Pokud právě začínáte v Pythonu a chcete se dozvědět více, Vezměte si úvod Datacampu do datové vědy v Pythonu.
Úvod
Threading umožňuje, aby různé části procesu běžet souběžně (Zdroj: RealPython). Tyto různé části jsou obvykle individuální a mají samostatnou jednotku provedení patřící do stejného procesu., Proces není nic jiného než běžící program, který má jednotlivé jednotky, které lze spustit současně. Například webový prohlížeč může být proces, aplikace běžící více kamer současně může být proces; videohra je dalším příkladem procesu.
Uvnitř procesu přichází koncept vícenásobné řezání závitů nebo běžně známý jako multi-threading, kde více vláken společně pracovat na dosažení společného cíle. Nejdůležitější výhodou použití vláken je to, že vám umožňuje spustit program paralelně.,
pojďme pochopit koncept závitu pomocí příkladu. Představte si, že máte aplikaci, která počítá počet automobilů vstupujících a vystupujících z parkoviště obchoďáku. Vaše zařízení má různé kamery, které monitorují vstup a výstup připojení k centrálnímu zařízení. Každá kamera bude mít algoritmus pro sledování toku automobilů, který bude patřit ke stejnému procesu nebo programu. Každá kamera, spolu s algoritmem, na kterém běží, by však mohla být součástí samostatného vlákna., Nejen to, ale i snímky, které se čtou z kamery a algoritmus předpovídající snímky, by mohly být také dvě samostatná vlákna.
dalším příkladem může být videohra, ve které musí proces provádět úkoly paralelně, jako je grafika, interakce uživatelů a vytváření sítí (při hraní her pro více hráčů), protože musí vždy reagovat. A aby toho bylo dosaženo, musí využít koncept multi-threading, kde každé vlákno by bylo zodpovědné za spuštění každého nezávislého a individuálního úkolu.,
vlákno má svůj tok provedení, což znamená, že proces bude mít více věcí, které se dějí najednou.
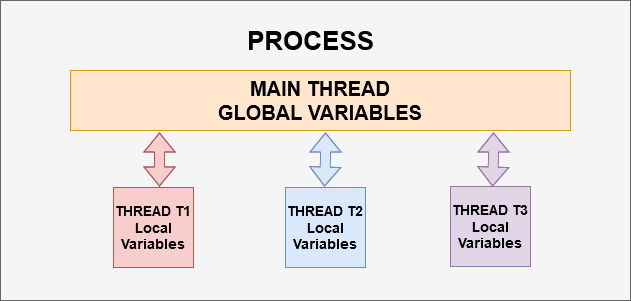
je důležité si uvědomit, že každý proces má alespoň jedno vlákno, a to se nazývá main thread. Pokud váš program nemá žádné definované vlákno, bude mít alespoň hlavní vlákno, tj.
Pokud se podíváte na výše uvedený diagram, existuje proces, který se skládá z hlavního vlákna sestávajícího z globálních proměnných a tří různých vláken t1, t2 a t3. Každé vlákno má své lokální proměnné a tok provádění kódu., Vlákna obecně sdílejí zdroje procesu, stejně jako dostupné zdroje, aby hlavní vlákno bude také být sdíleny mezi třemi závity t1, t2, a t3. Všechna vlákna budou mít přístup k globálním proměnným a zároveň budou mít své vlastní lokální proměnné.,
Existují různé typy závitů:
- Jádro nitě
- Uživatelské vlákno
- Kombinace jádra a uživatelské vlákno
Teď se pojďme podívat na některé z výhod, které závitů ve vašem programu:
-
Multi-threading umožňuje programu, aby urychlily provádění za předpokladu, že to má více Procesorů.
-
umožňuje také provádět další úkoly, zatímco operace I / O jsou prováděny pomocí více vláken nebo dokonce hlavního vlákna spolu s jedním vláknem., Například rychlost, při které jsou snímky z fotoaparátu čteny a odvozeny algoritmem, bude řešena různými vlákny. Algoritmus tedy nebude muset čekat, až bude snímek zadán, a část pro čtení rámců nebude muset čekat na dokončení provádění algoritmu, aby mohla přečíst další snímek.
