Introducción
base de datos relacional fue propuesto por Edgar Codd (de IBM Research) alrededor de 1969. Desde entonces se ha convertido en el modelo de base de datos dominante para aplicaciones comerciales (en comparación con otros modelos de base de datos como los modelos jerárquicos, de red y de objetos). Hoy en día, hay muchos sistemas de gestión de bases de datos relacionales comerciales (RDBMS), como Oracle, IBM DB2 y Microsoft SQL Server., También hay muchos RDBMS libres y de código abierto, como MySQL, mSQL (mini-SQL) y el javadb incrustado (Apache Derby).
una base de datos relacional organiza los datos en tablas (o relaciones). Una tabla se compone de filas y columnas. Una fila también se llama registro (o tupla). Una columna también se llama campo (o atributo). Una tabla de base de datos es similar a una hoja de cálculo. Sin embargo, las relaciones que se pueden crear entre las tablas permiten que una base de datos relacional almacene de manera eficiente una gran cantidad de datos y recupere efectivamente los datos seleccionados.,
se desarrolló un lenguaje llamado SQL (Structured Query Language) para trabajar con bases de datos relacionales.
objetivo de diseño de la base de datos
una base de datos bien diseñada deberá:
- eliminar la redundancia de datos: la misma pieza de datos no se almacenará en más de un lugar. Esto se debe a que los datos duplicados no solo desperdician espacios de almacenamiento, sino que también conducen fácilmente a inconsistencias.
- garantizar la integridad y precisión de los datos:
- Más
proceso de diseño de bases de datos relacionales
El diseño de bases de datos es más arte que ciencia, ya que tiene que tomar muchas decisiones., Las bases de datos generalmente se personalizan para adaptarse a una aplicación en particular. No hay dos aplicaciones personalizadas iguales, y por lo tanto, no hay dos bases de datos iguales. Las pautas (generalmente en términos de qué no hacer en lugar de qué hacer) se proporcionan al tomar estas decisiones de diseño, pero las opciones en última instancia dependen de usted, el diseñador.
Paso 1: Definir el propósito de la base de Datos (Análisis de requisitos)
reunir los requisitos y definir el objetivo de su base de datos, por ejemplo …
redactar los formularios de entrada de muestra, consultas e informes, a menudo ayuda.,
Paso 2: recopilar datos, organizar en tablas y especificar las claves primarias
Una vez que haya decidido el propósito de la base de datos, recopilar los datos que se necesitan para ser almacenados en la base de datos. Divida los datos en tablas basadas en temas.
elija una columna (o algunas columnas) como la llamada clave primaria, que identifica de forma única cada una de las filas.
Primary Key
en el modelo relacional, una tabla no puede contener filas duplicadas, porque eso crearía ambigüedades en la recuperación., Para garantizar la unicidad, cada tabla debe tener una columna (o un conjunto de columnas), llamada clave primaria, que identifique de forma única todos los registros de la tabla. Por ejemplo, un número único customerID puede ser utilizado como la principal clave para el Customers tabla; productCode para Products tabla; isbn para Books tabla. Una clave primaria se llama clave simple si es una sola columna; se llama clave compuesta si está compuesta de varias columnas.,
La mayoría de los RDBMSs construyen un índice sobre la clave principal para facilitar la búsqueda y recuperación rápidas.
la clave primaria también se utiliza para hacer referencia a otras tablas (que se elaborarán más adelante).
Usted tiene que decidir qué columna(s) se va a utilizar para la clave primaria. La decisión puede no ser directa, pero la clave primaria debe tener estas propiedades:
- Los valores de la clave primaria deben ser únicos (es decir, sin valor duplicado)., Por ejemplo,
customerNamepuede no ser apropiado para ser utilizado como la clave principal para la tablaCustomers, ya que podría haber dos clientes con el mismo nombre. - La clave primaria siempre tendrá un valor. En otras palabras, no contendrá NULL.
Considere el siguiente en elegir la clave primaria:
- La clave principal será sencillo y familiar, por ejemplo,
employeeIDparaemployeestabla yisbnparabookstabla., - El valor de la clave primaria no debe cambiar. La clave primaria se utiliza para hacer referencia a otras tablas. Si Cambia su valor, tiene que cambiar todas sus referencias; de lo contrario, las referencias se perderán. Por ejemplo,
phoneNumberpuede no ser apropiado para ser utilizado como clave primaria para la tablaCustomers, porque podría cambiar. - La clave primaria a menudo utiliza el tipo entero (o número). Pero también podrían ser otros tipos, como los textos. Sin embargo, lo mejor es utilizar la columna numérica como clave principal para la eficiencia.
