wprowadzenie
relacyjna baza danych została zaproponowana przez Edgara Codda (IBM Research) około 1969 roku. Od tego czasu stał się dominującym modelem bazodanowym dla aplikacji komercyjnych (w porównaniu z innymi modelami bazodanowymi, takimi jak modele hierarchiczne, sieciowe i obiektowe). Obecnie istnieje wiele komercyjnych systemów zarządzania relacyjnymi bazami danych (RDBMS), takich jak Oracle, IBM DB2 i Microsoft SQL Server., Istnieje również wiele darmowych I open-source RDBMS, takich jak MySQL, mSQL (mini-sql) i wbudowany JavaDB (Apache Derby).
relacyjna baza danych organizuje dane w tabelach (lub relacjach). Tabela składa się z wierszy i kolumn. Wiersz nazywany jest również rekordem (lub krotką). Kolumna jest również nazywana polem (lub atrybutem). Tabela bazy danych jest podobna do arkusza kalkulacyjnego. Jednak relacje, które można utworzyć między tabelami, umożliwiają relacyjnej bazie danych wydajne przechowywanie ogromnych ilości danych i skuteczne pobieranie wybranych danych.,
język o nazwie SQL (Structured Query Language) został opracowany do pracy z relacyjnymi bazami danych.
cel projektowania bazy danych
dobrze zaprojektowana baza danych powinna:
- wyeliminować nadmiarowość danych: ten sam fragment danych nie może być przechowywany w więcej niż jednym miejscu. Dzieje się tak, ponieważ powielanie danych nie tylko miejsca składowania odpadów, ale także łatwo prowadzić do niespójności.
- zapewnienie integralności i dokładności danych:
- więcej
proces projektowania relacyjnych baz danych
projektowanie baz danych jest bardziej sztuką niż nauką, ponieważ trzeba podejmować wiele decyzji., Bazy danych są zwykle dostosowywane do konkretnej aplikacji. Nie ma dwóch dostosowanych aplikacji, a zatem nie ma dwóch takich samych baz danych. Przy podejmowaniu decyzji projektowych przewidziane są wytyczne (zazwyczaj w zakresie tego, czego nie robić zamiast tego, co robić), ale ostatecznie wybory opierają się na Tobie – projektancie.
Krok 1: Zdefiniuj cel bazy danych (Analiza wymagań)
Zbierz wymagania i określ cel bazy danych, np…
opracowywanie przykładowych formularzy wejściowych, zapytań i raportów często pomaga.,
Krok 2: Zbierz dane, Uporządkuj w tabelach i określ klucze podstawowe
po określeniu celu bazy danych Zbierz dane, które mają być przechowywane w bazie danych. Podziel dane na tabele tematyczne.
Wybierz jedną kolumnę (lub kilka kolumn) jako tak zwany klucz podstawowy, który jednoznacznie identyfikuje każdy z wierszy.
klucz podstawowy
w modelu relacyjnym tabela nie może zawierać zduplikowanych wierszy, ponieważ tworzyłoby to niejednoznaczności podczas pobierania., Aby zapewnić unikalność, każda tabela powinna mieć kolumnę (lub zestaw kolumn), zwaną kluczem podstawowym, która jednoznacznie identyfikuje każdy rekord tabeli. Na przykład, unikalny numer customerID może być użyty jako klucz podstawowy dla tabeli Customers; productCode dla tabeli Products; iv id=”247b51ba3e”dla Bookstabela. Klucz podstawowy jest nazywany kluczem prostym, jeśli jest pojedynczą kolumną; jest nazywany kluczem złożonym, jeśli składa się z kilku kolumn.,
Większość RDBMSs buduje indeks na głównym kluczu, aby ułatwić szybkie wyszukiwanie i wyszukiwanie.
klucz podstawowy jest również używany do odwoływania się do innych tabel (do opracowania później).
musisz zdecydować, które kolumny mają być używane dla klucza podstawowego. Decyzja może nie być prosta, ale klucz podstawowy musi mieć następujące właściwości:
- wartości klucza podstawowego muszą być unikalne (tzn. nie ma duplikatów wartości)., Na przykład
customerNamemoże nie być odpowiedni do użycia jako klucz podstawowy dla tabeliCustomers, ponieważ może istnieć dwóch klientów o tej samej nazwie. - klucz podstawowy zawsze ma wartość. Innymi słowy, nie może zawierać NULL.