- vlákna ve stejném procesu mohou sdílet paměť a zdroje hlavního vlákna.,
Výzvy Threading:
-
vzpomeňte si, že Python funguje na základě implementace CPython, což omezuje pouze jedno vlákno běžet na čas, proto; řezání závitů nemusí urychlit všechny úkoly. A základním důvodem je Global Interpreter Lock (GIL).
Pokud se chcete dozvědět o GIL, pak se neváhejte podívat na tento tutoriál.
-
Pokud hledáte urychlení úlohy náročné na CPU, nemusí být pro vás vlákno nejlepším řešením. V takových případech je vícenásobné zpracování považováno za užitečné.,
-
Chcete-li spustit program složený z různých vláken, je třeba rychle přepínat napříč vlákny; proto je třeba se postarat o plánování v programech, kde máte spoustu vláken.
-
sdílení zdrojů může být také problém, protože všechna vlákna sdílejí stejné zdroje a paměť globálních proměnných. Operace prováděné v jednom vlákně by tedy mohly způsobit chybu paměti pro jiné vlákno nebo jiné vlákno nemusí dostat paměť k provedení svého úkolu.,
Threading v Pythonu
-
V Pythonu, řezání závitů modul vestavěný modul, který je známý jako
threadinga mohou být přímo importovány. -
protože téměř vše v Pythonu je reprezentováno jako objekt, threading je také objekt v Pythonu. Vlákno je schopné
- držet data,
- uložené v datových strukturách, jako jsou slovníky,Seznamy, sady atd.
- lze předat jako parametr funkci.
-
vlákno může být také provedeno jako proces.,
-
vlákno v Pythonu může mít různé stavy jako:
- počkat,
- uzamčeno.
pojďme se nyní dozvědět, jak můžete implementovat závitování v Pythonu.
Nit modul v Python3
Všimněte si, že Python3 je zpětně kompatibilní s thread modul, který existuje v Python2.7. V Python3 může být importován jako modul _thread. Vezměme si příklad a pochopíme modul _thread.,
import _thread #thread module importedimport time #time modulepojďme definovat funkci nazvanou thread_delay, která bude mít dva parametry jako vstup, tj. Uvnitř této funkce, bude:
- Definovat counter s nulou,
- Pak bude smyčka kolem s while, který bude probíhat třikrát,
- Uvnitř while smyčky, budete dát
time.sleep()přidat zpoždění, tak to zpoždění bude užitečné pochopit, provedení závitu., Toto zpoždění bude za několik sekund - Pak budete přírůstek čítače o 1,
- Aby zjistili, zda váš podproces provádění probíhá hladce, budete tisknout jméno závitu a čas, ve kterém nit je popraven.
def thread_delay(thread_name, delay): count = 0 while count < 3: time.sleep(delay) count += 1 print(thread_name, '-------->', time.time())přidat vlákno funkčnost na výše uvedené funkce, nebo spustit výše uvedené funkce v závitu, měli byste použít start_new_thread metoda, která je uvnitř _thread module.
podívejme se na docstring metody start_new_thread.,
?_thread.start_new_thread
Pojďme se projít ve funkci thread_delay bez závorek a dva argumenty, tj., vlákno jméno a zpoždění (vizualizovat závit provedení, protože to je velmi rychle).
_thread.start_new_thread(thread_delay, ('t1', 1))_thread.start_new_thread(thread_delay, ('t2', 3))Z výše uvedeného výstupu, můžete vidět, že nit t1 začne vykonávat jako první., Mezitím, závit t2 čeká, protože tam je 3 sekundy zpoždění, a jakmile se to zpoždění je hotový, nitě t2 je popraven, a také zpoždění pro závit t1 je jen 1 sekundu.
zkusíme teď změnit zpoždění t2 pro 5 sekund, což by začít t2 t1 by skončil vykonávající, jelikož t1 bude to trvat jen 3 sekundy na dokončení jeho spuštění.,
_thread.start_new_thread(thread_delay, ('t1', 1))_thread.start_new_thread(thread_delay, ('t2', 5))Provádění řezání závitů pomocí Závitovací modulu
použijeme stejný příklad jako jste použili výše, ale tentokrát budete používat threading modul místo _thread modul.
import threadingimport timedef thread_delay(thread_name, delay): count = 0 while count < 3: time.sleep(delay) count += 1 print(thread_name, '-------->', time.time())Uvnitř threading modul je Thread třídu, která je v podobném duchu na start_new_thread funkce _thread modul.,
podívejme se na docstring třídy Thread, která má několik parametrů, jako je skupina, cíl (jako funkce), args atd.