- La clave primaria puede tomar un número arbitrario., La mayoría de los RDBMSs admiten el llamado incremento automático (o
AutoNumbertype) para la clave primaria entera, donde (valor máximo actual + 1) se asigna al nuevo registro. Este número arbitrario carece de hechos, ya que no contiene información objetiva. A diferencia de la información objetiva, como el número de teléfono, el número sin hechos es ideal para la clave primaria, ya que no cambia. - La clave primaria suele ser una sola columna (por ejemplo,
customerIDoproductCode). Pero también podría conformar varias columnas. Debe utilizar el menor número posible de columnas.,
Let’s illustrate with an example: a table customers contains columns lastName, firstName, phoneNumber, address, city, state, zipCode. The candidates for primary key are name=(lastName, firstName), phoneNumber, Address1=(address, city, state), Address1=(address, zipCode). Name may not be unique. Phone number and address may change., Por lo tanto, es mejor crear un número de incremento automático sin hechos, por ejemplo customerID, como clave principal.
Paso 3: Crear relaciones entre tablas
una base de datos que consiste en tablas independientes y no relacionadas sirve de poco (puede considerar usar una hoja de cálculo en su lugar). El poder de la base de datos relacional radica en la relación que se puede definir entre tablas. El aspecto más crucial en el diseño de una base de datos relacional es identificar las relaciones entre las tablas., Los tipos de relación incluyen:
- uno a muchos
- Muchos a muchos
- uno a uno
uno a muchos
en una base de datos de «Lista de clases», un maestro puede enseñar cero o más clases, mientras que una clase es impartida por un (y solo un) maestro. En una base de datos de «empresa», un gerente administra cero o más empleados, mientras que un empleado es administrado por un gerente (y solo uno). En una base de datos de «ventas de productos», un cliente puede realizar muchos pedidos; mientras que un pedido es realizado por un cliente en particular. Este tipo de relación se conoce como uno a muchos.,
la relación uno a muchos no se puede representar en una sola tabla. Por ejemplo, en una base de datos «class roster», podemos comenzar con una tabla llamada Teachers, que almacena información sobre los profesores (como name, office, phone y email). Para almacenar las clases impartidas por cada profesor, podríamos crear columnas class1, class2, class3, pero se enfrenta a un problema de inmediato cuántas columnas para crear., Por otro lado, si partimos de una tabla denominada Classes, que almacena información acerca de una clase (courseCode, dayOfWeek, timeStart y timeEnd); podríamos crear columnas adicionales para almacenar información acerca de la (una) maestro (como name, office, phone y email). Sin embargo, dado que un profesor puede enseñar muchas clases, sus datos se duplicarían en muchas filas en la tabla Classes.,
para soportar una relación de uno a muchos, necesitamos diseñar dos tablas: una tabla Classes para almacenar información sobre las clases con classID como clave principal; y una tabla Teachers para almacenar información sobre los profesores con teacherID como clave principal. Luego podemos crear la relación uno-a-muchos almacenando la clave primaria de la tabla Teacher (I. e.,, teacherID) (el extremo»uno»o la tabla principal) en la tabla classes (el extremo»muchos» o la tabla secundaria), como se ilustra a continuación.
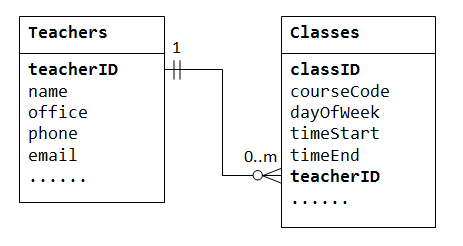
La columna teacherID en el niño tabla Classes se conoce como la clave externa. Una clave foránea de una tabla secundaria es una clave primaria de una tabla primaria, utilizada para hacer referencia a la tabla primaria.
tenga en cuenta que para cada valor en la tabla principal, podría haber cero, una o más filas en la tabla secundaria., Para cada valor en la tabla secundaria, hay una y solo una fila en la tabla principal.
muchos a muchos
en una base de datos de «ventas de productos», el pedido de un cliente puede contener uno o más productos; y un producto puede aparecer en muchos pedidos. En una base de datos de «librería», un libro es escrito por uno o más autores; mientras que un autor puede escribir cero o más libros. Este tipo de relación se conoce como muchos-a-muchos.
