Wie viele Gene befinden sich in einem Genom?
Reader Mode
Wir haben bereits untersucht, die großen Unterschiede in der Genom-Größen in der Welt der lebenden (siehe Tabelle in der vignette auf „Wie groß sind die Genome?”). Als ersten Schritt zur Verfeinerung unseres Verständnisses des Informationsgehalts dieser Genome benötigen wir ein Gefühl für die Anzahl der Gene, die sie enthalten. Wenn wir uns auf Gene beziehen, werden wir an proteinkodierende Gene denken, die die ständig wachsende Sammlung von RNA-kodierenden Regionen in Genomen ausschließen.,
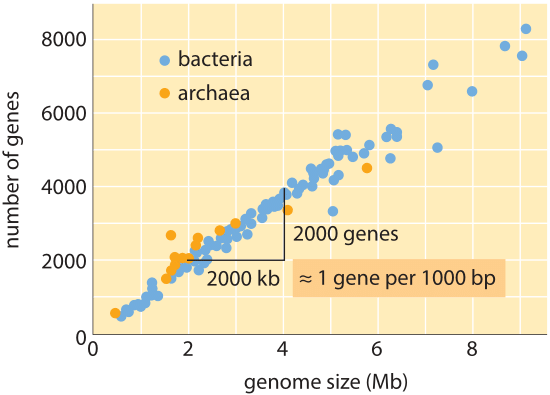
Abbildung 1: Anzahl der Gene in Abhängigkeit von der Genomgröße. Die Abbildung zeigt Daten für eine Vielzahl von Bakterien und Archaeen, wobei die Steigung der Datenlinie die einfache Faustregel in Bezug auf Genomgröße und Gennummer bestätigt. (Adaptiert von M. Lynch, The Origins of Genome Architecture.,)
Über den gesamten Baum des Lebens, obwohl die Genomgrößen um bis zu 8 Größenordnungen abweichen (von <2 kb für Hepatitis-D-Virus (BNID 105570) bis >100 Kb für den marmorierten Lungenfisch (BNID 100597) und bestimmte Fritillariablüten (BNID 102726) variiert der Bereich in der Anzahl der Gene um weniger als 5 von Größenordnung (von Viren wie MS2 und QB Bakteriophagen mit nur 4 Genen bis etwa hunderttausend in Weizen). Viele Bakterien haben mehrere tausend Gene., Dieser Gengehalt ist proportional zur Genomgröße und Proteingröße, wie unten gezeigt. Interessanterweise enthalten eukaryotische Genome, die oft tausendmal oder größer sind als die in Prokaryoten, nur eine Größenordnung mehr Gene als ihre prokaryotischen Gegenstücke. Die Unfähigkeit, die Anzahl der Gene in Eukaryoten basierend auf der Kenntnis des Gengehalts von Prokaryoten erfolgreich abzuschätzen, war eine der unerwarteten Wendungen der modernen Biologie.,
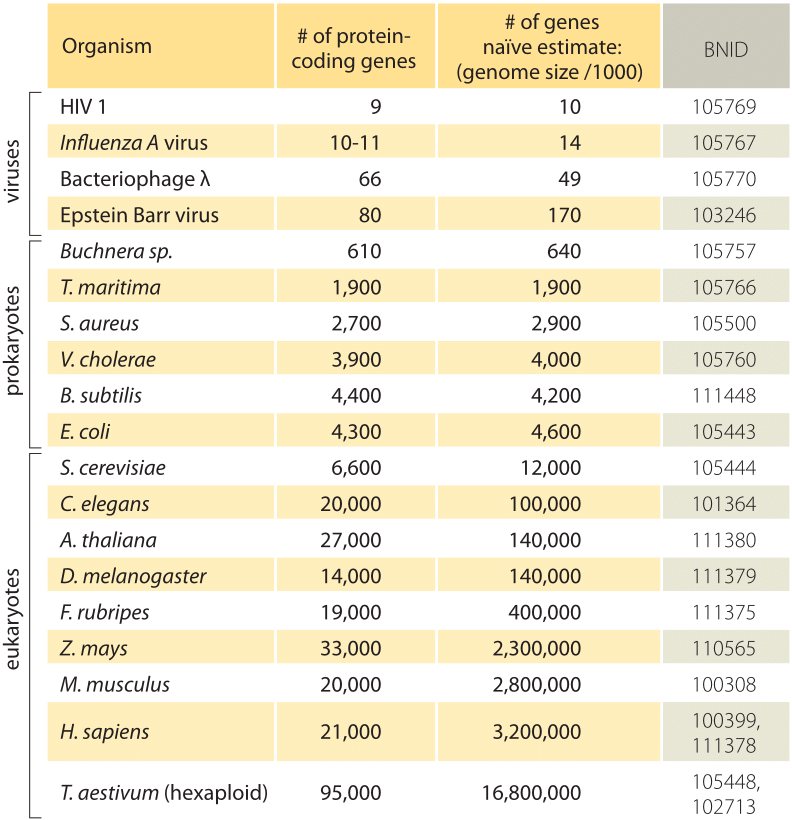
Tabelle 1: Ein Vergleich zwischen der Anzahl der Gene in einem Organismus und einer naiven Schätzung basierend auf der Genomgröße dividiert durch einen konstanten Faktor von 1000bp/gen, d.h. vorhergesagte Anzahl von Genen = Genomgröße/1000. Man stellt fest, dass diese grobe Faustregel für viele Bakterien und Archaeen überraschend gut funktioniert, für vielzellige Organismen jedoch kläglich versagt.