?threading.Thread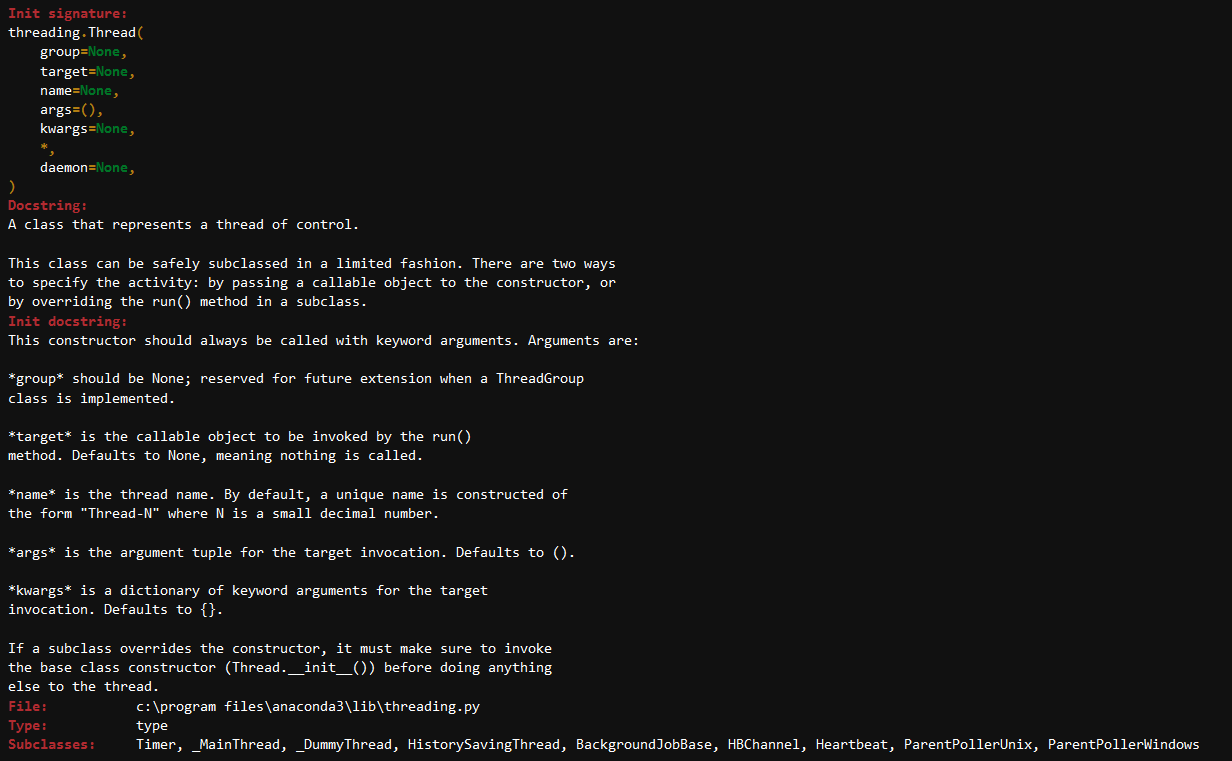
V konstruktoru třídy Thread, minete v cílové funkce thread_delay a argumenty této funkce.,
t1 = threading.Thread(target=thread_delay, args=('t1', 1))t2 = threading.Thread(target=thread_delay, args=('t2', 3))Při řezání závitů modul, aby bylo možné spustit nebo spustit vlákno, budete používat start() metoda, která jednoduše zodpovědný za chod závitu.
?t1.start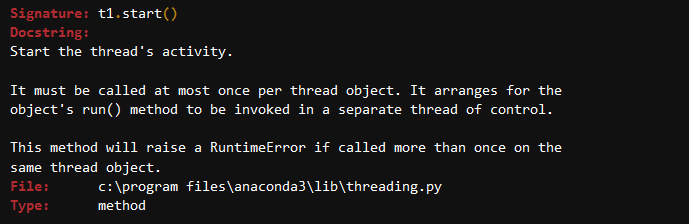
t1.start()t2.start()Budete také použít join metoda, což znamená, že počkejte, dokud se všechny podproces provádění je kompletní., Takže cokoliv jste napsali po join metoda bude proveden, jakmile tyto vlákna mají ukončen.