vamos a ilustrar con una base de datos de «ventas de productos». Comenzamos con dos tablas: Products y Orders., La tabla products contiene información acerca de los productos (tales como name, description y quantityInStock) con la etiqueta productID como clave principal. La tabla orders contiene las órdenes del cliente (customerID, dateOrdered, dateRequired y status). Una vez más, no podemos almacenar los artículos ordenados dentro de la tabla Orders, ya que no sabemos cuántas columnas reservar para los artículos., Tampoco podemos almacenar la información del pedido en la tabla Products.
para soportar la relación de muchos a muchos, necesitamos crear una tercera tabla (conocida como tabla de unión), por ejemplo OrderDetails (o OrderLines), donde cada fila representa un elemento de un orden particular. Para el OrderDetails tabla, la clave principal consta de dos columnas: orderID y productID, que identifican de forma única a cada fila., Las columnas orderID y productID en el OrderDetails tabla se utiliza para hacer referencia a Orders y Products tablas, por lo tanto, son también las claves foráneas en el OrderDetails tabla.
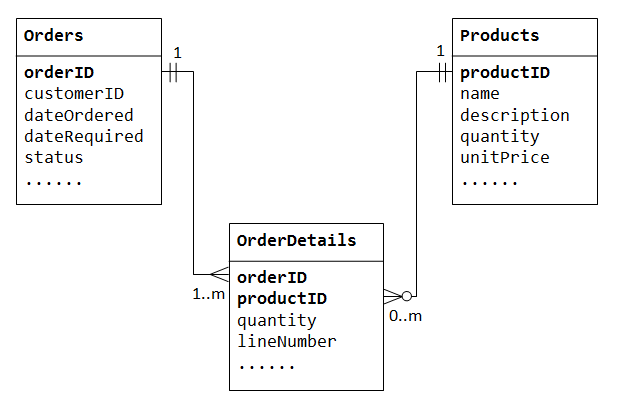
la relación muchos-a-muchos es, de hecho, implementada como dos relaciones uno-a-muchos, con la introducción de la tabla de unión.
- un pedido tiene muchos elementos en
OrderDetails. Un elementoOrderDetailspertenece a un pedido en particular., - un producto puede aparecer en muchos
OrderDetails. Cada elementoOrderDetailsespecificó un producto.
One-To-One
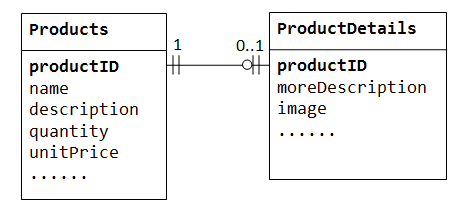
en una base de datos de «ventas de productos», un producto puede tener información complementaria opcional, como image, moreDescription y comment. Mantenerlos dentro de la tabla Products resulta en muchos espacios vacíos (en esos registros sin estos datos opcionales). Además, estos grandes datos pueden degradar el rendimiento de la base de datos.,
en Lugar de eso, podemos crear otra tabla (es decir ProductDetails, ProductLines o ProductExtras) para almacenar los datos opcionales. Solo se creará un registro para aquellos productos con datos opcionales. Las dos tablas, Products y ProductDetails, exhiben un uno-a-uno. Es decir, por cada fila de la tabla principal, hay como máximo una fila (posiblemente cero) en la tabla secundaria. La misma columna productID debe usarse como clave principal para ambas tablas.,
algunas bases de datos limitan el número de columnas que se pueden crear dentro de una tabla. Podría usar una relación uno a uno para dividir los datos en dos tablas. La relación uno a uno también es útil para almacenar ciertos datos confidenciales en una tabla segura, mientras que los no confidenciales en la tabla principal.
tipos de datos de columna
debe elegir un tipo de datos apropiado para cada columna. Comúnmente los tipos de datos incluyen: enteros, Números de coma flotante, cadena (o texto), Fecha/Hora, binario, colección (como enumeración y conjunto).,
Paso 4: refinar & normalizar el diseño
por ejemplo,
- agregar más columnas,
- Crear una nueva tabla para datos opcionales utilizando una relación uno a uno,
- dividir una tabla grande en dos tablas más pequeñas,
- otras.
normalización
aplique las llamadas reglas de normalización para comprobar si su base de datos es estructuralmente correcta y óptima.
primera forma Normal (1NF): una tabla es 1NF si cada celda contiene un solo valor, no una lista de valores. Estas propiedades se conocen como atómicas., 1NF también prohíbe la repetición de un grupo de columnas, tales como item1, item2,.., itemN. En su lugar, debe crear otra tabla utilizando una relación de uno a muchos.
