
często, gdy rozmawiam z organizacjami, które chcą wdrożyć naukę danych do swoich procesów, często zadają pytanie: „Jak uzyskać najbardziej dokładny model?”. I zapytałem dalej: „jakie wyzwanie biznesowe próbujesz rozwiązać za pomocą modelu?,”i będę miał zagadkowy wygląd, ponieważ pytanie, które postawiłem, tak naprawdę nie odpowiada na ich pytanie. Następnie będę musiał wyjaśnić, dlaczego zadałem pytanie, zanim zaczniemy badać, czy dokładność jest miarą modelu be-all I end-all, z której wybierzemy nasz „najlepszy” model.
więc pomyślałem, że wyjaśnię w tym wpisie na blogu, że dokładność nie musi być jednym i jedynym modelem danych metrycznych, które naukowcy ścigają i zawierają proste wyjaśnienie innych wskaźników.
najpierw przyjrzyjmy się poniższej macierzy zamieszania. Jaka jest dokładność dla modelu?,

bardzo łatwo zauważysz, że dokładność dla tego modelu jest bardzo wysoka, na poziomie 99,9%!! Wow! Trafiłeś w dziesiątkę i Święty Graal (*krzycz i biegaj po pokoju, pompując pięść w powietrzu kilka razy*)!
ale….(dobrze wiesz, że to nadchodzi prawda?) co jeśli wspomniałem, że ten pozytywny tutaj jest rzeczywiście ktoś, kto jest chory i nosi wirusa, który może rozprzestrzeniać się bardzo szybko?, A może pozytywna sprawa to oszustwo? Czy pozytywny tutaj reprezentuje terrorystę, że model mówi, że nie jest terrorystą? Rozumiesz. Koszty posiadania błędnie zaklasyfikowanego rzeczywistego pozytywu (lub fałszywego negatywu) są tutaj bardzo wysokie w tych trzech okolicznościach, które przedstawiłem.
OK, więc teraz zdałeś sobie sprawę, że dokładność nie jest miarą be-all I end-all modelu, aby użyć przy wyborze najlepszego modelu…co teraz?
pozwól, że przedstawię dwie nowe metryki (jeśli o tym nie słyszałeś, a jeśli tak, to może po prostu trochę mnie pociesz i czytaj dalej?, : D)
więc jeśli spojrzysz na Wikipedię, zobaczysz, że wzór na obliczanie precyzji i przypomnienia jest następujący:
pozwolę sobie umieścić go tutaj dla dalszego wyjaśnienia.

dodam tu macierz zamieszania i jej części.
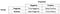
Precision
great!, Teraz spójrzmy najpierw na precyzję.

co zauważasz dla mianownika? Mianownik jest w rzeczywistości całkowitą przewidywaną dodatnią!, So the formula becomes


Immediately, you can see that Precision talks about how precise/accurate your model is out of those predicted positive, how many of them are actual positive.,
precyzja jest dobrym środkiem do określenia, kiedy koszty fałszywie dodatnie są wysokie. Na przykład wykrywanie spamu przez e-mail. W wykrywaniu spamu wiadomości e-mail fałszywie dodatni oznacza, że wiadomość e-mail, która nie jest spamem (rzeczywisty negatywny), została zidentyfikowana jako spam (przewidywany spam). Użytkownik poczty e-mail może stracić ważne wiadomości e-mail, jeśli precyzja nie jest wysoka dla modelu wykrywania spamu.
Recall
zastosujmy więc tę samą logikę do Recall. Przypomnij jak obliczane jest przypomnienie.,


There you go! So Recall actually calculates how many of the Actual Positives our model capture through labeling it as Positive (True Positive)., Stosując to samo zrozumienie, wiemy, że Przypomnienie powinno być metryką modelu, której używamy, aby wybrać nasz najlepszy model, gdy istnieje wysoki koszt związany z fałszywie ujemnym.
na przykład w wykrywaniu oszustw lub wykrywaniu chorych pacjentów. Jeśli oszukańcza transakcja (rzeczywista wartość dodatnia) jest przewidywana jako nie oszukańcza (przewidywana wartość ujemna), konsekwencje mogą być bardzo złe dla banku.
podobnie w wykrywaniu chorych. Jeśli chory pacjent (rzeczywisty dodatni) przechodzi przez test i przewiduje się, że nie jest chory(przewidywany ujemny)., Koszt związany z fałszywie ujemnym będzie bardzo wysoki, jeśli choroba jest zaraźliwa.
wynik F1
Jeśli czytasz wiele innych literatury na temat precyzji i przypomnienia, nie możesz uniknąć drugiej miary, F1, która jest funkcją precyzji i przypomnienia. W Wikipedii wzór wygląda następująco:

wynik F1 jest potrzebny, gdy chcesz znaleźć równowagę między precyzją a przypomnieniem., Right…so jaka jest zatem różnica między wynikiem F1 a dokładnością? Wcześniej widzieliśmy, że dokładność może być w dużej mierze przyczyni się do dużej liczby prawdziwych negatywów, które w większości sytuacji biznesowych, nie koncentrujemy się na wiele, podczas gdy fałszywie ujemne i fałszywie dodatnie zwykle ma koszty biznesowe (materialne & niematerialne) w ten sposób wynik F1 może być lepszym środkiem do wykorzystania, jeśli musimy szukać równowagi między precyzją i przypomnienia i nie ma nierównomiernego rozkładu klasy (duża liczba rzeczywistych negatywów).,
mam nadzieję, że Wyjaśnienie pomoże tym, którzy zaczynają naukę o danych i pracują nad problemami z klasyfikacją, że dokładność nie zawsze będzie metryką, z której można wybrać najlepszy model.
Uwaga: rozważ zapisanie się do mojego newslettera lub odwiedź moją stronę internetową po najnowsze informacje.
życzę wszystkim czytelnikom przyjemnej podróży do nauki danych.