Úvod
Relační databáze byla navržena Edgar Codd (IBM Research) kolem roku 1969. Od té doby se stala dominantní model databáze pro komerční aplikace (ve srovnání s jiných databázových modelů, například hierarchický, síťový a objektových modelů). Dnes existuje mnoho komerčních relačních databázových systémů (RDBMS), jako jsou Oracle, IBM DB2 a Microsoft SQL Server., Existuje také mnoho bezplatných a open-source RDBM, jako je MySQL, mSQL (mini-SQL) a embedded JavaDB (Apache Derby).
relační databáze organizuje data v tabulkách (nebo relacích). Tabulka se skládá z řádků a sloupců. Řádek se také nazývá záznam (nebo nuple). Sloupec se také nazývá pole (nebo atribut). Databázová tabulka je podobná tabulce. Vztahy, které lze vytvořit mezi tabulkami, však umožňují relační databázi efektivně ukládat obrovské množství dat a efektivně načítat vybraná data.,
byl vyvinut jazyk SQL (Structured Query Language) pro práci s relačními databázemi.
cíl návrhu databáze
dobře navržená databáze musí:
- eliminovat redundanci dat: stejná data nesmí být uložena na více než jednom místě. Důvodem je, že duplicitní data nejen úložné prostory odpadu, ale také snadno vedou k nesrovnalostem.
- zajistěte integritu a přesnost dat:
- více
proces návrhu relační databáze
návrh databáze je více umění než věda, protože musíte učinit mnoho rozhodnutí., Databáze jsou obvykle přizpůsobeny tak, aby vyhovovaly konkrétní aplikaci. Žádné dvě přizpůsobené aplikace nejsou stejné, a proto nejsou žádné dvě databáze podobné. Pokyny (obvykle z hlediska toho, co nedělat místo toho, co dělat) jsou poskytovány při rozhodování o návrhu, ale volby nakonec spočívají na vás – designérovi.
Krok 1: Definujte účel databáze (Analýza požadavků)
Shromážděte požadavky a definujte cíl vaší databáze, např…
vypracování vzorových vstupních formulářů, dotazů a zpráv často pomáhá.,
Krok 2: Shromážděte Data, uspořádejte do tabulek a zadejte primární klíče
jakmile se rozhodnete pro účel databáze, shromážděte data, která jsou potřebná k uložení do databáze. Rozdělte data do tabulek založených na předmětu.
vyberte jeden sloupec (nebo několik sloupců) jako takzvaný primární klíč, který jedinečně identifikuje každý z řádků.
primární klíč
v relačním modelu nemůže tabulka obsahovat duplicitní řádky, protože by to vytvořilo nejasnosti při vyhledávání., Pro zajištění jedinečnosti by každá tabulka měla mít sloupec (nebo sadu sloupců), nazvaný primární klíč, který jedinečně identifikuje všechny záznamy tabulky. Například jedinečné číslo customerID mohou být použity jako primární klíč pro Customers tabulka; productCode Products tabulka; isbn Books tabulka. Primární klíč se nazývá jednoduchý klíč, pokud se jedná o jeden sloupec; nazývá se kompozitní klíč, pokud se skládá z několika sloupců.,
většina RDBMSs vytváří index na primárním klíči pro usnadnění rychlého vyhledávání a vyhledávání.
primární klíč se také používá k odkazu na jiné tabulky (které mají být zpracovány později).
musíte se rozhodnout, který sloupec(sloupce) má být použit pro primární klíč. Rozhodnutí nemusí být přímočará, ale primární klíč musí mít tyto vlastnosti:
- hodnoty primárního klíče musí být unikátní (tj. žádné duplicitní hodnoty)., Například
customerNamenemusí být vhodné použít jako primární klíč proCustomerstabulky, protože tam by mohlo být dva zákazníci se stejným jménem. - primární klíč musí mít vždy hodnotu. Jinými slovy, nesmí obsahovat NULL.
Zvažte následující při výběru primární klíč:
- primární klíč musí být jednoduché a známé, např.
employeeIDemployeestabulkaisbnbookstabulka., - hodnota primárního klíče by se neměla měnit. Primární klíč se používá k odkazu na jiné tabulky. Pokud změníte jeho hodnotu, musíte změnit všechny její odkazy; v opačném případě budou odkazy ztraceny. Například
phoneNumbernemusí být vhodné použít jako primární klíč pro tabulkuCustomers, protože by to mohlo změnit. - primární klíč často používá celé číslo (nebo číslo) typ. Ale mohou to být i jiné typy, jako jsou texty. Nicméně, to je nejlepší použít číselný sloupec jako primární klíč pro efektivitu.
