Eine Wahrscheinlichkeitsstichprobe ist jede Methode der Probenahme, die irgendeine Form der Zufallsauswahl verwendet. Um eine zufällige Auswahlmethode zu haben, müssen Sie einen Prozess oder eine Prozedur einrichten, die sicherstellt, dass die verschiedenen Einheiten in Ihrer Population die gleichen Wahrscheinlichkeiten haben, ausgewählt zu werden. Menschen haben seit langem verschiedene Formen der zufälligen Auswahl praktiziert, z. B. einen Namen aus einem Hut auswählen oder den kurzen Strohhalm wählen. Heutzutage neigen wir dazu, Computer als Mechanismus zur Erzeugung von Zufallszahlen als Grundlage für die Zufallsauswahl zu verwenden.,
Einige Definitionen
Bevor ich die verschiedenen Wahrscheinlichkeitsmethoden erklären kann, müssen wir einige grundlegende Begriffe definieren. Dies sind:
- ist die Anzahl der Fälle im Sampling-Frame
-
nist die Anzahl der Fälle im Sample -
NCn= die Anzahl der Kombinationen (Teilmengen) vonnvon -
f = n/Nist der Abtastanteil
Das war ‚ s., Mit diesen definierten Begriffen können wir beginnen, die verschiedenen Wahrscheinlichkeitsstichprobenmethoden zu definieren.
Einfache Zufallsstichprobe
Die einfachste Form der Zufallsstichprobe wird als einfache Zufallsstichprobe bezeichnet. Ziemlich knifflig, was? Hier ist die kurze Beschreibung der einfachen Zufallsstichprobe:
- Ziel:
nEinheiten aus so auszuwählen, dass jedeNCndie gleiche Chance hat, ausgewählt zu werden. - Verfahren: Verwenden Sie eine Zufallszahlentabelle, einen Computer-Zufallszahlengenerator oder ein mechanisches Gerät, um die Probe auszuwählen.,
Eine etwas gestelzte, wenn auch genaue Definition. Mal sehen, ob wir es ein bisschen realer machen können.

Wie wählen wir eine einfache Zufallsstichprobe aus? Nehmen wir an, wir recherchieren mit einer kleinen Serviceagentur, die die Ansichten der Kunden zur Servicequalität im vergangenen Jahr bewerten möchte. Zuerst müssen wir den Sampling-Frame organisieren. Um dies zu erreichen, werden wir Agenturaufzeichnungen durchgehen, um jeden Kunden in den letzten 12 Monaten zu identifizieren. Wenn wir Glück haben, verfügt die Agentur über gute, genaue computergestützte Aufzeichnungen und kann schnell eine solche Liste erstellen., Dann müssen wir die Probe tatsächlich zeichnen. Entscheiden Sie sich für die Anzahl der Kunden, die Sie in der endgültigen Stichprobe haben möchten. Angenommen, Sie möchten 100 zu befragende Kunden auswählen und in den letzten 12 Monaten gab es 1000 Kunden. Dann ist die Abtastfraktion f = n/N = 100/1000 = .10 (oder 10%). Um das Beispiel tatsächlich zu zeichnen, haben Sie mehrere Möglichkeiten. Sie könnten die Liste der 1000 Kunden ausdrucken, dann in separate Streifen zerreißen, die Streifen in einen Hut stecken, sie richtig gut mischen, die Augen schließen und die ersten 100 herausziehen., Aber dieses mechanische Verfahren wäre mühsam und die Qualität der Probe würde davon abhängen, wie gründlich Sie sie gemischt und wie zufällig Sie erreicht in. Vielleicht wäre ein besseres Verfahren, die Art von Ballmaschine zu verwenden, die bei vielen staatlichen Lotterien beliebt ist. Sie benötigen drei Sätze von Kugeln mit den Nummern 0 bis 9, einen Satz für jede der Ziffern von 000 bis 999 (wenn wir 000 auswählen, nennen wir das 1000)., Nummerieren Sie die Liste der Namen von 1 nach 1000 und wählen Sie dann mit der Ballmaschine die drei Ziffern aus, die jede Person auswählen. Der offensichtliche Nachteil hier ist, dass Sie die Ballmaschinen bekommen müssen. (Wo machen sie diese Dinge überhaupt? Gibt es eine Ballmaschinenindustrie?).
