Indledning
Relationel database, der blev foreslået af Edgar Codd (IBM Research) omkring 1969. Det er siden blevet den dominerende databasemodel til kommercielle applikationer (i sammenligning med andre databasemodeller som hierarkiske, netværks-og objektmodeller). I dag er der mange kommercielle relationelle Database Management System (RDBMS), såsom Oracle, IBM DB2 og Microsoft s .l Server., Der er også mange gratis og open-source RDBMS, såsom MySQL, mSQL (mini-SQL) og den indbyggede JavaDB (Apache Derby).
en relationsdatabase organiserer data i tabeller (eller relationer). En tabel består af rækker og kolonner. En række kaldes også en rekord (eller tupel). En kolonne kaldes også et felt (eller attribut). En databasetabel ligner et regneark. De forhold, der kan oprettes mellem tabellerne, gør det imidlertid muligt for en relationsdatabase effektivt at gemme enorme mængder data og effektivt hente valgte data.,
et sprog kaldet S .l (Structured Languageuery Language) blev udviklet til at arbejde med relationelle databaser.
Databasedesignmål
en veldesignet database skal:
- eliminere dataredundans: det samme stykke data må ikke gemmes på mere end .t sted. Dette skyldes, at duplikatdata ikke kun lagerrum til affald, men også let fører til uoverensstemmelser.
- sørg for dataintegritet og nøjagtighed:
- mere
Relationsdatabasedesignproces
databasedesign er mere kunst end videnskab, da du skal tage mange beslutninger., Databaser er normalt tilpasset til at passe til en bestemt applikation. Ikke to tilpassede applikationer er ens, og derfor ikke to database er ens. Retningslinjer (normalt med hensyn til hvad man ikke skal gøre i stedet for hvad man skal gøre) er fastsat i at gøre disse design beslutning, men de valg i sidste ende hvile på dig – designeren.
Trin 1: Definer formålet med databasen (kravanalyse)
Saml kravene og definer formålet med din database, f .eks…udarbejdelse af eksempler på inputformularer, forespørgsler og rapporter hjælper ofte.,
Trin 2: Saml Data, Organiser i tabeller og angiv de primære nøgler
Når du har besluttet formålet med databasen, skal du samle de data, der skal gemmes i databasen. Opdel dataene i emnebaserede tabeller.
vælg en kolonne (eller et par kolonner) som den såkaldte primære nøgle, som entydigt identificerer hver af rækkerne.
primær nøgle
i den relationelle model kan en tabel ikke indeholde dublerede rækker, fordi det ville skabe tvetydigheder i hentning., For at sikre unikhed skal hver tabel have en kolonne (eller et sæt kolonner), kaldet primærnøgle, der entydigt identificerer alle poster i tabellen. For eksempel, et unikt nummer customerID kan bruges som den primære nøgle til den Customers tabelposition>>; productCode for Products tabelposition>>; isbn for Books tabel. En primær nøgle kaldes en simpel nøgle, hvis det er en enkelt kolonne; det kaldes en sammensat nøgle, hvis den består af flere kolonner.,
de fleste RDBMSs bygger et indeks på den primære nøgle for at lette hurtig søgning og hentning.
den primære nøgle bruges også til at henvise til andre tabeller (skal uddybes senere).
Du skal beslutte, hvilke kolonner der skal bruges til primær nøgle. Beslutningen må ikke være ligetil, men den primære nøgle skal have disse egenskaber:
- værdierne for primær nøgle skal være unikke (dvs.ingen dobbeltværdi)., For eksempel er
customerNamemuligvis ikke egnet til at blive brugt som den primære nøgle til tabellenCustomers, da der kunne være to kunder med samme navn. - den primære nøgle skal altid have en værdi. Det må med andre ord ikke indeholde NULL.
Overvej følgende vælg den primære nøgle:
- Den primære nøgle, skal være enkle og velkendte, fx,
employeeIDforemployeestabelposition > > ogisbnforbookstabel., - værdien af den primære nøgle bør ikke ændres. Primær nøgle bruges til at henvise til andre tabeller. Hvis du ændrer dens værdi, skal du ændre alle dens referencer; ellers vil referencerne gå tabt. For eksempel er
phoneNumbermuligvis ikke egnet til at blive brugt som primær nøgle til tabelCustomers, da det kan ændre sig. - primær nøgle bruger ofte heltal (eller tal) type. Men det kan også være andre typer, såsom tekster. Det er dog bedst at bruge numerisk kolonne som primær nøgle til effektivitet.
