Johdanto
Relaatiotietokanta ehdotti Edgar Codd (IBM Research) noin 1969. Se on sittemmin tullut hallitseva tietokanta malli kaupallisia sovelluksia (verrattuna muihin tietokanta malleja, kuten hierarkkinen, verkko-ja esine-mallit). Tänään, on olemassa monia kaupallisia Relaatiotietokannan hallintajärjestelmä (RDBMS), kuten Oracle, IBM DB2 ja Microsoft SQL Server., On olemassa myös monia ilmaisia ja avoimen lähdekoodin RDBMS, kuten MySQL, mSQL (mini-SQL) ja sulautettujen JavaDB (Apache Derby).
relaatiotietokanta järjestää tietoja taulukoissa (tai suhteissa). Taulukko koostuu riveistä ja sarakkeista. Riviä kutsutaan myös levyksi (tai tuplaksi). Saraketta kutsutaan myös kentäksi (tai attribuutiksi). Tietokantataulukko on samanlainen kuin taulukkolaskenta. Taulukoiden välille voidaan kuitenkin luoda suhteita, joiden avulla relaatiotietokanta pystyy tehokkaasti tallentamaan valtavan määrän dataa ja tehokkaasti noutamaan valittuja tietoja.,
kieli nimeltä SQL (strukturoitu kyselykieli) kehitettiin toimimaan relaatiotietokantojen kanssa.
Tietokannan Suunnittelun Tavoitteena
hyvin suunniteltu tietokanta on:
- Poistaa Tietojen Redundanssia: sama pala tiedot on ei tallentaa enemmän kuin yhdessä paikassa. Tämä johtuu siitä, että päällekkäiset tiedot paitsi jätteen säilytystiloista myös johtavat helposti epäjohdonmukaisuuksiin.
- Varmistaa Tietojen Eheys ja Tarkkuus:
- enemmän
Relaatiotietokannan Suunnittelu Prosessi
Tietokannan suunnittelu on enemmän taidetta kuin tiedettä, koska sinun täytyy tehdä monia päätöksiä., Tietokannat räätälöidään yleensä tiettyyn sovellukseen sopivaksi. Kaksi räätälöityä sovellusta eivät ole samanlaisia, ja siksi kaksi tietokantaa eivät ole samanlaisia. Ohjeet (yleensä kannalta, mitä ei pidä tehdä sen sijaan, mitä tehdä) annetaan tehdä nämä suunnittelun päätöstä, mutta valintoja lopulta levätä sinä – suunnittelija.
Vaihe 1: Määritä Tarkoitus Tietokantaan (Vaatimus-Analyysi)
Kerätä vaatimuksia ja määritellä tavoite oman tietokannan, esim …
näytteenottolomakkeiden, kyselyjen ja raporttien laatiminen auttaa usein.,
Vaihe 2: kerätä tietoja, järjestää taulukoissa ja määrittää ensisijaiset avaimet
kun olet päättänyt tietokannan tarkoituksesta, kerätä tiedot, jotka on tallennettava tietokantaan. Jaa tiedot ainekohtaisiin taulukoihin.
Valitse yksi sarake (tai muutama sarakkeita) kuin ns perusavain, joka yksilöi jokaisen krs.
Ensisijaisen Avaimen
Vuonna relaatio-malli, taulukko voi sisältää päällekkäisiä rivit, koska se aiheuttaisi epäselvyyksiä haku., Varmistetaan ainutlaatuisuus, jokainen pöytä olisi pitänyt sarakkeen (tai sarakkeet), jota kutsutaan perusavain, joka yksilöi jokaisen records taulukossa. Esimerkiksi, ainutlaatuinen numero customerID voidaan käyttää ensisijaisena avain Customers taulukko; productCode for Products taulukko; isbn for Books taulukko. Primääriavainta kutsutaan yksinkertaiseksi avaimeksi, jos se on yksi sarake; sitä kutsutaan komposiittiavaimeksi, jos se koostuu useista sarakkeista.,
useimmat rdbmss rakentavat indeksin ensisijaiselle avaimelle nopean haun ja hakemisen helpottamiseksi.
ensisijaista avainta käytetään myös muiden taulukoiden viitoittamiseen (tarkennetaan myöhemmin).
sinun on päätettävä, mitä saraketta(sarakkeita) käytetään ensisijaiseen avaimeen. Päätös voi olla suoraan eteenpäin, mutta ensisijainen avain on nämä ominaisuudet:
- arvot perusavain on yksilöllinen (eli, ei päällekkäisiä arvo)., Esimerkiksi
customerNameei voi olla aiheellista käyttää ensisijaisena avainCustomerstaulukko, koska siellä voisi olla kaksi asiakasta, joilla on sama nimi. - ensisijaisella avaimella on aina oltava arvo. Toisin sanoen se ei saa sisältää Nollaa.