Keines dieser mechanischen Verfahren ist sehr machbar und mit der Entwicklung kostengünstiger Computer gibt es einen viel einfacheren Weg. Hier ist ein einfaches Verfahren, das besonders nützlich ist, wenn Sie die Namen der Clients bereits auf dem Computer haben., Viele Computerprogramme können eine Reihe von Zufallszahlen erzeugen. Angenommen, Sie können die Liste der Clientnamen kopieren und in eine Spalte in einer EXCEL-Tabelle einfügen. Fügen Sie dann in die Spalte direkt daneben die Funktion =RAND() ein, mit der EXCEL eine Zufallszahl zwischen 0 und 1 in die Zellen. Sortieren Sie dann beide Spalten-die Liste der Namen und die Zufallszahl-nach den Zufallszahlen. Dadurch wird die Liste in zufälliger Reihenfolge von der niedrigsten zur höchsten Zufallszahl neu angeordnet., Dann müssen Sie nur noch die ersten hundert Namen in dieser sortierten Liste nehmen. ziemlich einfach. Sie könnten wahrscheinlich die ganze Sache in weniger als einer Minute erreichen.
Einfache Zufallsstichproben sind einfach durchzuführen und anderen leicht zu erklären. Da eine einfache Zufallsstichprobe eine faire Möglichkeit zur Auswahl einer Stichprobe darstellt, ist es sinnvoll, die Ergebnisse der Stichprobe wieder auf die Population zu verallgemeinern. Eine einfache Zufallsstichprobe ist nicht die statistisch effizienteste Stichprobenmethode, und Sie können, nur wegen des Glücks der Auslosung, keine gute Darstellung von Untergruppen in einer Population erhalten., Um diese Probleme zu lösen, müssen wir uns anderen Stichprobenmethoden zuwenden.
Geschichtete Zufallsstichprobe
Geschichtete Zufallsstichprobe, manchmal auch als proportionale oder Quotenzufallsstichprobe bezeichnet, umfasst die Aufteilung Ihrer Population in homogene Untergruppen und dann die Entnahme einer einfachen Zufallsstichprobe in jeder Untergruppe. In formaleren Begriffen:
Es gibt mehrere Hauptgründe,warum Sie eine geschichtete Stichprobe gegenüber einer einfachen Zufallsstichprobe bevorzugen., Erstens wird sichergestellt, dass Sie nicht nur die Gesamtbevölkerung, sondern auch wichtige Untergruppen der Bevölkerung, insbesondere kleine Minderheitengruppen, vertreten können. Wenn Sie über Untergruppen sprechen möchten, ist dies möglicherweise der einzige Weg, um effektiv sicherzustellen, dass Sie dies können. Wenn die Untergruppe extrem klein ist, können Sie verschiedene Stichprobenfraktionen (f) innerhalb der verschiedenen Schichten verwenden, um die kleine Gruppe zufällig zu überstichproben (obwohl Sie dann die Schätzungen innerhalb der Gruppe mit der Stichprobenfraktion gewichten müssen, wann immer Sie möchten Gesamtbevölkerungsschätzungen)., Wenn wir innerhalb der Schichten dieselbe Stichprobenfraktion verwenden, führen wir proportional geschichtete Zufallsstichproben durch. Wenn wir verschiedene Stichprobenfraktionen in den Schichten verwenden, nennen wir diese unverhältnismäßige geschichtete Zufallsstichprobe. Zweitens haben geschichtete Zufallsstichproben im Allgemeinen mehr statistische Genauigkeit als einfache Zufallsstichproben. Dies gilt nur, wenn die Schichten oder Gruppen homogen sind. Wenn dies der Fall ist, erwarten wir, dass die Variabilität innerhalb der Gruppen geringer ist als die Variabilität für die gesamte Bevölkerung. Stratified Sampling nutzt diese Tatsache.,
