendente è gestito da uno (e solo uno) manager. In un database “vendite di prodotti”, un cliente può effettuare molti ordini; mentre un ordine viene effettuato da un particolare cliente. Questo tipo di rapporto è noto come uno-a-molti.,
La relazione uno-a-molti non può essere rappresentata in una singola tabella. Ad esempio, in un database “class roster”, possiamo iniziare con una tabella chiamata Teachers, che memorizza informazioni sugli insegnanti (ad esempio name, office, phone e email). Per memorizzare le classi insegnate da ciascun insegnante, potremmo creare colonne class1, class2, class3, ma affronta immediatamente un problema su quante colonne creare., D’altra parte, se si inizia con una tabella denominata Classes che contiene informazioni su una classe (courseCode dayOfWeek timeStart e timeEnd); si potrebbe creare colonne aggiuntive per memorizzare informazioni sull’ (uno) insegnante (ad esempio name office phone e email). Tuttavia, poiché un insegnante può insegnare molte classi, i suoi dati verrebbero duplicati in molte righe nella tabella Classes.,
Per sostenere un uno-a-molti rapporti, abbiamo bisogno di due tabelle: una tabella Classes per memorizzare le informazioni sulle classi con classID come chiave primaria; e una tabella Teachers per memorizzare le informazioni sugli insegnanti con teacherID come chiave primaria. Possiamo quindi creare la relazione uno-a-molti memorizzando la chiave primaria della tabella Teacher (cioè,, teacherID) (l’estremità”uno”o la tabella genitore) nella tabella classes (l’estremità”molti” o la tabella figlio), come illustrato di seguito.
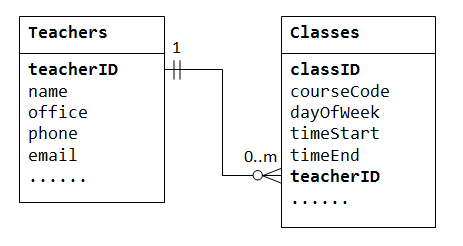
La colonnateacherIDnella tabella figlioClasses è nota come chiave esterna. Una chiave esterna di una tabella figlio è una chiave primaria di una tabella padre, utilizzata per fare riferimento alla tabella padre.
Prendi nota che per ogni valore nella tabella padre, potrebbero esserci zero, una o più righe nella tabella figlio., Per ogni valore nella tabella figlio, c’è una e una sola riga nella tabella padre.
Molti-a-molti
In un database “vendite di prodotti”, l’ordine di un cliente può contenere uno o più prodotti; e un prodotto può apparire in molti ordini. In un database “bookstore”, un libro è scritto da uno o più autori; mentre un autore può scrivere zero o più libri. Questo tipo di rapporto è noto come molti-a-molti.
Illustriamo con un database “vendite di prodotti”. Iniziamo con due tabelle: ProductseOrders., La tabella products contiene informazioni sui prodotti (ad esempio name description e quantityInStock con productID come chiave primaria. La tabella orders contiene ordini del cliente (customerID dateOrdered dateRequired e status). Ancora una volta, non possiamo memorizzare gli articoli ordinati all’interno della tabella Orders, poiché non sappiamo quante colonne riservare per gli articoli., Inoltre, non è possibile memorizzare le informazioni sull’ordine nella tabellaProducts.
Per supportare la relazione molti-a-molti, dobbiamo creare una terza tabella (nota come tabella di giunzione), ad esempio OrderDetails(o OrderLines), in cui ogni riga rappresenta un elemento di un ordine particolare. Per la tabellaOrderDetails, la chiave primaria è composta da due colonne:orderID eproductID, che identificano in modo univoco ogni riga., Le colonne orderID e productID nel OrderDetails tabella sono utilizzati per fare riferimento a Orders e Products tabelle, quindi, sono anche le chiavi esterne OrderDetails tabella.