?t1.join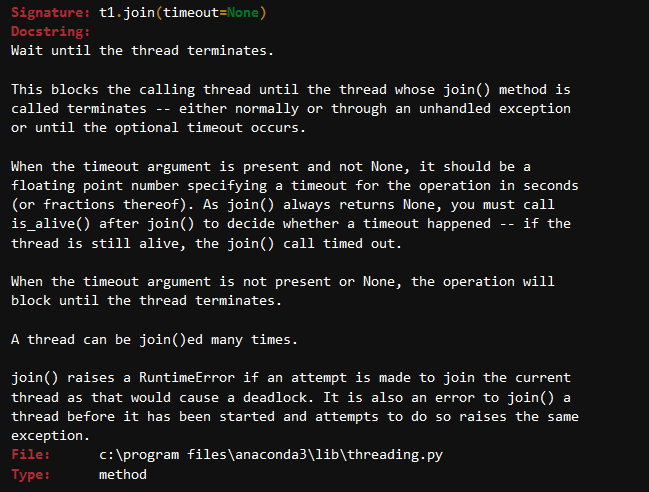
t1.start()t2.start()t1.join()t2.join()print("Thread execution is complete!")Nyní to pojďme vypočítat objem krychle a čtverce pomocí závitů koncept, který je docela rovně vpřed.
def volume_cube(a): print ("Volume of Cube:", a*a*a)def volume_square(a): print ("Volume of Square:", a*a)t1 = threading.Thread(target=volume_cube, args=(2))t2 = threading.Thread(target=volume_square, args=(3))t1.start()t2.start()t1.join()t2.join()print("Thread execution is complete!")Čekat, co? Jakmile jste provedli metodu start, došlo k chybě., To je proto, args parametr očekává n-tice, a protože volume_cube volume_square očekává pouze jeden parametr, proto je třeba dát čárku v args parametr po zadání první argument funkce.
t1 = threading.Thread(target=volume_cube, args=(2,))t2 = threading.Thread(target=volume_square, args=(3,))t1.start()t2.start()t1.join()t2.join()print("Thread execution is complete!")Volume of Cube: 8Volume of Square: 9Thread execution is complete!Pojďme se nyní naučit používat vlákna jako podtřídy.,
Threading jako sub-třídy
V této části, by se naučit, jak vytvořit sub-třídy z třídy thread, který je k dispozici uvnitř závitů modul, a pak vytvořit vlákno instance t1 t2 z této třídy.
zde byste použili stejnou funkci thread_delay.
Teď pojďme pochopit výše uvedený kód krok za krokem:
-
Jste definovali třídu jako
DataCampThread, a ve třídě argument, prošel jsi vthreading.Threadtřídy., Důvodem, proč to děláte, je to, že chcete vytvořit dílčí třídu z modulu závitů. To vám umožní použít všechny metody, které jsou k dispozici ve tříděthreading.Threadpodobné pojmu dědičnost. -
dále jste definovali metodu init třídy DataCampThread a předali funkci spolu se zpožděním. Init je konstruktor podobné parametry předány do
threading.Threadtřídy, tady by jsi být kolem, abyDataCampThreadtřídy., -
pak inicializujete metodu init hlavního závitu.Třída podproces a pak rovnat jméno a zpoždění.
-
Next, definovat
runmetoda, připomeňme si zde definoványstartmetoda, která v podstatě pod kapotou hovoryrunmetoda. Protože jste zdědili hlavní třídu,můžete provést změny metodyrun., Proto, když budete volatstartmetoda, cokoliv, co změny budete dělat vrunmetoda se projeví.
závěr
Gratulujeme k dokončení tutoriálu.
tento tutoriál byl základním úvodem do závitů v Pythonu. Závitování je však velmi rozsáhlé a životně důležité téma a některé koncepty mohly zůstat neprozkoumané. Neváhejte se podívat na další metody závitů, jako je aktivní počet, aktuální vlákno atd.
Pokud se chcete dozvědět více, podívejte se také na paralelismus založený na vláknech Pythonu.,
pokud právě začínáte v Pythonu a chcete se dozvědět více, Vezměte si DataCamp Úvod do datové vědy v Pythonu.