Harkitse seuraavasti valitse ensisijainen avain:
- ensisijainen avain on yksinkertainen ja tuttu, esim.
employeeIDforemployeestaulukko jaisbnforbookstaulukko., - ensisijaisen avaimen arvo ei saa muuttua. Ensisijaista avainta käytetään viittaamaan muihin taulukoihin. Jos muutat sen arvoa, sinun täytyy muuttaa kaikki sen viittaukset; muuten viittaukset menetetään. Esimerkiksi
phoneNumberei voi olla tarkoituksenmukaista käyttää ensisijainen avain taulukkoonCustomers, koska se saattaa muuttua. - Primääriavaimessa käytetään usein kokonaisluku (tai numero) – tyyppiä. Mutta se voi olla myös muita tyyppejä, kuten tekstejä. On kuitenkin parasta käyttää numeerista saraketta tehokkuuden ensisijaisena avaimena.
- ensisijainen avain voisi ottaa mielivaltaisen numeron., Useimmat RDBMSs tukea ns. auto-lisäys (tai
AutoNumbertyyppi) integer primary key, missä (nykyinen suurin arvo + 1) on osoitettu uusi ennätys. Tämä mielivaltainen luku on faktoja vähemmän, sillä se ei sisällä mitään faktatietoa. Toisin kuin faktatieto, kuten puhelinnumero, fakta vähemmän Numero on ihanteellinen ensisijainen avain, koska se ei muutu. - Ensisijainen avain on yleensä yhden sarakkeen (esim.
customerIDtaiproductCode). Mutta se voi myös muodostaa useita sarakkeita. Kannattaa käyttää mahdollisimman vähän sarakkeita.,
Let’s illustrate with an example: a table customers contains columns lastName, firstName, phoneNumber, address, city, state, zipCode. The candidates for primary key are name=(lastName, firstName), phoneNumber, Address1=(address, city, state), Address1=(address, zipCode). Name may not be unique. Phone number and address may change., Siksi on parempi luoda fakta-vähemmän automaattinen lisäysnumero, sano customerID, ensisijaisena avaimena.
Vaihe 3: Luo Suhteita keskuudessa Taulukot
tietokanta koostuu itsenäisistä ja erillisistä taulukoista hyötyä (voit halutessasi käyttää taulukkolaskenta sijaan). Relaatiotietokannan voima on taulukoiden välisessä suhteessa, joka voidaan määritellä. Ratkaisevinta relaatiotietokannan suunnittelussa on löytää taulukoiden väliset suhteet., Tyypit suhteen ovat:
- yksi-monia
- monta-monta
- yksi
One-to-many
Vuonna ”luokka roster” – tietokanta, opettaja voi opettaa nolla tai useampia luokkia, kun taas luokka on opettanut yksi (ja vain yksi) opettaja. ”Yritys” – tietokanta, johtaja hallinnoi nollaa tai useampaa työntekijää, kun työntekijä on hallinnoi yksi (ja vain yksi) johtaja. ”Tuotemyyntitietokannassa” asiakas voi tehdä useita tilauksia, kun taas tilauksen tekee yksi tietty asiakas. Tällainen suhde tunnetaan kahdenkeskisenä.,
yhdestä moneen suhdetta ei voi esittää yhdessä taulukossa. Esimerkiksi ”luokan roster” – tietokanta, emme voi alkaa taulukkoon nimeltä Teachers, joka tallentaa tietoa opettajien (kuten name, office, phone ja email). Tallentaa luokat opettanut, jokainen opettaja, voisimme luoda sarakkeita class1, class2, class3, mutta kohtaa ongelman heti, kuinka monta saraketta luoda., Toisaalta, jos aloitamme taulukkoon nimeltä Classes, joka tallentaa tietoa luokan (courseCode, dayOfWeek, timeStart ja timeEnd); voisimme luoda lisää sarakkeita tallentaa tietoja (yksi) opettaja (kuten name, office, phone ja email). Kuitenkin, koska opettaja voi opettaa monia luokkia, sen tiedot olisi monistaa monta riviä taulukossa Classes.,
tukea yksi-moneen-suhde, meidän täytyy suunnitella kaksi taulukkoa: taulukko Classes tallentaa tietoa luokat classID ensisijainen avain; ja taulukko Teachers tallentaa tietoa opettajille teacherID ensisijainen avain. Voimme sitten luoda yksi-moneen-suhde tallentamalla perusavain taulukon Teacher (ts.,, teacherID) (”yksi”-end tai vanhemman taulukko) taulukossa classes (”paljon”-end tai lapsi taulukko), kuten on esitetty alla.
