
ofte når jeg taler med organisationer, der søger at implementere datavidenskab i deres processer, stiller de ofte spørgsmålet: “Hvordan får jeg den mest nøjagtige model?”. Og jeg spurgte videre, ” Hvilken forretningsudfordring forsøger du at løse ved hjælp af modellen?,”og jeg vil få det forvirrende udseende, fordi det spørgsmål, jeg stillede, ikke rigtig svarer på deres spørgsmål. Jeg bliver derefter nødt til at forklare, hvorfor jeg stillede spørgsmålet, før vi begynder at undersøge, om nøjagtigheden er den be-all og end-all model metrisk, som vi skal vælge vores “bedste” model fra.
så jeg troede, at jeg vil forklare i dette blogindlæg, at nøjagtighed ikke behøver at være den eneste model metrics data forskere chase og inkludere simpel forklaring af andre målinger også.
lad os først se på følgende forvirringsmatri.. Hvad er nøjagtigheden for modellen?,

Meget let, vil du bemærke, at nøjagtigheden for denne model er meget meget høj, på 99,9%!! Wowo!! Du har ramt jackpot og hellige gral (*skrige og løbe rundt i lokalet, pumpe knytnæve i luften flere gange*)!
men….(nå ved du, at dette kommer rigtigt?) hvad hvis jeg nævnte, at den positive herovre faktisk er en, der er syg og bærer en virus, der kan sprede sig meget hurtigt?, Eller den positive her repræsenterer en bedrageri sag? Eller den positive her repræsenterer terrorist, at modellen siger, at det er en ikke-terrorist? Nå, Du får ideen. Omkostningerne ved at have en forkert klassificeret faktisk positiv (eller falsk negativ) er meget høje her under disse tre omstændigheder, som jeg stillede.
OK, så nu indså du, at nøjagtighed ikke er den be-all og end-all model metrisk, der skal bruges, når du vælger den bedste model … hvad nu?
Lad mig introducere to nye målinger (hvis du ikke har hørt om det, og hvis du gør det, måske bare humor mig lidt og fortsæt med at læse?, : D)
så hvis du ser på .ikipedia, vil du se, at formlen til beregning af præcision og tilbagekaldelse er som følger:
Lad mig sætte det her for yderligere forklaring.

Lad mig sætte i forvirring matrix og dens dele her.
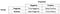
Præcision
Store!, Lad os nu se på præcision først.

Hvad lægger du mærke til dem? Nævneren er faktisk den samlede forudsagte Positive!, So the formula becomes


Immediately, you can see that Precision talks about how precise/accurate your model is out of those predicted positive, how many of them are actual positive.,
præcision er en god foranstaltning til at bestemme, når omkostningerne ved falsk positiv er høje. For eksempel, E-mail spam afsløring. I e-mail-spam-detektion betyder en falsk positiv, at en e-mail, der ikke er spam (faktisk negativ), er blevet identificeret som spam (forudsagt spam). E-mail-brugeren kan miste vigtige e-mails, hvis præcisionen ikke er høj for spam detection model.
Recall
så lad os anvende den samme logik for tilbagekaldelse. Husk, hvordan tilbagekaldelse beregnes.,


There you go! So Recall actually calculates how many of the Actual Positives our model capture through labeling it as Positive (True Positive)., Anvendelse af den samme forståelse, vi ved, at tilbagekaldelse skal være den model metriske vi bruger til at vælge vores bedste model, når der er en høj pris forbundet med falsk negativ.
For eksempel ved afsløring af svig eller påvisning af syge patienter. Hvis en svigagtig transaktion (faktisk positiv) forudsiges som ikke-svigagtig (forudsagt negativ), kan konsekvensen være meget dårlig for banken.
tilsvarende ved påvisning af syge patienter. Hvis en syg patient (faktisk positiv) gennemgår testen og forudsiges som ikke syg (forudsagt negativ)., Omkostningerne forbundet med falsk negativ vil være ekstremt høje, hvis sygdommen er smitsom.
F1 Score
nu, hvis du læser en masse anden litteratur om præcision og tilbagekaldelse, kan du ikke undgå den anden foranstaltning, F1, som er en funktion af præcision og tilbagekaldelse. Kigger på Wikipedia, formlen er som følger:

F1 Score er nødvendig, når du ønsker at finde en balance mellem Præcision og Recall., Right…so hvad er forskellen mellem F1 Score og nøjagtighed så? Vi har tidligere set, at nøjagtigheden kan være i høj grad bidraget med et stort antal Sande Negative, som i de fleste forretningsmæssige forhold, vi ikke fokusere på meget henviser til, Falsk Negative og Falsk Positive normalt har virksomhedernes omkostninger (materielle & immaterielle), således at F1-Score kan være et bedre mål, du vil bruge hvis vi skal til at finde en balance mellem Præcision og Recall, OG der er en ujævn klasse distribution (stort antal af de Faktiske Negativer).,
Jeg håber, at forklaringen vil hjælpe dem, der starter med datavidenskab og arbejder med Klassificeringsproblemer, at nøjagtighed ikke altid vil være metrisk for at vælge den bedste model fra.
Bemærk: overvej at tilmelde dig mit nyhedsbrev eller gå til min hjemmeside for det nyeste.
Jeg ønsker alle læsere en sjov Datavidenskabslæringsrejse.