
souvent, lorsque je parle à des organisations qui cherchent à implémenter la science des données dans leurs processus, elles posent souvent la question: « Comment puis-je obtenir le modèle le plus précis?”. Et j’ai demandé plus loin, » quel défi commercial essayez-vous de résoudre en utilisant le modèle?, »et je vais avoir le regard déroutant parce que la question que j’ai posée ne répond pas vraiment à leur question. Je devrai ensuite expliquer pourquoi j’ai posé la question avant de commencer à explorer si la précision est la métrique du modèle be-all et end-all À partir de laquelle nous choisirons notre « meilleur” modèle.
J’ai donc pensé que je vais expliquer dans cet article de blog que la précision n’a pas besoin d’être la seule et unique métrique du modèle que les scientifiques recherchent et incluent également une explication simple d’autres métriques.
tout d’abord, regardons la matrice de confusion suivante. Quel est l’exactitude du modèle?,

Très facilement, vous remarquerez que la précision de ce modèle est très élevée, à 99,9%!! Ça alors! Vous avez touché le jackpot et le Saint Graal (*criez et courez dans la pièce, en pompant le poing en l’air plusieurs fois*)!
Mais….(Eh bien, vous savez que cela vient à droite?) que faire si j’ai mentionné que le positif est en fait quelqu’un qui est malade et porteur d’un virus qui peut se propager très rapidement?, Ou le positif ici représente un cas de fraude? Ou le positif ici représente terroriste que le modèle dit que c’est un non-terroriste? Ainsi, vous obtenez l’idée. Les coûts d’avoir un positif réel mal classé (ou faux négatif) sont très élevés ici dans ces trois circonstances que j’ai posées.
OK, alors maintenant, vous avez réalisé que la précision n’est pas l’alpha et l’oméga du modèle de mesure à utiliser lors de la sélection du meilleur modèle…et maintenant?
Permettez-moi de présenter deux nouvelles métriques (si vous n’en avez pas entendu parler et si vous le faites, peut-être juste me faire de l’humour un peu et continuer à lire?, : D)
donc, si vous regardez Wikipedia, vous verrez que la formule pour calculer la précision et le rappel est la suivante:
laissez-moi le mettre ici pour plus d’explications.

Permettez-moi de mettre dans la confusion de la matrice et de ses parties, ici.
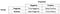
Précision
Super!, Maintenant, penchons-nous sur la Précision de la première.

Que pensez vous de l’avis pour le dénominateur? Le dénominateur est en fait le total prédit positif!, So the formula becomes


Immediately, you can see that Precision talks about how precise/accurate your model is out of those predicted positive, how many of them are actual positive.,
la précision est une bonne mesure pour déterminer, lorsque le coût des faux positifs est élevé. Par exemple, la détection de spam par e-mail. Dans la détection de spam par e-mail, un faux positif signifie qu’un e-mail qui n’est pas un spam (négatif réel) a été identifié comme spam (spam prédit). L’utilisateur de messagerie peut perdre des e-mails importants si la précision n’est pas élevée pour le modèle de détection de spam.
Rappel
Donc, nous allons appliquer la même logique pour le Rappel. Rappelez-vous comment le rappel est calculé.,


There you go! So Recall actually calculates how many of the Actual Positives our model capture through labeling it as Positive (True Positive)., En appliquant la même compréhension, nous savons que le rappel doit être la mesure du modèle que nous utilisons pour sélectionner notre meilleur modèle lorsque le coût du faux négatif est élevé.
par exemple, dans la détection de fraude ou la détection de patients malades. Si une transaction frauduleuse (Positive réelle) est prédite comme non frauduleuse (négative prévue), la conséquence peut être très mauvaise pour la banque.
de même, dans la détection des patients malades. Si un patient malade (positif réel) passe par le test et prédit comme non malade (négatif prédit)., Le coût associé au faux négatif sera extrêmement élevé si la maladie est contagieuse.
Score F1
maintenant, si vous lisez beaucoup d’autres documents sur la précision et le rappel, vous ne pouvez pas éviter L’autre mesure, F1 qui est une fonction de précision et de rappel. En regardant sur Wikipédia, la formule est la suivante:

F1 Score est nécessaire lorsque vous voulez trouver un équilibre entre la Précision et le Rappel., Right…so Quelle est la différence entre le Score F1 et la précision alors? Nous avons déjà vu que la précision peut être largement favorisée par un grand nombre de vrais négatifs sur lesquels, dans la plupart des circonstances commerciales, nous ne nous concentrons pas beaucoup alors que les faux négatifs et les faux positifs ont généralement des coûts commerciaux (tangible & intangible). ainsi, le Score F1 pourrait être une meilleure mesure à utiliser si nous devons rechercher un équilibre entre la précision et le rappel et il existe une distribution inégale des classes (grand nombre de négatifs réels).,
j’espère que l’explication aidera ceux qui débutent dans la science des données et travaillent sur des problèmes de Classification, que la précision ne sera pas toujours la mesure pour sélectionner le meilleur modèle.
Remarque: pensez à vous inscrire à ma newsletter ou rendez-vous sur mon site web pour les dernières nouvelles.
je souhaite à tous les lecteurs un voyage D’apprentissage amusant en science des données.