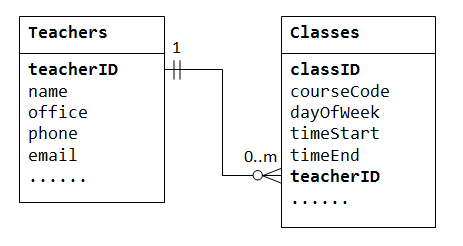
sarake teacherID lapsi taulukossa Classes tunnetaan ulko-näppäintä. Viiteavain lapsi taulukossa on perusavain vanhemman taulukko, jota käytetään viitata vanhemman taulukko.
Ota huomioon, että jokaista arvoa vanhemman pöytä, ei voi olla nolla, yksi tai useampia rivejä lapsi taulukossa., Jokaiselle arvo-lasten pöytä, on yksi ja vain yksi rivi vanhemman taulukko.
Monta-moneen-
”tuotteen myynti” tietokantaan, asiakkaan tilauksen voi sisältää yhden tai useampia tuotteita, ja tuote voi esiintyä monissa tilauksia. ”Kirjakaupan” tietokannassa kirjan on kirjoittanut yksi tai useampi kirjoittaja, kun taas kirjailija voi kirjoittaa nolla-tai useampia kirjoja. Tällainen suhde tunnetaan monen välisenä.
Let ’ s illustrate with a ”product sales” database. Aloitamme kaksi taulukkoa: Products ja Orders., Taulukossa products sisältää tietoa tuotteista (kuten name, description ja quantityInStock) productID koska sen ensisijainen avain. Taulukossa orders sisältää asiakkaan tilaukset (customerID, dateOrdered, dateRequired ja status). Jälleen, emme voi varastoida tilattuja tavaroita sisälle Orders taulukko, koska emme tiedä, kuinka monta saraketta reserve kohteita., Tilaustietoja ei myöskään voi tallentaa Products taulukkoon.
tukea monesta moneen-suhde, meidän täytyy luoda kolmas taulukko (tunnetaan risteyksessä taulukko), sanoa OrderDetails (tai OrderLines), jossa jokainen rivi edustaa kohteen tietyssä järjestyksessä. Esimerkiksi OrderDetails taulukon perusavain koostuu kaksi saraketta: orderID ja productID, joka yksilöi jokaisen rivin., Sarakkeet orderID ja productID vuonna OrderDetails taulukko käytetään viite Orders ja Products taulukot, näin ollen ne ovat myös ulkomaiset avaimet OrderDetails taulukko.
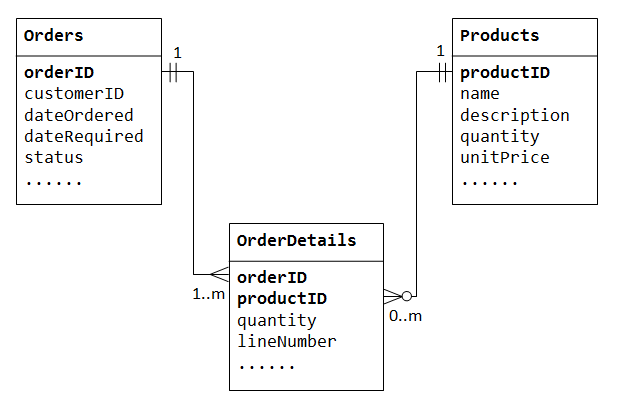
monta-moneen-suhde on itse asiassa toteutettu kaksi yksi-moneen-suhteita, ottamalla käyttöön risteyksessä taulukko.
