
Ofte når jeg snakker til organisasjoner som er ute etter å gjennomføre data vitenskap i sine prosesser, de ofte stille spørsmålet, «Hvordan kan jeg få mest mulig nøyaktig modell?». Og jeg spurte videre: «Hva forretninger utfordring er det du prøver å løse ved hjelp av modellen?,»og jeg vil få det underlige utseende fordi spørsmålet som jeg stilte egentlig ikke svare på deres spørsmål. Deretter vil jeg behov for å forklare hvorfor jeg stilte spørsmålet før vi begynner å utforske hvis Nøyaktigheten være-alt vi er og modell for beregning at vi skal velge våre «beste» modellen fra.
Så jeg tenkte jeg vil forklare i denne blogg innlegg som Korrektheten trenger ikke være nødvendig en-og-modell beregninger data forskere chase og inkluderer enkel forklaring av andre verdier også.
for det Første, la oss se på følgende forvirring matrise. Hva er nøyaktigheten til modellen?,

Veldig enkelt, vil du legge merke til at nøyaktigheten for denne modellen er veldig veldig høy, på 99.9%!! Wow! Du har truffet jackpot og hellige gral (*skrike og løpe rundt i rommet, pumping knyttneve i luften flere ganger*)!
Men….(vel du vet at dette kommer rett?) hva gjør jeg hvis jeg nevnt at positive over her er faktisk noen som er syke og bærer et virus som kan spre seg svært raskt?, Eller det positive her representerer en svindel-sak? Eller det positive her representerer terrorist at modellen sier det er en ikke-terrorist? Godt du får ideen. Kostnadene ved å ha en mis-klassifisert faktiske positive (eller falske negative) er svært høy her i disse tre forhold som jeg stilte.
OK, så nå kan du innså at nøyaktighet er ikke det være-alt vi er og modell for beregning for å bruke når du skal velge den beste modellen…nå hva?
La meg introdusere to nye beregninger (hvis dere ikke har hørt om det, og hvis du gjør det, kanskje bare føye meg litt og fortsett å lese?, 😀 )
Så hvis du ser på Wikipedia, vil du se at formelen for beregning av Presisjon og Recall er som følger:
La meg si det her for ytterligere forklaring.

La meg sette i forvirringen matrix og deler her.
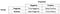
Presisjon
Flott!, La oss nå se på Presisjon første.

Hva legger du merke til nevneren? Nevneren er faktisk den Totale Spådd Positivt!, So the formula becomes


Immediately, you can see that Precision talks about how precise/accurate your model is out of those predicted positive, how many of them are actual positive.,
Presisjon er et godt tiltak for å avgjøre, når kostnadene av Falske Positive er høy. For eksempel, e-post spam deteksjon. I en e-post spam deteksjon, en falsk positiv, betyr det at en e-post som ikke er spam (faktiske negative) har blitt identifisert som spam (spådd spam). E-brukeren kan miste viktige e-poster hvis presisjon er ikke høy for spam deteksjon modell.
Tilbakekall
Så la oss bruke den samme logikken for Tilbakekall. Husker hvordan Recall er beregnet.,


There you go! So Recall actually calculates how many of the Actual Positives our model capture through labeling it as Positive (True Positive)., Å bruke samme forståelse, vet vi at Tilbakekall skal være modellen for beregning vi bruke til å velge vår beste modellen når det er høye kostnader forbundet med Falske Negative.
For eksempel, i svindel-gjenkjenning eller syk pasient gjenkjenning. Hvis en falsk transaksjonen (Faktiske Positive) er spådd som ikke-uredelig (Spådd Negative), den konsekvens kan være veldig dårlig for banken.
på samme måte, i syk pasient gjenkjenning. Hvis en syk pasient (Faktiske Positive) går gjennom testen og spådd som ikke er syk (Spådd Negative)., Kostnadene forbundet med Falsk Negativ vil være svært høy hvis sykdommen er smittsom.
F1-Score
hvis du Nå lese mye annen litteratur på Presisjon og Recall, kan du ikke unngå andre tiltak, F1, som er en funksjon av Precision og Recall. Ser på Wikipedia, formelen er som følger:

F1 Score er nødvendig når du ønsker å søke en balanse mellom Presisjon og Recall., Rett…så hva er forskjellen mellom F1 Score og Nøyaktighet da? Vi har tidligere sett at nøyaktigheten kan være i stor grad bidratt med et stort antall Sanne Negative, som i de fleste forretningsjuridiske forhold, har vi ikke fokus på mye mens Falske Negative og Falske Positive vanligvis har bedriftenes kostnader (varige & immaterielle) og dermed F1-Score kan være et bedre tiltak å bruke hvis vi må søke en balanse mellom Presisjon og Recall, OG det er en ujevn klasse distribusjon (stort antall Faktiske Negativer).,
jeg håper forklaringen vil hjelpe de som starter ut på Data Vitenskap og arbeider på Klassifisering problemer, at Nøyaktigheten vil ikke alltid være den metriske til å velge den beste modellen fra.
Merk: Vurdere å melde deg på mitt nyhetsbrev eller hodet til min nettside for den siste.
jeg ønsker alle lesere en MORSOM Data Realfag reise for å lære.