- primární klíč může mít libovolné číslo., Většina RDBMSs podporu tzv. auto-přírůstek (nebo
AutoNumbertypu) pro integer primary key, kde (aktuální maximální hodnota + 1) je přiřazen nový rekord. Toto libovolné číslo je bez faktů, protože neobsahuje žádné faktické informace. Na rozdíl od faktických informací, jako je telefonní číslo, je číslo bez faktů ideální pro primární klíč, protože se nemění. - Primární klíč je obvykle jeden sloupec (např.
customerIDneboproductCode). Může ale tvořit i několik sloupců. Měli byste použít co nejméně sloupců.,
Let’s illustrate with an example: a table customers contains columns lastName, firstName, phoneNumber, address, city, state, zipCode. The candidates for primary key are name=(lastName, firstName), phoneNumber, Address1=(address, city, state), Address1=(address, zipCode). Name may not be unique. Phone number and address may change., Proto je lepší vytvořit číslo automatického přírůstku bez faktů, řekněme customerID, jako primární klíč.
Krok 3: Vytvořit Vztahy mezi Tabulkami
databáze se skládá z nezávislých a nesouvisejících tabulek slouží trochu účel (můžete zvážit použití tabulky místo). Síla relační databáze spočívá ve vztahu, který lze definovat mezi tabulkami. Nejdůležitějším aspektem při navrhování relační databáze je identifikace vztahů mezi tabulkami., Typy vztahu patří:
- one-to-many
- mnoho-k-mnoha
- jeden na jednoho
One-to-many
V „třídní seznam“ databáze, učitel může učit nula nebo více tříd, zatímco třída je učil jeden (a pouze jeden), učitelka. V databázi „společnosti“ manažer spravuje nula nebo více zaměstnanců, zatímco zaměstnanec je řízen jedním (a pouze jedním) manažerem. V databázi“ prodej produktů “ může zákazník zadat mnoho objednávek; zatímco objednávka je zadána jedním konkrétním zákazníkem. Tento druh vztahu je známý jako one-to-many.,
vztah One-to-many nemůže být zastoupen v jedné tabulce. Například, v „třídní seznam“ databáze, můžeme začít s tabulkou s názvem Teachers, který ukládá informace o učitelích (například name office phone email). K uložení tříd vyučuje každý učitel, můžeme vytvořit sloupce class1 class2 class3, ale čelí problém okamžitě na kolik sloupců se má vytvořit., Na druhou stranu, pokud začneme s tabulkou s názvem Classes, který ukládá informace o třídě (courseCode dayOfWeek timeStart timeEnd); mohli bychom vytvořit další sloupce ukládat informace o (jeden) učitel (například name office phone email). Protože však učitel může učit mnoho tříd, jeho data by byla duplikována v mnoha řádcích v tabulce Classes.,
Na podporu one-to-many vztah, musíme navrhnout dvě tabulky: tabulka Classes ukládat informace o třídách s classID jako primární klíč; a tabulky Teachers ukládat informace o učitelích s teacherID jako primární klíč. Pak můžeme vytvořit vztah one-to-many uložením primárního klíče tabulky Teacher (tj.,, teacherID) („jeden“-end nebo nadřazené tabulky) v tabulce classes („mnoho“-end nebo podřízené tabulky), jak je znázorněno níže.
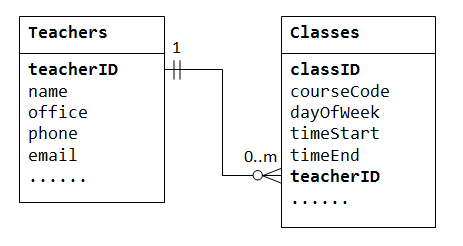
sloupec teacherID v podřízené tabulce Classes je známý jako cizí klíč. Cizí klíč dětské tabulky je primárním klíčem rodičovské tabulky, která se používá k odkazu na nadřazenou tabulku.
Vezměte na vědomí, že pro každou hodnotu v nadřazené tabulce může být v podřízené tabulce nula, jeden nebo více řádků., Pro každou hodnotu v dětské tabulce je v rodičovské tabulce jeden a pouze jeden řádek.