- tilauksessa on monta kohdetta
OrderDetails.OrderDetailserä kuuluu yhteen tiettyyn järjestykseen., - tuote saattaa näyttää monissa
OrderDetails. KukinOrderDetailstuote erikseen.
One-to-One
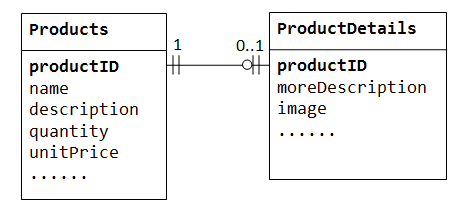
”tuotteen myynti” – tietokanta, tuote voi olla valinnainen lisätiedot, kuten image, moreDescription ja comment. Niiden pitäminen Products – taulukon sisällä johtaa moniin tyhjiin tiloihin (noissa tietueissa ilman näitä valinnaisia tietoja). Lisäksi nämä suuret tiedot voivat heikentää tietokannan suorituskykyä.,
sen Sijaan, voimme luoda toinen pöytä (sanoa ProductDetails, ProductLines tai ProductExtras) tallentaa valinnaiset tiedot. Tiedot laaditaan vain niille tuotteille, joilla on valinnaisia tietoja. Kaksi taulukkoa, Products ja ProductDetails, näyttely on yksi-yhteen suhde. Eli jokaista vanhempainpöydän riviä kohden on korkeintaan yksi rivi (mahdollisesti nolla) lastenpöydässä. Molempien taulukoiden ensisijaisena avaimena tulisi käyttää samaa saraketta productID.,
jotkin tietokannat rajoittavat taulukon sisällä luotavien sarakkeiden määrää. Voit käyttää yksi-yksi-suhde jakaa tiedot kahteen taulukkoon. Yksi yhteen-suhteesta on hyötyä myös tiettyjen arkaluonteisten tietojen tallentamisessa suojattuun taulukkoon, kun taas ei-arkaluonteiset ovat päätaulukossa.
sarakkeen tietotyypit
jokaiselle sarakkeelle on valittava sopiva tietotyyppi. Yleisesti tietotyypit ovat: kokonaislukuja, liukulukuja numerot, string (tai teksti), päivämäärä/aika, binary, kokoelma (kuten luettelo ja asettaa).,
Vaihe 4: Tarkenna & Normalisoida Suunnittelu
esimerkiksi
- lisäämällä sarakkeita,
- luo uusi taulukko valinnaisia tietoja käyttämällä yksi-yhteen suhde,
- jakaa suuren pöydän kahteen pienempiä taulukoita,
- muut.
Normalisointi
Käytä ns normalisointi säännöt tarkistaa, onko tietokanta on rakenteeltaan oikea ja optimaalinen.
Ensimmäinen normaalimuoto (1NF): taulukko on 1NF, jos jokainen solu sisältää yhden arvon, ei luettelon arvot. Tämä ominaisuus tunnetaan atomina., 1NF kielletään myös toistuva ryhmä sarakkeita, kuten item1, item2,.., itemN. Sen sijaan, sinun pitäisi luoda toinen taulukko käyttäen yksi-monta suhdetta.
Toinen normaalimuoto (2NF): taulukko on 2NF, jos se on 1NF ja kaikki ei-avain-sarakkeessa on täysin riippuvainen ensisijainen avain. Lisäksi, jos ensisijainen avain koostuu useista sarakkeista, jokaisen Ei-avaimellisen sarakkeen on oltava koko joukon eikä sen osan varassa.,
esimerkiksi, ensisijaisena avain OrderDetails taulukko sisältää orderID ja productID. Jos unitPrice riippuu ainoastaan productID, se ei saa pitää OrderDetails taulukko (mutta Products taulukko). Toisaalta, jos unitPrice riippuu tuotteen sekä tietyssä järjestyksessä, niin se on pidettävä OrderDetails taulukko.,
Kolmas normaalimuoto (3NF): taulukko on 3NF, jos se on 2NF ja ei-avain sarakkeet ovat toisistaan riippumattomia muille. Toisin sanoen muut kuin Keskeiset sarakkeet ovat riippuvaisia ensisijaisesta avaimesta, vain ensisijaisesta avaimesta eikä mistään muusta. Oletetaan esimerkiksi, että meillä on Products taulukko, jossa on sarakkeet productID (primary key), name ja unitPrice., Sarake discountRate ei kuulu Products taulukko, jos se on myös riippuvainen unitPrice, joka ei ole osa perusavainta.
