
Wenn ich oft mit Organisationen spreche, die Data Science in ihre Prozesse implementieren möchten, stellen sie oft die Frage: „Wie bekomme ich das genaueste Modell?”. Und ich fragte weiter: „Welche geschäftliche Herausforderung versuchen Sie mit dem Modell zu lösen?,“und ich werde den rätselhaften Blick bekommen, weil die Frage, die ich gestellt habe, ihre Frage nicht wirklich beantwortet. Ich muss dann erklären, warum ich die Frage gestellt habe, bevor wir untersuchen, ob Genauigkeit die Be-All-und End-All-Modellmetrik ist, aus der wir unser „bestes“ Modell auswählen werden.
Also dachte ich, ich werde in diesem Blogbeitrag erklären, dass Genauigkeit nicht notwendig ist, die einzigen Modellmetriken zu sein, die Datenwissenschaftler verfolgen, und auch eine einfache Erklärung anderer Metriken enthalten.
Schauen wir uns zunächst die folgende Verwirrungsmatrix an. Was ist die Genauigkeit für das Modell?,

Sehr leicht, werden Sie feststellen, dass die Genauigkeit dieses Modells ist sehr, sehr hoch, 99,9%!! Toll! Du hast den Jackpot und den heiligen Gral geknackt (*schreie und renne durch den Raum und pump die Faust mehrmals in die Luft*)!
Aber….(nun, du weißt, das kommt richtig?) was wäre, wenn ich erwähnte, dass das Positive hier drüben tatsächlich jemand ist, der krank ist und ein Virus trägt, das sich sehr schnell ausbreiten kann?, Oder stellen die Positiven hier einen Betrugsfall dar? Oder das Positive hier stellt Terrorist dar, dass das Modell sagt, dass es ein Nicht-Terrorist ist? Nun, Sie bekommen die Idee. Die Kosten für ein falsch klassifiziertes tatsächliches Positives (oder falsch negatives) sind hier unter diesen drei von mir gestellten Umständen sehr hoch.
OK, jetzt haben Sie erkannt, dass Genauigkeit nicht die Be-All-und End-All-Modellmetrik ist, die bei der Auswahl des besten Modells verwendet werden soll…was nun?
Lassen Sie mich zwei neue Metriken vorstellen (wenn Sie noch nichts davon gehört haben und wenn ja, vielleicht nur ein bisschen Humor und weiterlesen?, :D)
Wenn Sie sich also Wikipedia ansehen, werden Sie feststellen, dass die Formel zur Berechnung der Genauigkeit und des Rückrufs wie folgt lautet:
Lassen Sie es mich hier zur weiteren Erklärung angeben.

Lassen Sie mich hier die Verwirrungsmatrix und ihre Teile einfügen.
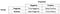
Precision
Großartig!, Schauen wir uns nun zuerst die Präzision an.

Was beachten Sie für den Nenner? Der Nenner ist eigentlich die insgesamt vorhergesagte Positive!, So the formula becomes


Immediately, you can see that Precision talks about how precise/accurate your model is out of those predicted positive, how many of them are actual positive.,
Präzision ist ein gutes maß zu bestimmen,, wenn die kosten von Falsch Positive ist hoch. Zum Beispiel, E-Mail-spam-Erkennung. Bei der Erkennung von E-Mail-Spam bedeutet ein Falsch-Positiv, dass eine E-Mail, die kein Spam ist (tatsächlich negativ), als Spam identifiziert wurde (vorhergesagter Spam). Der E-Mail-Benutzer kann wichtige E-Mails verlieren, wenn die Genauigkeit für das Spam-Erkennungsmodell nicht hoch ist.
Rückruf
Also wenden wir die gleiche Logik für den Rückruf an. Erinnern Sie sich, wie der Rückruf berechnet wird.,


There you go! So Recall actually calculates how many of the Actual Positives our model capture through labeling it as Positive (True Positive)., Wenn wir dasselbe Verständnis anwenden, wissen wir, dass Rückruf die Modellmetrik sein wird, mit der wir unser bestes Modell auswählen, wenn hohe Kosten mit falsch negativen verbunden sind.
Zum Beispiel bei der Betrugserkennung oder der Erkennung von kranken Patienten. Wenn eine betrügerische Transaktion (tatsächlich positiv) als nicht betrügerisch (vorhergesagt negativ) vorhergesagt wird, kann die Konsequenz für die Bank sehr schlecht sein.
In ähnlicher Weise bei der Erkennung von kranken Patienten. Wenn ein kranker Patient (tatsächlich positiv) den Test durchläuft und als nicht krank vorhergesagt wird (vorhergesagt negativ)., Die mit falsch Negativ verbundenen Kosten sind extrem hoch, wenn die Krankheit ansteckend ist.
F1 Score
Wenn Sie nun viele andere Literatur über Präzision und Rückruf lesen, können Sie das andere Maß nicht vermeiden, F1, das eine Funktion von Präzision und Rückruf ist. Wenn man sich Wikipedia ansieht, lautet die Formel wie folgt:

F1 Score wird benötigt, wenn Sie ein Gleichgewicht zwischen Präzision und Rückruf., Right…so was ist dann der Unterschied zwischen F1-Score und Genauigkeit? Wir haben bereits gesehen, dass Genauigkeit weitgehend durch eine große Anzahl von wahren Negativen beigetragen werden kann, die in den meisten Geschäftsumständen, konzentrieren wir uns nicht auf viel während Falsch Negativ und falsch Positiv hat in der Regel Geschäftskosten (materielle & immaterielle) somit F1 Score könnte eine bessere Maßnahme zu verwenden, wenn wir ein Gleichgewicht zwischen Präzision und Rückruf suchen müssen und es gibt eine ungleichmäßige Klassenverteilung (große Anzahl von tatsächlichen Negativen).,
Ich hoffe, die Erklärung wird denjenigen helfen, die mit Data Science beginnen und an Klassifizierungsproblemen arbeiten, dass Genauigkeit nicht immer die Metrik ist, aus der Sie das beste Modell auswählen können.
Hinweis: Erwägen Sie, sich für meinen Newsletter anzumelden, oder besuchen Sie meine Website, um die neuesten Informationen zu erhalten.
Ich wünsche allen Lesern eine UNTERHALTSAME datenwissenschaftliche Lernreise.