segunda forma Normal (2NF): una tabla es 2NF, si es 1NF y cada columna sin clave es completamente dependiente de la clave primaria. Además, si la clave primaria está formada por varias columnas, cada columna que no sea clave dependerá de todo el conjunto y no de parte de él.,
Por ejemplo, la clave principal de la etiqueta OrderDetails tabla que comprende orderID y productID. Si unitPrice es que sólo depende de productID, que no serán guardados en el OrderDetails tabla (pero en el Products tabla). Por otro lado, si unitPrice depende del producto así como del pedido en particular, entonces se mantendrá en la tabla OrderDetails.,
tercera forma Normal (3NF): una tabla es 3NF, si es 2NF y las columnas no clave son independientes entre sí. En otras palabras, las columnas que no son clave dependen de la clave primaria, solo de la clave primaria y nada más. Por ejemplo, supongamos que tenemos un Products tabla con columnas productID (clave primaria), name y unitPrice., La columna discountRate no pertenecerá a la tabla Products si también depende de la tabla unitPrice, que no forma parte de la clave primaria.
Forma Normal Superior: 3NF tiene sus insuficiencias, lo que conduce a una forma Normal Superior, como la forma normal Boyce/Codd, la cuarta forma Normal (4NF) y la quinta forma Normal (5NF), que está más allá del alcance de este tutorial.
a veces, puede decidir romper algunas de las reglas de normalización, por razones de rendimiento (p. ej.,, cree una columna llamada totalPrice en la tablaOrders que puede derivarse de los registros orderDetails; o porque el usuario final lo solicitó. Asegúrese de que usted es plenamente consciente de ello, desarrollar la lógica de programación para manejarlo, y documentar adecuadamente la decisión.
reglas de integridad
también debe aplicar las reglas de integridad para comprobar la integridad de su diseño:
regla de integridad de entidad: la clave primaria no puede contener NULL. De lo contrario, no puede identificar de forma única la fila., Para la clave compuesta compuesta por varias columnas, ninguna de las columnas puede contener NULL. La mayoría de los RDBMS comprueban y aplican esta regla.
regla de integridad referencial: cada valor de clave foránea debe coincidir con un valor de clave primaria en la tabla a la que se hace referencia (o tabla principal).
- Puede insertar una fila con una clave foránea en la tabla secundaria solo si el valor existe en la tabla principal.
- si el valor de la clave cambia en la tabla principal (por ejemplo, la fila actualizada o eliminada), todas las filas con esta clave foránea en las tablas secundarias deben manejarse en consecuencia., Puede (a) no permitir los cambios; (b) en cascada el cambio (o eliminar los registros) en las tablas secundarias en consecuencia; (c) establecer el valor de clave en las tablas secundarias En NULL.
La mayoría de los RDBMS se pueden configurar para realizar la comprobación y garantizar la integridad referencial, de la manera especificada.
integridad de la lógica de negocio: además de las dos reglas generales de integridad anteriores, podría haber integridad (validación) perteneciente a la lógica de negocio, p. ej.,, el código postal será de 5 dígitos dentro de ciertos rangos, la fecha y hora de entrega caerán en el horario comercial; la cantidad pedida será igual o menor que la cantidad en stock, etc. Estos podrían llevarse a cabo en regla de validación (para la columna específica) o lógica de programación.
indexación de columnas
Puede crear un índice en las columnas seleccionadas para facilitar la búsqueda y recuperación de datos. Un índice es una estructura de archivos que acelera el acceso a los datos de SELECT, pero puede ralentizar INSERT, UPDATE y DELETE., Sin una estructura de índice, para procesar una consulta SELECT con un criterio coincidente (por ejemplo, SELECT * FROM Customers WHERE name='Tan Ah Teck'), el motor de la base de datos debe comparar todos los registros de la tabla. Un índice especializado (por ejemplo, en la estructura BTREE) podría alcanzar el registro sin comparar todos los registros. Sin embargo, el índice debe reconstruirse cada vez que se cambia un registro, lo que resulta en una sobrecarga asociada con el uso de índices.
el índice se puede definir en una sola columna, un conjunto de columnas (llamado índice concatenado) o parte de una columna (p. ej.,, primeros 10 caracteres de un VARCHAR(100)) (llamado índice parcial). Podría crear más de un índice en una tabla. Por ejemplo, si a menudo busca un cliente utilizando customerNameo phoneNumber, puede acelerar la búsqueda creando un índice en la columna customerName, así como phoneNumber. La mayoría de RDBMS construye el índice en la clave primaria automáticamente.
referencias & recursos
última versión probada: MySQL 5.5.15
última modificación: septiembre de 2010