- primær nøgle kan tage et vilkårligt tal., De fleste rdbmss understøtter såkaldt auto-increment (eller
AutoNumbertype) For integer primary key, hvor (aktuel maksimal værdi + 1) er tildelt den nye post. Dette vilkårlige antal er faktisk mindre, da det ikke indeholder nogen faktuelle oplysninger. I modsætning til faktuelle oplysninger såsom telefonnummer, fact-less nummer er ideel til primær nøgle, da det ikke ændrer sig. - Primær nøgle er normalt en enkelt kolonne (for eksempel,
customerIDellerproductCode). Men det kunne også udgøre flere kolonner. Du skal bruge så få kolonner som muligt.,
Let’s illustrate with an example: a table customers contains columns lastName, firstName, phoneNumber, address, city, state, zipCode. The candidates for primary key are name=(lastName, firstName), phoneNumber, Address1=(address, city, state), Address1=(address, zipCode). Name may not be unique. Phone number and address may change., Derfor er det bedre at oprette et faktumfrit auto-inkrementnummer, siger customerID, som den primære nøgle.
Trin 3: Opret relationer mellem tabeller
en database bestående af uafhængige og uafhængige tabeller tjener lidt formål (du kan overveje at bruge et regneark i stedet). Kraften i relationel database ligger i forholdet, der kan defineres mellem tabeller. Det mest afgørende aspekt ved udformningen af en relationel database er at identificere forholdet mellem tabeller., De typer af forhold er:
- et-til-mange –
- mange-til-mange –
- et-til-et –
En-til-Mange –
I en “klasse ” roster” database, en lærer, der kan undervise i nul eller flere klasser, og en klasse undervises af én (og kun én) lærer. I en” virksomhed ” – database administrerer en manager nul eller flere ansatte, mens en medarbejder administreres af en (og kun en) leder. I en” Produktsalg ” database, kan en kunde placere mange ordrer; mens en ordre er placeret af en bestemt kunde. Denne form for forhold er kendt som en-til-mange.,
et-til-mange forhold kan ikke repræsenteres i en enkelt tabel. For eksempel, du i en “klasse ” roster” database, vi kan begynde med en tabel, som hedder Teachers, som gemmer oplysninger om lærere (som f.eks. name office phone og email). Til at gemme de klasser, der undervises af hver enkelt lærer, vi kunne oprette kolonner class1 class2 class3, men står over for et problem umiddelbart på, hvor mange kolonner for at skabe., På den anden side, hvis vi begynder med en tabel, som hedder Classes, som gemmer oplysninger om en klasse (courseCode dayOfWeek timeStart og timeEnd); vi kunne skabe yderligere kolonner til at gemme oplysninger om (en) læreren (som f.eks. name office phone og email). Men da en lærer kan undervise i mange klasser, vil dens data blive duplikeret i mange rækker i tabel Classes.,
for At støtte en en-til-mange-relation, er vi nødt til at designe to tabeller: en tabel Classes for at gemme oplysninger om klasser med classID som den primære nøgle, og en tabel Teachers for at gemme oplysninger om lærere med teacherID som den primære nøgle. Vi kan derefter oprette en-til-mange-forholdet ved at gemme den primære nøgle i tabellen Teacher (dvs .,, teacherID) (den ” ene ” – ende eller forældertabellen) i tabellen classes (“mange”-slutningen eller barnetabellen), som illustreret nedenfor.
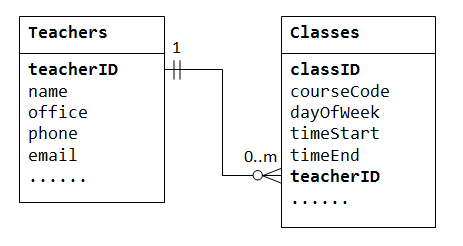
Den kolonne teacherID i den underordnede tabel Classes er kendt som den fremmede nøgle. En fremmed nøgle i et børnebord er en primær nøgle i en forældrebord, der bruges til at henvise til forældrebordet.
Vær opmærksom på, at der for hver værdi i forældertabellen kan være nul, en eller flere rækker i barnetabellen., For hver værdi i barnetabellen er der en og kun en række i forældretabellen.
mange-til-mange
i en “Produktsalg” – database kan en kundes ordre indeholde et eller flere produkter; og et produkt kan vises i mange ordrer. I en” boghandel ” database, en bog er skrevet af en eller flere forfattere; mens en forfatter kan skrive nul eller flere bøger. Denne form for forhold er kendt som mange-til-mange.