Korkeampi Normaali Muoto: 3NF on sen puutteita, mikä johtaa korkeampiin Normaali muodossa, kuten Boyce/Codd normaalimuodossa, Neljäs normaalimuoto (4NF) ja Viides normaalimuoto (5NF), joka ei kuulu tämän opetusohjelman.
toisinaan saatat päättää rikkoa joitain normalisointisääntöjä suoritussyistä (esim., luo sarake nimeltä totalPrice vuonna Orders taulukko joka voi olla peräisin orderDetails kirjaa); tai koska käyttäjä pyytää sitä. Varmista, että olet täysin tietoinen siitä, kehittää ohjelmointilogiikkaa käsitellä sitä, ja oikein dokumentoida päätös.
Koskemattomuutta koskevat Säännöt
Sinun pitäisi myös soveltaa eheyden säännöt tarkistaa eheyden suunnittelu:
Entity Integrity Sääntö: tärkein avain voi sisältää NULL. Muuten se ei voi yksilöidä riviä., Useista sarakkeista koostuvassa komposiittiavaimessa mikään kolonnista ei voi sisältää Nollaa. Suurin osa RDBMS tarkistaa ja valvoa tämän säännön.
Viite-Eheyden Sääntö: Jokainen viiteavain arvo on sovitettava perusavain arvo taulukossa viitataan (tai vanhempi.taulukko).
- Voit lisätä rivi viiteavain lapsi taulukossa vain, jos arvo on vanhemman taulukko.
- Jos arvo keskeiset muutokset vanhemman taulukko (esim. rivi, päivitetty tai poistettu), kaikki rivit tämän viiteavain lapsi taulukossa(t) on käsiteltävä sen mukaisesti., Voit joko (a) estää muutokset; (b) cascade muutos (tai poistaa tietueita) lapsen taulukoiden mukaisesti; (c) aseta avain-arvo lapsen taulukot NULL.
useimmat RDBMS voidaan asettaa suorittamaan tarkastus ja varmistamaan viitearvon eheys, määritellyllä tavalla.
Liiketoiminnan logiikkaa Eheys: Vieressä edellä kaksi yleistä koskemattomuutta sääntöjä, ei voi olla rehellisyys (validointi), jotka liittyvät liiketoiminnan logiikkaa, esim., zip-koodi on 5-numeroinen tietyn vaihtelee, toimitus päivämäärä ja aika on lasku työaikana; tilattu määrä on yhtä suuri tai pienempi kuin määrä, varastossa, jne. Ne voitaisiin toteuttaa validointisäännössä (tietyn sarakkeen osalta) tai ohjelmointilogiikassa.
Sarake Indeksointi
Voit luoda indeksi valitun sarakkeen(s) helpottaa tietojen etsimistä ja hakemista. Indeksi on jäsennelty tiedosto, joka nopeuttaa tietojen saatavuutta SELECT, mutta voi hidastaa INSERT, UPDATE ja DELETE., Ilman indeksiä rakenne, prosessi SELECT kyselyn kanssa matching kriteeri (esim. SELECT * FROM Customers WHERE name='Tan Ah Teck'), tietokanta moottori tarvitsee verrata kaikki tietueet taulukosta. Erikoistunut indeksi (esimerkiksi BTREE-rakenteessa)voisi saavuttaa ennätyksen vertaamatta jokaista ennätystä. Indeksi on kuitenkin korjattava aina, kun tietuetta muutetaan, mikä johtaa indeksien käyttöön liittyviin yleiskustannuksiin.
– Indeksi voidaan määritellä yhdellä sarake, sarakkeet (ns. ketjutettuja indeksi), tai osa sarakkeen (esim.,, ensimmäiset 10 merkkiä VARCHAR(100)) (ns .osittaisindeksi). Taulukkoon voisi rakentaa useamman indeksin. Esimerkiksi,, jos et usein etsiä asiakasta käyttäen joko customerName tai phoneNumber voit nopeuttaa hakua rakentaa indeksi sarake customerName sekä phoneNumber. Useimmat RDBMS rakentaa indeksin ensisijaisen avaimen automaattisesti.
VIITTAUKSIA & RESURSSIT
Uusin versio testattu: MySQL 5.5.15
Last modified: syyskuu, 2010