rozważ następujące czynności w Wybierz klucz podstawowy:
- klucz podstawowy powinien być prosty i znajomy, np.
employeeIDdlaemployeestabela Iisbndlabookstable., - wartość klucza głównego nie powinna się zmieniać. Klucz podstawowy służy do odwoływania się do innych tabel. Jeśli zmienisz jego wartość, musisz zmienić wszystkie jego odniesienia; w przeciwnym razie odniesienia zostaną utracone. Na przykład
phoneNumbermoże nie być odpowiednie do użycia jako klucz podstawowy dla tabeliCustomers, ponieważ może się to zmienić. - klucz podstawowy często używa typu integer (lub number). Ale mogą to być również inne typy, takie jak teksty. Jednak najlepiej jest użyć kolumny numerycznej jako klucza podstawowego dla wydajności.
- klucz podstawowy może przyjmować dowolną liczbę., Większość RDBMSs obsługuje tzw. auto-increment (lub typ
AutoNumber) dla klucza głównego integer, gdzie (aktualna maksymalna wartość + 1) jest przypisana do nowego rekordu. Ta dowolna liczba jest mniej faktyczna, ponieważ nie zawiera żadnych informacji faktycznych. W przeciwieństwie do informacji faktycznych, takich jak numer telefonu, numer bez faktów jest idealny dla klucza podstawowego, ponieważ się nie zmienia. - klucz podstawowy jest zwykle pojedynczą kolumną (np.
customerIDlubproductCode). Ale może również składać się z kilku kolumn. Powinieneś użyć jak największej liczby kolumn.,
Let’s illustrate with an example: a table customers contains columns lastName, firstName, phoneNumber, address, city, state, zipCode. The candidates for primary key are name=(lastName, firstName), phoneNumber, Address1=(address, city, state), Address1=(address, zipCode). Name may not be unique. Phone number and address may change., Dlatego lepiej jest utworzyć mniej faktyczny numer auto-increment, powiedzmy customerID, jako klucz podstawowy.
Krok 3: Tworzenie relacji między tabelami
baza danych składająca się z niezależnych i niepowiązanych tabel nie służy żadnemu celowi (można rozważyć użycie arkusza kalkulacyjnego). Moc relacyjnej bazy danych polega na relacjach, które można zdefiniować między tabelami. Najważniejszym aspektem w projektowaniu relacyjnej bazy danych jest identyfikacja relacji między tabelami., Typy relacji obejmują:
- jeden do wielu
- wiele do wielu
- jeden do jednego
jeden do wielu
w bazie danych „spis klas” nauczyciel może nauczać zero lub więcej klas, podczas gdy klasa jest nauczana przez jednego (i tylko jednego) nauczyciela. W bazie danych” firma ” menedżer zarządza zero lub więcej pracowników, podczas gdy pracownik jest zarządzany przez jednego (i tylko jednego) menedżera. W bazie danych” sprzedaż produktów ” klient może złożyć wiele zamówień, podczas gdy zamówienie składa jeden konkretny klient. Ten rodzaj relacji jest znany jako jeden do wielu.,
relacja jeden do wielu nie może być reprezentowana w jednej tabeli. Na przykład w bazie danych „lista klas” możemy zacząć od tabeli o nazwie Teachers, która przechowuje informacje o nauczycielach (takie jak name, office, phone I email). Aby zapisać zajęcia prowadzone przez każdego nauczyciela, możemy utworzyć kolumny class1, class2, class3, ale od razu pojawia się problem z ilością kolumn do utworzenia., Z drugiej strony, jeśli zaczniemy od tabeli o nazwie Classes, która przechowuje informacje o klasie (courseCode, dayOfWeek, timeStart I timeEnd); możemy utworzyć dodatkowe kolumny do przechowywania informacji o (jednym) Nauczycielu (takich jak name, office, phone I email). Ponieważ jednak nauczyciel może nauczać wielu klas, jego dane będą powielane w wielu wierszach w tabeli Classes.,
aby wspierać relację jeden do wielu, musimy zaprojektować dwie tabele: tabelę Classes do przechowywania informacji o klasach z classID jako kluczem podstawowym; oraz tabelę Teachers do przechowywania informacji o nauczycielach z teacherID jako klucz podstawowy. Następnie możemy utworzyć relację jeden do wielu, przechowując klucz główny tabeli Teacher (tzn.,, teacherID) („one”-koniec lub tabela nadrzędna) w tabeli classes („many”-koniec lub tabela podrzędna), jak pokazano poniżej.