Many-to-Many
v databázi“ product sales “ může objednávka zákazníka obsahovat jeden nebo více produktů; a produkt se může objevit v mnoha objednávkách. V databázi „knihkupectví“ je kniha napsána jedním nebo více autory; zatímco autor může psát nula nebo více knih. Tento druh vztahu je známý jako mnoho k mnoha.
pojďme ilustrovat pomocí databáze „prodej produktů“. Začínáme dvěma tabulkami: Products a Orders., Tabulka products obsahuje údaje o produktech (např. name description quantityInStock) productID jako její primární klíč. Tabulka orders obsahuje objednávky zákazníka (customerID dateOrdered dateRequired status). Opět nemůžeme ukládat položky objednané uvnitř tabulky Orders, protože nevíme, kolik sloupců si pro položky rezervujeme., Informace o objednávce také nemůžeme uložit do tabulky Products.
podporovat mnoho-to-many vztah, potřebujeme k vytvoření třetí tabulky (nazývané spojovací tabulka), řekněme OrderDetails (nebo OrderLines), kde každý řádek představuje položku určitém pořadí. OrderDetails tabulka, primární klíč se skládá ze dvou sloupců: orderID productID, které jednoznačně identifikují každý řádek., Sloupce orderID productID OrderDetails tabulky jsou používány jako reference Orders Products tabulky, proto jsou také cizí klíče v OrderDetails tabulka.
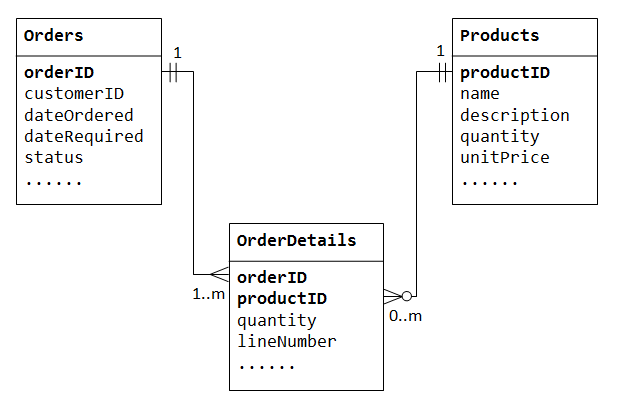
vztah mnoha k mnoha je ve skutečnosti implementován jako dva vztahy jeden k mnoha, se zavedením spojovací tabulky.
- objednávka obsahuje mnoho položek v
OrderDetails. PoložkaOrderDetailspatří k jedné konkrétní objednávce., - produkt se může objevit v mnoha
OrderDetails. KaždáOrderDetailspoložka zadala jeden produkt.
Jeden na jednoho
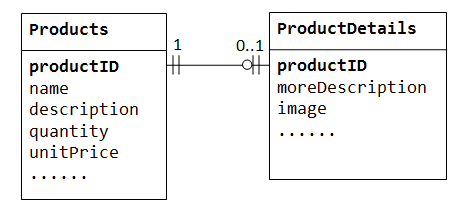
V „prodej produktů“ databáze, produkt může mít volitelné doplňkové informace, například image moreDescription comment. Jejich uchovávání uvnitř tabulkyProducts má za následek mnoho prázdných mezer (v těchto záznamech bez těchto volitelných dat). Tyto velké údaje navíc mohou zhoršit výkon databáze.,
Místo toho, můžeme vytvořit jiné tabulky (řekněme ProductDetails ProductLines nebo ProductExtras) ukládat údaje nepovinné. Záznam bude vytvořen pouze pro tyto produkty s volitelnými údaji. Dvě tabulky, Products a ProductDetails, vykazují vztah one-to-one. To znamená, že pro každý řádek v rodičovské tabulce je v dětské tabulce nejvýše jeden řádek (možná nula). Stejný sloupec productID by měl být použit jako primární klíč pro obě tabulky.,
některé databáze omezují počet sloupců, které lze vytvořit uvnitř tabulky. Dalo by se použít vztah one-to-one rozdělit data do dvou tabulek. Vztah One-to-one je také užitečný pro ukládání určitých citlivých dat do zabezpečené tabulky, zatímco citlivých v hlavní tabulce.
datové typy sloupců
pro každý sloupec musíte zvolit vhodný typ dat. Běžně datové typy patří: celá čísla, čísla s plovoucí desetinnou čárkou, řetězec (nebo text), datum/čas, binární, kolekce (například výčet a nastavit).,
Krok 4: Upřesnění & Normalizovat Design
například,
- přidání více sloupců,
- vytvořit novou tabulku pro nepovinné údaje pomocí one-to-one vztah,
- rozdělit velký stůl na dva menší stoly,
- ostatní.
normalizace
použijte tzv. normalizační pravidla ke kontrole, zda je vaše databáze strukturálně správná a optimální.
první normální forma (1NF): tabulka je 1NF, pokud každá buňka obsahuje jednu hodnotu, nikoli seznam hodnot. Tyto vlastnosti jsou známé jako atomové., 1NF také zakazuje opakování skupiny sloupců, jako je item1, item2,.., itemN. Namísto, měli byste vytvořit další tabulku pomocí one-to-many vztah.