lad os illustrere med en “Produktsalg” database. Vi begynder med to tabeller: Products og Orders., Tabellen products, der indeholder oplysninger om produkter (som f.eks. name description og quantityInStock) med productID som sin primære nøgle. Tabellen orders indeholder kundens ordrer (customerID dateOrdered dateRequired og status). Igen kan vi ikke gemme de bestilte varer i tabellen Orders, da vi ikke ved, hvor mange kolonner der skal reserveres til varerne., Vi kan heller ikke gemme ordreoplysningerne i tabellen Products.
for At støtte mange-til-mange-relation, er vi nødt til at oprette en tredje tabel (kaldet en junction tabel), siger OrderDetails (eller OrderLines), hvor hver række repræsenterer et element af en bestemt rækkefølge. For det OrderDetails tabellen, er den primære nøgle består af to kolonner: orderID og productID, der entydigt identificerer hver række., Kolonner orderID og productID i OrderDetails table bruges til at henvise Orders og Products tabeller, og derfor er de også de fremmede nøgler i OrderDetails tabel.
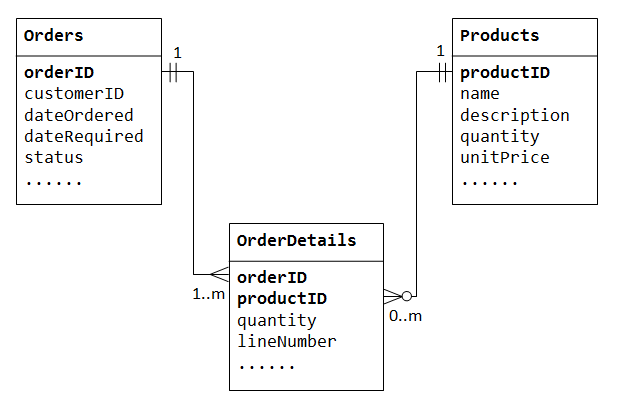
det mange-til-mange forhold er faktisk implementeret som to en-til-mange relationer med introduktionen af krydstabellen.
- en ordre har mange varer i
OrderDetails. EtOrderDetailselement tilhører en bestemt rækkefølge., - et produkt kan forekomme i mange
OrderDetails. HverOrderDetailsvare angivet et produkt.
En-til-En –
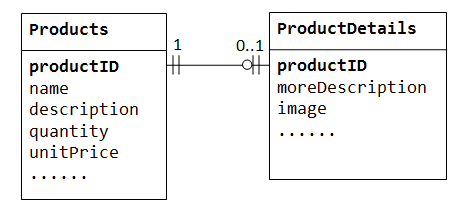
I et “salg af produkter” database, et produkt har valgfri supplerende oplysninger, som f.eks. image moreDescription og comment. At holde dem inde iProducts tabel resulterer i mange tomme rum (i disse poster uden disse valgfrie data). Desuden kan disse store data forringe databasens ydeevne.,
i Stedet, kan vi skabe en anden tabel (siger ProductDetails ProductLines eller ProductExtras) til at gemme den valgfrie data. Der oprettes kun en post for disse produkter med valgfri data. De to tabeller, Products og ProductDetails, udviser et en-til-en-forhold. Det vil sige, for hver række i forældrebordet er der højst en række (muligvis nul) i barnebordet. Den samme kolonne productID skal bruges som den primære nøgle til begge tabeller.,
nogle databaser begrænser antallet af kolonner, der kan oprettes i en tabel. Du kan bruge et en-til-en-forhold til at opdele dataene i to tabeller. En-til-en-forhold er også nyttigt til lagring af visse følsomme data i en sikker tabel, mens de ikke-følsomme i hovedtabellen.
kolonne datatyper
Du skal vælge en passende datatype for hver kolonne. Almindeligt datatyper omfatter: heltal, floating-point tal, streng (eller tekst), dato/tid, binær, indsamling (såsom optælling og sæt).,
Trin 4: Forfine & Normalisere Design
For eksempel:
- tilføje flere kolonner,
- opret en ny tabel, der for valgfri data ved hjælp af en-til-en-forhold,
- split, et stort bord til to mindre borde,
- andre.
normalisering
Anvend de såkaldte normaliseringsregler for at kontrollere, om din database er strukturelt korrekt og optimal.
første normale Form (1NF): en tabel er 1NF, hvis hver celle indeholder en enkelt værdi, ikke en liste over værdier. Denne egenskaber er kendt som atomic., 1NF forbyder også gentagende gruppe af kolonner som item1, item2,.., itemN. I stedet, du skal oprette en anden tabel ved hjælp af en-til-mange forhold.
