
ofta när jag pratar med organisationer som vill implementera datavetenskap i sina processer frågar de ofta frågan: ”Hur får jag den mest exakta modellen?”. Och jag frågade vidare, ” vilken affärsutmaning försöker du lösa med modellen?,”och jag kommer att få det förbryllande utseendet eftersom frågan som jag ställde inte riktigt svarar på deras fråga. Jag måste då förklara varför jag ställde frågan innan vi börjar utforska om noggrannhet är be-all Och end-all modell metric som vi ska välja vår ”bästa” modell från.
så jag trodde att jag kommer att förklara i det här blogginlägget att noggrannhet inte behöver vara den enda modellen mätvärden Dataforskare jaga och inkludera enkel förklaring av andra mätvärden också.
låt oss först titta på följande förvirringsmatris. Vad är noggrannheten för modellen?,

mycket enkelt kommer du att märka att noggrannheten för denna modell är mycket hög, vid 99,9%!! Wow! Du har Jackpot och holy grail (*skrika och springa runt i rummet, pumpa näven i luften flera gånger*)!
men….(väl du vet att detta kommer rätt?) vad händer om jag nämnde att det positiva här är faktiskt någon som är sjuk och bär ett virus som kan spridas mycket snabbt?, Eller det positiva här representerar ett bedrägerifall? Eller den positiva här representerar terrorist som modellen säger att det är en icke-terrorist? Du fattar. Kostnaderna för att ha ett felaktigt klassificerat faktiskt positivt (eller falskt negativt) är mycket höga här under dessa tre omständigheter som jag ställde.
OK, så nu insåg du att noggrannhet inte är be-all Och end-all modell metric att använda när du väljer den bästa modellen…nu vad?
låt mig presentera två nya mätvärden (om du inte har hört talas om det och om du gör det, kanske bara humor mig lite och fortsätt läsa?, : D)
Så om du tittar på Wikipedia ser du att formeln för beräkning av Precision och återkallelse är som följer:
Låt mig lägga den här för ytterligare förklaring.

Låt mig lägga in förvirringsmatrisen och dess delar här.
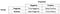
Precision
bra!, Låt oss nu titta på Precision först.

vad märker du för nämnaren? Nämnaren är faktiskt den totala förutspådda positiva!, So the formula becomes


Immediately, you can see that Precision talks about how precise/accurate your model is out of those predicted positive, how many of them are actual positive.,
Precision är en bra åtgärd för att bestämma, när kostnaderna för falskt positivt är höga. Till exempel, e-post spam upptäckt. Vid upptäckt av skräppost innebär ett falskt positivt att ett e-postmeddelande som inte är spam (faktiskt negativt) har identifierats som skräppost (förväntat skräppost). E-postanvändaren kan förlora viktiga e-postmeddelanden om precisionen inte är hög för skräppostdetekteringsmodellen.
Recall
så låt oss tillämpa samma logik för återkallelse. Minns hur återkallelse beräknas.,


There you go! So Recall actually calculates how many of the Actual Positives our model capture through labeling it as Positive (True Positive)., Med samma förståelse vet vi att återkallelse ska vara det modellmått vi använder för att välja vår bästa modell när det finns en hög kostnad i samband med falskt negativt.
till exempel vid upptäckt av bedrägeri eller upptäckt av sjuka patienter. Om en bedräglig transaktion (faktisk positiv) förutspås som icke-bedräglig (förutsagd negativ) kan konsekvensen vara mycket dålig för banken.
På samma sätt, vid sjuk patientdetektering. Om en sjuk patient (faktisk positiv) går igenom testet och förutspås inte vara sjuk (förutsagd negativ)., Kostnaden i samband med falskt negativt kommer att vara extremt hög om sjukdomen är smittsam.
F1-poäng
Nu om du läser mycket annan litteratur om Precision och återkallelse, kan du inte undvika den andra åtgärden, F1 som är en funktion av Precision och återkallelse. Om man tittar på Wikipedia är formeln följande:

poäng behövs när du vill söka balans mellan precision och återkallelse., Right…so vad är skillnaden mellan F1-poäng och noggrannhet då? Vi har tidigare sett att noggrannhet i stor utsträckning kan bidra med ett stort antal sanna negativ som i de flesta affärsförhållanden fokuserar vi inte mycket på, medan falskt negativa och falska positiva vanligtvis har affärskostnader (påtagliga & immateriella) så F1-poäng kan vara en bättre åtgärd att använda om vi behöver söka en balans mellan Precision och återkallelse och det finns en ojämn klassfördelning (stort antal faktiska negativ).,
Jag hoppas att förklaringen kommer att hjälpa dem som börjar med datavetenskap och arbetar med klassificeringsproblem, att noggrannhet inte alltid kommer att vara metrisk för att välja den bästa modellen från.
Obs! överväg att registrera dig för mitt nyhetsbrev eller gå till min webbplats för det senaste.
Jag önskar alla läsare en rolig datavetenskaplig inlärningsresa.