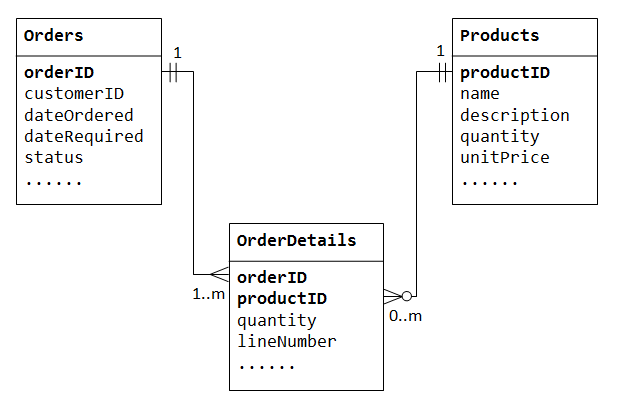
La relazione molti-a-molti è, infatti, implementata come due relazioni uno-a-molti, con l’introduzione della tabella di giunzione.
- Un ordine ha molti elementi in
OrderDetails. Un articoloOrderDetailsappartiene a un ordine particolare., - Un prodotto può apparire in molti
OrderDetails. Ogni articoloOrderDetailsha specificato un prodotto.
One-to-One
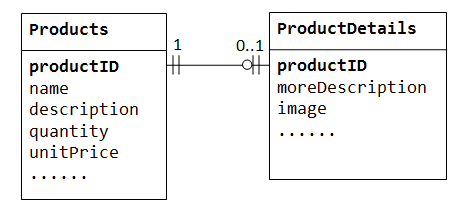
In un database “product sales”, un prodotto può avere informazioni supplementari opzionali comeimage,moreDescription ecomment. Mantenendoli all’interno della tabella Products si ottengono molti spazi vuoti (in quei record senza questi dati opzionali). Inoltre, questi dati di grandi dimensioni possono degradare le prestazioni del database.,
Invece, possiamo creare un’altra tabella (ad esempio ProductDetails, ProductLines o ProductExtras) per memorizzare i dati opzionali. Verrà creato un record solo per quei prodotti con dati facoltativi. Le due tabelle,Products eProductDetails, presentano una relazione uno-a-uno. Cioè, per ogni riga nella tabella genitore, c’è al massimo una riga (possibilmente zero) nella tabella figlio. La stessa colonna productID deve essere utilizzata come chiave primaria per entrambe le tabelle.,
Alcuni database limitano il numero di colonne che possono essere create all’interno di una tabella. È possibile utilizzare una relazione uno a uno per dividere i dati in due tabelle. La relazione one-to-one è utile anche per memorizzare alcuni dati sensibili in una tabella sicura, mentre quelli non sensibili nella tabella principale.
Tipi di dati di colonna
È necessario scegliere un tipo di dati appropriato per ogni colonna. Comunemente i tipi di dati includono: numeri interi, numeri in virgola mobile, stringa (o testo), data/ora, binario, raccolta (come enumerazione e set).,
Passo 4: Affina& Normalizza il progetto
Ad esempio,
- aggiungendo più colonne,
- crea una nuova tabella per i dati opzionali usando la relazione uno a uno,
- dividi una tabella grande in due tabelle più piccole,
- altri.
Normalizzazione
Applicare le cosiddette regole di normalizzazione per verificare se il database è strutturalmente corretto e ottimale.
Prima forma normale (1NF): una tabella è 1NF se ogni cella contiene un singolo valore, non un elenco di valori. Questa proprietà è nota come atomica., 1NF proibisce anche la ripetizione di gruppi di colonne come item1, item2,.., itemN. Invece, dovresti creare un’altra tabella usando una relazione uno-a-molti.
Seconda forma normale (2NF): una tabella è 2NF, se è 1NF e ogni colonna non chiave dipende completamente dalla chiave primaria. Inoltre, se la chiave primaria è composta da più colonne, ogni colonna non chiave dipende dall’intero insieme e non da parte di esso.,
Ad esempio, la chiave primaria della tabella OrderDetails comprendente orderID e productID. SeunitPrice dipende solo daproductID, non deve essere mantenuto nella tabellaOrderDetails (ma nella tabellaProducts). D’altra parte, se il unitPrice dipende dal prodotto e dall’ordine particolare, deve essere mantenuto nella tabella OrderDetails.,
Terza forma normale (3NF): una tabella è 3NF, se è 2NF e le colonne non chiave sono indipendenti l’una dall’altra. In altre parole, le colonne non chiave dipendono dalla chiave primaria, solo dalla chiave primaria e nient’altro. Ad esempio, supponiamo di avere una tabella Products con colonne productID (chiave primaria), name e unitPrice., La colonnadiscountRate non deve appartenere alla tabellaProducts se dipende anche dalla tabellaunitPrice, che non fa parte della chiave primaria.