anden Normal Form (2NF): en tabel er 2NF, hvis den er 1NF, og hver ikke-nøglekolonne er helt afhængig af den primære nøgle. Hvis den primære nøgle består af flere kolonner, skal hver ikke-nøglekolonne desuden afhænge af hele sættet og ikke en del af det.,
For eksempel, den primære nøgle i OrderDetails tabellen omfatter orderID og productID. Hvis unitPrice kun er afhængig af productID, må den ikke opbevares i OrderDetails tabellen (men i Products tabellen). På den anden side, hvis unitPrice er afhængig af produktet såvel som den særlige rækkefølge, skal den opbevares i OrderDetails tabel.,
tredje Normal Form (3NF): en tabel er 3NF, hvis den er 2NF, og de ikke-nøglekolonner er uafhængige af hinanden. Med andre ord er de ikke-nøglekolonner afhængige af primærnøgle, kun på den primære nøgle og intet andet. For eksempel, lad os antage, at vi har en Products tabel med kolonner productID (primær nøgle), name og unitPrice., Kolonnen discountRate skal ikke tilhører Products tabel, hvis den er også afhængig af unitPrice, som ikke er en del af den primære nøgle.
Højere normalform: 3NF har sine mangler, hvilket fører til højere normalform, såsom Boyce/Codd Normal form, Fjerde normalform (4NF) og Femte normalform (5NF), som ligger uden for rammerne af denne vejledning.
til tider kan du beslutte at bryde nogle af normaliseringsreglerne af præstationsårsag (f. eks., oprette en kolonne kaldet totalPrice i Orders tabel, der kan udledes fra orderDetails poster); eller fordi slutbrugeren har anmodet om det. Sørg for, at du fuldt ud klar over det, udvikle programmering logik til at håndtere det, og korrekt dokumentere beslutningen.
Integritetsregler
Du bør også anvende integritetsreglerne for at kontrollere integriteten af dit design:
Enhedsintegritetsregel: den primære nøgle kan ikke indeholde NULL. Ellers kan den ikke entydigt identificere rækken., For sammensat nøgle, der består af flere kolonner, kan ingen af kolonnen indeholde NULL. De fleste af RDBMS kontrollerer og håndhæver denne regel.regel om Referenceintegritet: hver fremmed nøgleværdi skal matches med en primær nøgleværdi i den refererede tabel (eller overordnet tabel).
- du kan kun indsætte en række med en fremmed nøgle i barnetabellen, hvis værdien findes i overordnet tabel.
- hvis værdien af nøglen ændres i overordnet tabel(f.eks. rækken opdateret eller slettet), skal alle rækker med denne fremmede nøgle i barnetabellen / – tabellerne håndteres i overensstemmelse hermed., Du kan enten (a) afvise ændringerne; (B) kaskade ændringen (eller slette posterne) i barnetabellerne i overensstemmelse hermed; (c) Indstil nøgleværdien i barnetabellerne til NULL.
de fleste RDBMS kan indstilles til at udføre kontrollen og sikre den referencemæssige integritet på den angivne måde.
Forretningslogikintegritet: ud over ovenstående to generelle integritetsregler kan der være integritet (Validering) vedrørende forretningslogikken, f. eks.,, Postnummer skal være 5-cifret inden for et bestemt interval, leveringsdato og klokkeslæt skal falde i åbningstiden; bestilte mængde skal være lig med eller mindre end mængden på lager osv. Disse kunne udføres i valideringsregel (for den specifikke kolonne) eller programmeringslogik.
Kolonneindeksering
Du kan oprette indeks på udvalgte kolonner for at lette datasøgning og hentning. Et indeks er en struktureret fil, der fremskynder adgang til data for SELECT, men kan sinke INSERT UPDATE og DELETE., Uden en indeksstruktur skal databasemotoren for at behandle en SELECT forespørgsel med et matchende kriterium (f.eks. SELECT * FROM Customers WHERE name='Tan Ah Teck') sammenligne alle poster i tabellen. En specialiseret indeks (f.i BTREE struktur) kunne nå posten uden at sammenligne alle poster. Indekset skal dog genopbygges, når en post ændres, hvilket resulterer i overhead forbundet med at bruge indekser.
indeks kan defineres på en enkelt kolonne, et sæt af kolonner (kaldet sammenkædet indeks), eller en del af en kolonne (f. eks,, første 10 tegn af en VARCHAR(100)) (kaldet partielt indeks) . Du kunne bygge mere end et indeks i en tabel. For eksempel, hvis du ofte søge efter en kunde, der bruger enten customerName eller phoneNumber, kan du fremskynde søgningen ved at bygge et indeks på kolonne customerName samt phoneNumber. De fleste RDBMS bygger indeks på den primære nøgle automatisk.
HENVISNINGER & RESSOURCER
Seneste version testet: MySQL 5.5.15
Sidst ændret: September, 2010