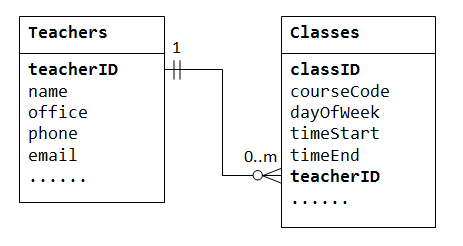
kolumnateacherID w tabeli podrzędnejClasses jest znana jako klucz obcy. Klucz obcy tabeli podrzędnej jest kluczem podstawowym tabeli nadrzędnej, używanym do odwoływania się do tabeli nadrzędnej.
zwróć uwagę, że dla każdej wartości w tabeli nadrzędnej może być zero, jeden lub więcej wierszy w tabeli podrzędnej., Dla każdej wartości w tabeli potomnej w tabeli nadrzędnej jest tylko jeden wiersz.
wiele do wielu
w bazie danych „sprzedaż produktów” zamówienie klienta może zawierać jeden lub więcej produktów, a produkt może pojawić się w wielu zamówieniach. W bazie „księgarni” książka jest napisana przez jednego lub więcej autorów, podczas gdy autor może napisać zero lub więcej książek. Ten rodzaj relacji jest znany jako many-to-many.
zilustrujmy bazę danych „sprzedaż produktów”. Zaczynamy od dwóch tabel: Products I Orders., Tabela products zawiera informacje o produktach (takich jak name, description I quantityInStock) z productID jako klucz podstawowy. Tabela orders zawiera zamówienia klientów (customerID, dateOrdered, dateRequired I status). Ponownie, nie możemy przechowywać zamówionych pozycji wewnątrz tabeli Orders, ponieważ nie wiemy, ile kolumn należy zarezerwować dla tych pozycji., Nie możemy również przechowywać informacji o zamówieniu w tabeli Products.
aby obsługiwać relacje wiele do wielu, musimy utworzyć trzecią tabelę (znaną jako tabela połączeń), powiedzmy OrderDetails(lub OrderLines), gdzie każdy wiersz reprezentuje element określonej kolejności. Dla tabeli OrderDetails klucz podstawowy składa się z dwóch kolumn: orderID I productID, które jednoznacznie identyfikują każdy wiersz., Kolumny orderID I productID w OrderDetails tabela są używane do odwoływania się do Orders I Products tabele, stąd są również klucze obce w tabeli OrderDetails.
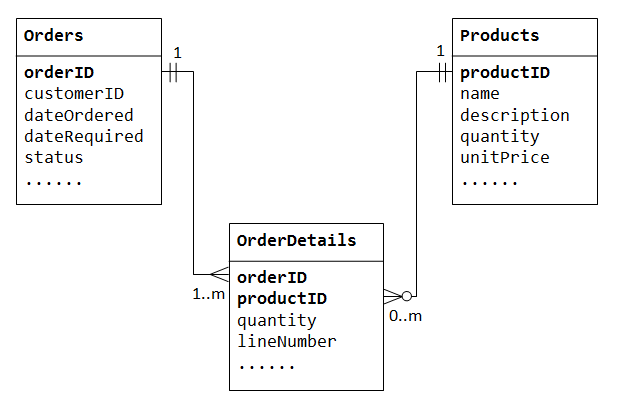
relacja wiele-do-wielu jest w rzeczywistości zaimplementowana jako dwie relacje jeden-do-wielu, wraz z wprowadzeniem tabeli połączeń.