Die einfachste Schätzung der Anzahl der Gene in einem Genom entfaltet sich unter der Annahme, dass die Gesamtheit des Genoms für Gene von Interesse kodiert., Um weitere Fortschritte bei der Schätzung zu erzielen, müssen wir ein Maß für die Anzahl der Aminosäuren in einem typischen Protein haben, das ungefähr 300 beträgt, wobei wir uns jedoch der Tatsache bewusst sind, dass Proteine wie Genome selbst in einer Vielzahl von Größen vorkommen, wie aus der Vignette zu diesem Thema hervorgeht: „Was sind die Größen von Proteinen?”. Auf der Grundlage dieser mageren Annahme sehen wir, dass die Anzahl der Basen, die zum Codieren unseres typischen Proteins benötigt werden, ungefähr 1000 beträgt (3 Basenpaare pro Aminosäure)., Daher wird innerhalb dieser Denkweise die Anzahl der in einem Genom enthaltenen Gene auf die Genomgröße/1000 geschätzt. Für Bakteriengenome funktioniert diese Strategie überraschend gut, wie in Tabelle 1 und Abbildung 1 zu sehen ist. Bei Anwendung auf das E. coli K-12, Genom von 4,6 x 106 bp, führt diese Faustregel beispielsweise zu einer Schätzung von 4600 Genen, die mit der derzeit besten Kenntnis dieser Menge verglichen werden kann, die 4225 beträgt. Beim Durchlaufen eines Dutzend repräsentativer Bakterien und archealer Genome in der Tabelle wird eine ähnlich auffällige Vorhersagekraft auf etwa 10% beobachtet., Auf der anderen Seite scheitert diese Strategie spektakulär, wenn wir sie auf eukaryotische Genome anwenden, was beispielsweise zu der Schätzung führt, dass die Anzahl der Gene im menschlichen Genom 3,000,000 betragen sollte, eine grobe Überschätzung. Die Unzuverlässigkeit dieser Schätzung hilft, die Existenz des Genesweep-Wettpools zu erklären, bei dem erst Anfang der 2000er Jahre Menschen auf die Anzahl der Gene im menschlichen Genom gesetzt haben, wobei die Schätzungen der Menschen um mehr als den Faktor zehn variieren.,
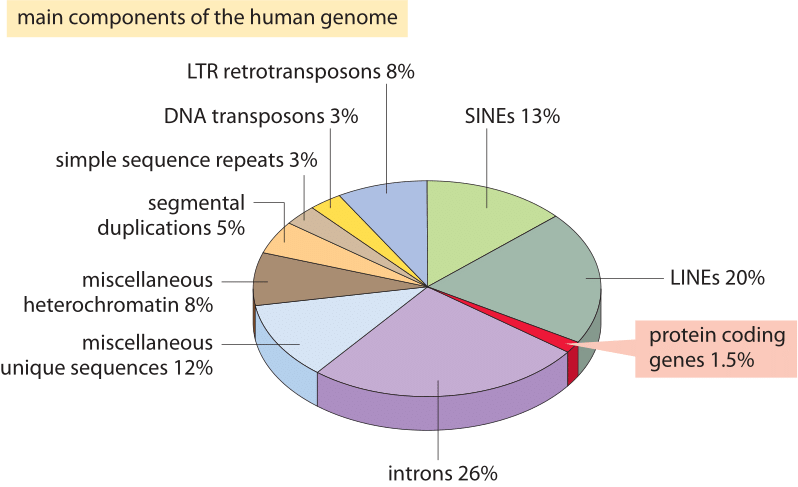
Abbildung 2: Die unterschiedlichen Reihenfolge der Komponenten macht das menschliche Genom. Etwa 1,5% des Genoms bestehen aus den ≈20.000 proteinkodierenden Sequenzen, die von den nicht kodierenden Intronen durchsetzt sind und etwa 26% ausmachen. Transponierbare Elemente sind die größte Fraktion (40-50%), einschließlich beispielsweise langer eingestreuter Kernelemente (Linien) und kurzer eingestreuter Kernelemente (SINEs). Die meisten transponierbaren Elemente sind genomische Reste, die derzeit nicht mehr vorhanden sind. (BNID 110283, Angepasst von T. R. Gregory Nat Rev Genet., 9:699-708, 2005 basiert auf International Human Genome Sequencing Consortium. Erste Sequenzierung und Analyse des menschlichen Genoms. Natur 409: 860 2001.)