Forma normale superiore: 3NF ha le sue inadeguatezze, che portano a una forma normale più alta, come la forma normale Boyce / Codd, la quarta Forma normale (4NF) e la quinta forma normale (5NF), che va oltre lo scopo di questo tutorial.
A volte, si può decidere di rompere alcune delle regole di normalizzazione, per motivi di prestazioni (ad esempio,, crea una colonna chiamatatotalPrice inOrders tabella che può essere derivata daiorderDetails record); o perché l’utente finale lo ha richiesto. Assicurati di esserne pienamente consapevole, sviluppa la logica di programmazione per gestirla e documenta correttamente la decisione.
Regole di integrità
È inoltre necessario applicare le regole di integrità per verificare l’integrità del progetto:
Regola di integrità dell’entità: la chiave primaria non può contenere NULL. In caso contrario, non è possibile identificare in modo univoco la riga., Per la chiave composita composta da più colonne, nessuna colonna può contenere NULL. La maggior parte degli RDBMS controlla e applica questa regola.
Regola di integrità referenziale: ogni valore della chiave esterna deve essere abbinato a un valore della chiave primaria nella tabella a cui si fa riferimento (o nella tabella padre).
- È possibile inserire una riga con una chiave esterna nella tabella figlio solo se il valore esiste nella tabella padre.
- Se il valore della chiave cambia nella tabella padre (ad esempio, la riga aggiornata o eliminata), tutte le righe con questa chiave esterna nelle tabelle figlio devono essere gestite di conseguenza., È possibile (a) disabilitare le modifiche; (b) eseguire in cascata la modifica (o eliminare i record) nelle tabelle figlio di conseguenza; (c) impostare il valore della chiave nelle tabelle figlio su NULL.
La maggior parte degli RDBMS può essere configurata per eseguire il controllo e garantire l’integrità referenziale, nel modo specificato.
Integrità della logica aziendale: oltre alle due regole generali di integrità precedenti, potrebbe esserci integrità (convalida) relativa alla logica aziendale, ad esempio,, codice postale deve essere di 5 cifre entro un certo intervallo, data di consegna e l’ora deve cadere nelle ore di lavoro; quantità ordinata deve essere uguale o inferiore a quantità in magazzino, ecc. Questi potrebbero essere effettuati in regola di convalida (per la colonna specifica) o logica di programmazione.
Indicizzazione delle colonne
È possibile creare un indice sulle colonne selezionate per facilitare la ricerca e il recupero dei dati. Un indice è un file strutturato che velocizza l’accesso ai dati per SELECT, ma può rallentare INSERT, UPDATE e DELETE., Senza una struttura di indice, per elaborare una query SELECT con un criterio corrispondente (ad esempio, SELECT * FROM Customers WHERE name='Tan Ah Teck'), il motore di database deve confrontare tutti i record nella tabella. Un indice specializzato (ad esempio, nella struttura BTREE) potrebbe raggiungere il record senza confrontare tutti i record. Tuttavia, l’indice deve essere ricostruito ogni volta che viene modificato un record, il che comporta un sovraccarico associato all’utilizzo degli indici.
L’indice può essere definito su una singola colonna, un insieme di colonne (chiamato indice concatenato) o parte di una colonna (ad esempio,, primi 10 caratteri di unVARCHAR(100)) (chiamato indice parziale) . È possibile creare più di un indice in una tabella. Ad esempio, se si cerca spesso un cliente utilizzando customerName o phoneNumber, è possibile accelerare la ricerca creando un indice sulla colonna customerName, così come phoneNumber. La maggior parte RDBMS costruisce indice sulla chiave primaria automaticamente.
RIFERIMENTI& RISORSE
Ultima versione testata: MySQL 5.5.15
Ultima modifica: settembre, 2010