
vaak als ik praat met organisaties die data science in hun processen willen implementeren, vragen ze zich vaak af: “hoe krijg ik het meest nauwkeurige model?”. Ik vroeg verder: “welke zakelijke uitdaging probeer je op te lossen met het model?,”en ik krijg de raadselachtige blik omdat de vraag die ik stelde niet echt antwoord op hun vraag. Ik zal dan moeten uitleggen waarom ik de vraag gesteld voordat we beginnen te onderzoeken of nauwkeurigheid is de be-all en end-all model metric die we zullen kiezen voor ons “beste” model uit.
dus ik dacht dat ik zal uitleggen in deze blog post dat nauwkeurigheid hoeft niet nodig zijn de een-en-enige model metrics data wetenschappers jagen en omvatten eenvoudige uitleg van andere metrics ook.
laten we eerst de volgende verwarmingsmatrix bekijken. Wat is de nauwkeurigheid van het model?,

merk op dat de nauwkeurigheid voor dit model zeer zeer hoog is, met 99,9%!! Wow! Je hebt de jackpot en de Heilige Graal (*schreeuw en ren rond de kamer, het pompen van de vuist in de lucht meerdere malen*)!
maar….je weet toch dat dit eraan komt? wat als ik zou zeggen dat het positieve hier eigenlijk iemand is die ziek is en een virus draagt dat zich heel snel kan verspreiden?, Of de positieve hier vertegenwoordigen een fraude zaak? Of het positieve hier vertegenwoordigt terrorist dat het model zegt dat het een niet-terrorist is? Je snapt het wel. De kosten van het hebben van een verkeerd geclassificeerde werkelijke positief (of vals-negatief)is zeer hoog hier in deze drie omstandigheden die ik gesteld.
OK, dus nu realiseerde je je dat nauwkeurigheid niet de be-all en end-all model metriek is die gebruikt wordt bij het selecteren van het beste model…wat nu?
laat me twee nieuwe metrics introduceren (als je er nog niet over gehoord hebt en als je dat wel doet, doe me dan misschien een beetje plezier en Lees verder?, : D)
dus als je naar Wikipedia kijkt, zul je zien dat de formule voor het berekenen van precisie en Recall als volgt is:
laat ik het hier zetten voor verdere uitleg.

laat me invoegen de verwarring matrix en zijn delen hier.
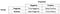
precisie
geweldig!, Laten we nu eerst naar de precisie kijken.

Wat moet u doen zie je de noemer? De noemer is eigenlijk het totale voorspelde positieve!, So the formula becomes


Immediately, you can see that Precision talks about how precise/accurate your model is out of those predicted positive, how many of them are actual positive.,
nauwkeurigheid is een goede maatstaf om te bepalen wanneer de kosten van vals-positief hoog zijn. Bijvoorbeeld, e-mail spam detectie. In e-mail spam detectie, een vals positief betekent dat een e-mail die niet-spam (werkelijke negatieve) is geïdentificeerd als spam (voorspelde spam). De e-mail gebruiker kan belangrijke e-mails te verliezen als de precisie is niet hoog voor de spam detectie model.
Recall
dus laten we dezelfde logica toepassen voor Recall. Herinner hoe de herinnering wordt berekend.,


There you go! So Recall actually calculates how many of the Actual Positives our model capture through labeling it as Positive (True Positive)., Door hetzelfde begrip toe te passen, weten we dat Recall de modelmetriek zal zijn die we gebruiken om ons beste model te selecteren wanneer er hoge kosten verbonden zijn aan vals-negatief.
bijvoorbeeld bij fraudedetectie of detectie van zieke patiënten. Als een frauduleuze transactie (feitelijk positief) wordt voorspeld als niet-frauduleus (voorspeld negatief), kan het gevolg zeer slecht zijn voor de bank.
hetzelfde geldt voor de detectie van zieke patiënten. Als een zieke patiënt (daadwerkelijk positief) door de test gaat en voorspeld wordt dat hij niet ziek is (voorspeld negatief)., De kosten verbonden aan vals negatief zal zeer hoog zijn als de ziekte besmettelijk is.
F1 Score
als je nu veel andere literatuur leest over precisie en Recall, kun je de andere maat, F1, die een functie is van precisie en Recall, niet vermijden. Kijkend naar Wikipedia, is de formule als volgt:

F1-score is nodig als je een balans wilt zoeken tussen precisie en terugroepen., Right…so Wat is dan het verschil tussen F1-Score en nauwkeurigheid? We hebben eerder gezien dat nauwkeurigheid grotendeels kan worden bijgedragen door een groot aantal True negatieven die in de meeste zakelijke omstandigheden, we niet richten op veel, terwijl vals negatief en vals positief meestal heeft zakelijke kosten (tastbare & immaterieel) dus F1 Score zou een betere maatstaf te gebruiken als we nodig hebben om een evenwicht tussen precisie en terugroeping en er is een ongelijke klasse verdeling (groot aantal werkelijke negatieven).,
Ik hoop dat de uitleg degenen die beginnen met Data Science en werken aan Classificatieproblemen zal helpen, dat nauwkeurigheid niet altijd de maatstaf zal zijn om het beste model uit te selecteren.
opmerking: overweeg om je aan te melden voor mijn nieuwsbrief of ga naar mijn website voor het laatste nieuws.
Ik wens alle lezers een leuk datawetenschap leertraject.