- zamówienie ma wiele pozycji w
OrderDetails. PozycjaOrderDetailsnależy do jednego konkretnego zamówienia., - produkt może pojawić się w wielu
OrderDetails. KażdyOrderDetailselement określony jeden produkt.
jeden do jednego
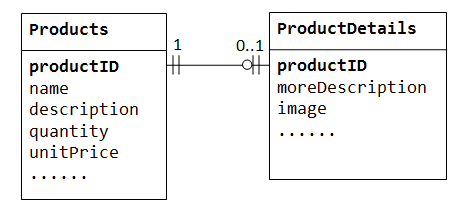
w bazie danych „sprzedaż produktów” produkt może zawierać opcjonalne informacje uzupełniające, takie jakimage,moreDescription Icomment. Trzymanie ich wewnątrz tabeli Products powoduje, że jest wiele pustych miejsc (w tych rekordach bez tych opcjonalnych danych). Ponadto te duże dane mogą pogorszyć wydajność bazy danych.,
zamiast tego możemy utworzyć inną tabelę (powiedzmyProductDetails,ProductLines lub ProductExtras) do przechowywania opcjonalnych danych. Rekord zostanie utworzony tylko dla tych produktów z opcjonalnymi danymi. Dwie tabele, Products I ProductDetails, wykazują związek jeden do jednego. Oznacza to, że dla każdego wiersza w tabeli nadrzędnej w tabeli podrzędnej jest co najwyżej jeden wiersz (ewentualnie zero). Ta sama kolumna productID powinna być używana jako klucz podstawowy dla obu tabel.,
niektóre bazy danych ograniczają liczbę kolumn, które można utworzyć wewnątrz tabeli. Możesz użyć relacji jeden do jednego, aby podzielić dane na dwie tabele. Relacja jeden do jednego jest również przydatna do przechowywania pewnych wrażliwych danych w bezpiecznej tabeli, podczas gdy niewrażliwe w tabeli głównej.
typy danych kolumn
musisz wybrać odpowiedni typ danych dla każdej kolumny. Powszechnie typy danych obejmują: liczby całkowite, liczby zmiennoprzecinkowe, ciąg (lub tekst), datę/czas, binarne, zbiory (takie jak wyliczenie i zestaw).,
Krok 4: udoskonal& normalizacja projektu
na przykład
- dodawanie większej liczby kolumn,
- tworzenie nowej tabeli dla opcjonalnych danych za pomocą relacji jeden-do-jednego,
- podziel dużą tabelę na dwie mniejsze,
- inne.
normalizacja
Zastosuj tak zwane reguły normalizacji, aby sprawdzić, czy Twoja baza danych jest strukturalnie poprawna i optymalna.
pierwsza normalna postać (1NF): tabela ma wartość 1NF, jeśli każda komórka zawiera pojedynczą wartość, a nie listę wartości. Właściwości te są znane jako atomowe., 1NF zabrania również powtarzania grup kolumn, takich jak item1, item2,.., itemN. Zamiast tego należy utworzyć inną tabelę przy użyciu relacji jeden do wielu.
druga normalna postać (2NF): tabela jest 2NF, jeśli jest 1NF i każda kolumna niekluczowa jest w pełni zależna od klucza głównego. Ponadto, Jeżeli klucz podstawowy składa się z kilku kolumn, każda kolumna niekluczowa zależy od całego zbioru, a nie jego części.,
na przykład klucz główny tabeli OrderDetailszawierający orderIDI productID. Jeśli unitPrice jest zależne tylko od productID, nie powinno być przechowywane w tabeliOrderDetails(ale w tabeliProducts). Z drugiej strony, jeśli unitPrice zależy zarówno od produktu, jak i konkretnej kolejności, to należy ją zachować w tabeli OrderDetails.,
trzecia normalna postać (3NF): tabela jest 3NF, jeśli jest 2NF, a kolumny bez klucza są niezależne od siebie. Innymi słowy, kolumny bez klucza są zależne od klucza podstawowego, tylko od klucza podstawowego i nic więcej. Na przykład załóżmy, że mamy Products tabelę z kolumnami productID (klucz podstawowy), name I unitPrice., Kolumna discountRate nie powinna należeć do tabeli Products jeśli jest również zależna od unitPrice, która nie jest częścią klucza głównego.