druhá normální forma (2NF): tabulka je 2NF, pokud je 1NF a každý sloupec bez klíče je plně závislý na primárním klíči. Kromě toho, pokud je primární klíč tvořen několika sloupci, musí každý sloupec, který není klíčem, záviset na celé sadě a nikoli na její části.,
například, primární klíč OrderDetails tabulka obsahující orderID productID. Pokud unitPrice je závislá pouze productID, nesmí být v OrderDetails table (ale v Products tabulka). Na druhou stranu, pokud je unitPrice závislá na produktu a konkrétním pořadí, musí být uchovávána v tabulce OrderDetails.,
třetí normální forma (3NF): tabulka je 3NF, pokud je 2NF a sloupce bez klíče jsou na sobě nezávislé. Jinými slovy, sloupce bez klíče jsou závislé na primárním klíči, pouze na primárním klíči a nic jiného. Předpokládejme například, že máme Products tabulka s sloupce productID (primární klíč), name unitPrice., Sloupec discountRate nesmí patřit do Products tabulky, pokud je také závislá na unitPrice, který není součástí primárního klíče.
Vyšší Normální Formě: 3NF má své nedostatky, což vede k vyšší Normální formě, jako Boyce/Coddova Normální forma, Čtvrtá Normální Forma (4NF) a Pátá Normální Forma (5NF), což je nad rámec tohoto tutoriálu.
občas se můžete rozhodnout porušit některá normalizační pravidla z důvodu výkonu (např., vytvořte sloupec s názvem totalPrice Orders tabulky, které mohou být odvozeny z orderDetails záznamy); nebo proto, že koncový uživatel požádal. Ujistěte se, že jste plně vědomi, rozvíjet logické programování zvládnout a správně dokumentovat rozhodnutí.
pravidla Integrity
měli byste také použít pravidla integrity pro kontrolu integrity vašeho návrhu:
pravidlo integrity Entity: primární klíč nemůže obsahovat NULL. V opačném případě nemůže jednoznačně identifikovat řádek., U kompozitního klíče složeného z několika sloupců nemůže žádný sloupec obsahovat NULL. Většina RDBMS kontroluje a prosazuje toto pravidlo.
referenční pravidlo Integrity: každá hodnota cizího klíče musí být přiřazena k primární hodnotě klíče v odkazované tabulce (nebo nadřazené tabulce).
- do tabulky dítě můžete vložit řádek s cizím klíčem pouze v případě, že hodnota existuje v nadřazené tabulce.
- Pokud je hodnota klíčové změny v nadřazené tabulce (např. na řádku aktualizovány nebo odstraněny), všechny řádky s cizí klíč v podřízené tabulce(y) musí být řešeny odpovídajícím způsobem., Můžete buď (a) zakázat změny; (b) cascade změna (nebo odstranit záznamy) v podřízené tabulky odpovídajícím způsobem; (c) nastavte hodnotu klíče v podřízené tabulky na NULL.
většina RDBM může být nastavena tak, aby provedla kontrolu a zajistila referenční integritu zadaným způsobem.
integrita obchodní logiky: vedle výše uvedených dvou obecných pravidel integrity by mohla existovat integrita (validace) týkající se obchodní logiky, např.,, PSČ musí být 5-místný v určitých rozsazích, dodací lhůta a čas musí klesnout v pracovní době; objednané množství musí být stejné nebo menší než množství na skladě, atd. Ty by mohly být prováděny ve validačním pravidle (pro konkrétní sloupec) nebo programovací logice.
indexování sloupců
na vybraných sloupcích můžete vytvořit index pro usnadnění vyhledávání a vyhledávání dat. Index je strukturovaný soubor, který urychluje přístup k datům pro SELECT, ale může zpomalit INSERT UPDATE DELETE., Bez indexu struktury, procesu SELECT dotaz s odpovídající kritérium (např. SELECT * FROM Customers WHERE name='Tan Ah Teck'), databáze motor potřebuje porovnat všechny záznamy v tabulce. Specializovaný index (např. ve struktuře BTREE) by mohl dosáhnout rekordu bez porovnání všech záznamů. Index je však třeba znovu sestavit, kdykoli se změní záznam, což má za následek režii spojenou s použitím indexů.
Index lze definovat na jednom sloupci, souboru sloupců (nazývaných zřetězený index) nebo části sloupce (např.,, prvních 10 znaků VARCHAR(100)) (tzv. částečný index). Dalo by se postavit více než jeden index v tabulce. Například, pokud jste často vyhledávání pro zákazníka buď pomocí customerName nebo phoneNumber, můžete urychlit vyhledávání podle stavebních index na sloupec customerName i phoneNumber. Většina RDBMS staví index na primárním klíči automaticky.
ODKAZY & ZDROJE
Nejnovější verze testováno: MySQL 5.5.15
Last modified: září 2010