Was erklärt dieses spektakuläre Versagen der naivsten Schätzung und was lehrt es uns über die in Genomen organisierten Informationen? Eukaryotische Genome, insbesondere solche, die mit vielzelligen Organismen assoziiert sind, zeichnen sich durch eine Vielzahl faszinierender Merkmale aus, die das einfache Kodierungsbild stören, das in der naiven Schätzung ausgenutzt wird., Diese Unterschiede in der Genomverwendung sind bildlich in Abbildung 2 dargestellt, die den Prozentsatz des Genoms zeigt, das für andere Zwecke als die Proteinkodierung verwendet wird. Wie in Abbildung 1 ersichtlich, können Prokaryoten ihre Proteinkodierungssequenzen effizient so verdichten, dass sie fast kontinuierlich sind und weniger als 10% ihrer Genome nicht kodierender DNA zugeordnet werden (12% in E. coli, BNID 105750), während beim Menschen über 98% (BNID 103748) nicht proteinkodierend sind.,
Die Entdeckung dieser anderen Verwendungen des Genoms bilden einige der wichtigsten Einblicke in DNA und Biologie im Allgemeinen aus den letzten 60 Jahren. Eine dieser alternativen Anwendungen für genomische Immobilien ist das regulatorische Genom, nämlich die Art und Weise, wie große Teile des Genoms als Ziele für die Bindung regulatorischer Proteine verwendet werden, aus denen die für Genome in vielzelligen Organismen typische kombinatorische Kontrolle hervorgeht., Ein weiteres Hauptmerkmal von eukaryotischen Genomen ist die Organisation ihrer Gene in Introns und Exons, wobei die exprimierten Exons viel kleiner sind als die dazwischenliegenden und gespleißten Introns. Über diese Merkmale hinaus gibt es endogene Retroviren, fossile Relikte früherer Virusinfektionen, und auffallend ist, dass über 50% des Genoms durch die Existenz sich wiederholender Elemente und Transposons aufgenommen werden, von denen verschiedene Formen möglicherweise als egoistische Gene interpretiert werden können Mechanismen, um sich in einem Wirtsgenom zu vermehren., Einige dieser sich wiederholenden Elemente und Transposons sind heute noch aktiv, während andere ein Relikt geblieben sind, nachdem sie die Fähigkeit verloren haben, sich im Genom weiter zu vermehren.
Abschließend können Genome in zwei Hauptklassen unterteilt werden: kompakt und expansiv. Ersteres ist genetisch dicht, mit nur etwa 10% der nicht kodierenden Region und strikter Proportionalität zwischen Genomgröße und Genomzahl. Diese Gruppe erstreckt sich auf Genome mit einer Größe von bis zu etwa 10 Mbp und deckt Viren, Bakterien, Archaeen und einige einzellige Eukaryoten ab., Die letztere Klasse zeigt keine klare Korrelation zwischen Genomgröße und Genzahl, besteht größtenteils aus nicht-kodierenden Elementen und deckt alle multizellulären Organismen ab.