wyższa normalna forma: 3NF ma swoje niedoskonałości, co prowadzi do wyższej normalnej formy, takiej jak Boyce / Codd normalna forma, czwarta normalna forma (4NF) i piąta normalna forma( 5NF), która jest poza zakresem tego samouczka.
czasami możesz zdecydować się na złamanie niektórych zasad normalizacji, ze względu na wydajność (np.,, Utwórz kolumnę o nazwie totalPricew Orderstable, która może być pobrana z rekordów orderDetails); lub ponieważ użytkownik końcowy o nią poprosił. Upewnij się, że jesteś w pełni tego świadomy, opracuj logikę programowania, aby ją obsłużyć i odpowiednio udokumentuj decyzję.
reguły integralności
należy również zastosować reguły integralności, aby sprawdzić integralność projektu:
reguła integralności encji: klucz podstawowy nie może zawierać NULL. W przeciwnym razie nie może jednoznacznie zidentyfikować wiersza., Dla klucza złożonego składającego się z kilku kolumn, żadna z kolumn nie może zawierać NULL. Większość RDBMS sprawdza i egzekwuje tę regułę.
reguła Referencjalnej integralności: każda wartość klucza obcego musi być dopasowana do podstawowej wartości klucza w tabeli, do której odnosi się (lub tabeli nadrzędnej).
- wiersz z kluczem obcym można wstawić do tabeli podrzędnej tylko wtedy, gdy wartość istnieje w tabeli nadrzędnej.
- Jeśli wartość klucza zmieni się w tabeli nadrzędnej(np. wiersz zaktualizowany lub usunięty), wszystkie wiersze z tym kluczem obcym w tabeli podrzędnej muszą być odpowiednio obsługiwane., Można albo (a) zablokować zmiany; (b) kaskadowo zmienić (lub usunąć rekordy) w tabelach potomnych odpowiednio; (c) ustawić wartość klucza w tabelach potomnych NA NULL.
Większość RDBMS może być ustawiona tak, aby wykonać kontrolę i zapewnić integralność odniesienia w określony sposób.
integralność logiki biznesowej: obok powyższych dwóch ogólnych zasad integralności, może istnieć integralność (Walidacja) odnosząca się do logiki biznesowej, np.,, Kod Pocztowy powinien być 5-cyfrowy w określonych przedziałach, Data i godzina dostawy przypada w godzinach pracy; Zamówiona ilość jest równa lub mniejsza niż ilość w magazynie itp. Mogą one być realizowane w regułach walidacji (dla konkretnej kolumny) lub w logice programowania.
indeksowanie kolumn
możesz utworzyć indeks na wybranych kolumnach, aby ułatwić wyszukiwanie i pobieranie danych. Indeks jest uporządkowanym plikiem, który przyspiesza dostęp do danych dla SELECT, ale może spowolnić INSERT, UPDATE I DELETE., Bez struktury indeksu, aby przetworzyć zapytanie SELECT z dopasowanym kryterium (np. SELECT * FROM Customers WHERE name='Tan Ah Teck'), silnik bazy danych musi porównywać każdy rekord w tabeli. Wyspecjalizowany indeks (np. w strukturze BTREE) może dotrzeć do rekordu bez porównywania każdego rekordu. Jednak indeks musi być odbudowany, gdy rekord jest zmieniany, co skutkuje narzutami związanymi z używaniem indeksów.
indeks może być zdefiniowany na pojedynczej kolumnie, zestawie kolumn (zwanym indeksem konkatenowanym) lub części kolumny (np.,, pierwszych 10 znaków VARCHAR(100)) (tzw. indeks częściowy). Można zbudować więcej niż jeden indeks w tabeli. Na przykład, jeśli często wyszukujesz klienta za pomocą customerName lub phoneNumber, możesz przyspieszyć wyszukiwanie, budując indeks w kolumnie customerName, a także phoneNumber. Większość RDBMS buduje indeks na głównym kluczu automatycznie.
reference & RESOURCES
najnowsza wersja testowana: MySQL 5.5.15
Ostatnia modyfikacja: wrzesień 2010