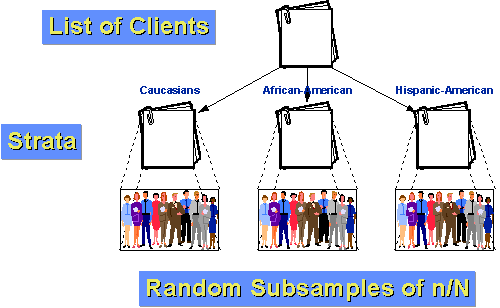
Nehmen wir zum Beispiel an, dass die Kundenpopulation für unsere Agentur in drei Gruppen unterteilt werden kann: kaukasisch, afroamerikanisch und hispanisch-amerikanisch. Nehmen wir außerdem an, dass sowohl die Afroamerikaner als auch die hispanischen Amerikaner relativ kleine Minderheiten der Klientel sind (10% bzw. 5%)., Wenn wir nur eine einfache Zufallsstichprobe von n=100 mit einem Abtastanteil von 10%, würden wir nur zufällig erwarten, dass wir nur 10 und 5 Personen aus jeder unserer beiden kleineren Gruppen erhalten würden. Und durch Zufall könnten wir weniger bekommen! Wenn wir stratifizieren, können wir es besser machen. Bestimmen wir zunächst, wie viele Personen wir in jeder Gruppe haben möchten. Nehmen wir an, wir möchten immer noch eine Stichprobe von 100 aus der Bevölkerung von 1000 Kunden im vergangenen Jahr entnehmen. Aber wir denken, dass wir mindestens 25 Fälle in jeder Gruppe benötigen, um etwas über Untergruppen zu sagen., Lassen Sie uns also 50 Kaukasier, 25 Afroamerikaner und 25 hispanische Amerikaner probieren. Wir wissen, dass 10% der Bevölkerung oder 100 Kunden Afroamerikaner sind. Wenn wir zufällig 25 davon abtasten, haben wir eine innerhalb der Schicht Abtastfraktion von 25/100 = 25%. Ebenso wissen wir, dass 5% oder 50 Kunden hispanisch-amerikanisch sind. Unsere innerhalb der Schicht Abtastfraktion ist also 25/50 = 50%. Schließlich wissen wir durch Subtraktion, dass es 850 kaukasische Kunden gibt. Unsere innerhalb der Schicht Abtastfraktion für sie ist 50/850 = about 5.88%., Da die Gruppen innerhalb der Gruppe homogener sind als in der gesamten Bevölkerung, können wir eine größere statistische Genauigkeit (weniger Varianz) erwarten. Und weil wir geschichtet haben, wissen wir, dass wir genug Fälle aus jeder Gruppe haben werden, um aussagekräftige Untergruppenabschlüsse zu treffen.,hier sind die Schritte, die Sie befolgen müssen, um eine systematische Zufallsstichprobe zu erhalten:
- Nummerieren Sie die Einheiten in der Population von
1bis - Entscheiden Sie sich für die
n(sample size), die Sie möchten oder benötigen - = die Intervallgröße
- Wählen Sie zufällig eine Ganzzahl zwischen
1bisk - dann nehmen Sie jede
kthEinheit

All dies wird viel einfacher klarer mit einem Beispiel., Nehmen wir an, wir haben eine Population mit nur N=100 Personen und Sie möchten eine Stichprobe von n=20 nehmen. Um eine systematische Stichprobe zu verwenden, muss die Population in zufälliger Reihenfolge aufgeführt werden. Die stichprobengruppe wäre f = 20/100 = 20%. in diesem Fall ist die Intervallgröße k gleich N/n = 100/20 = 5. Wählen Sie nun eine zufällige Ganzzahl aus 1 to 5. Stellen Sie sich in unserem Beispiel vor, Sie hätten 4., Um nun das Beispiel auszuwählen, beginnen Sie mit der4th – Einheit in der Liste und nehmen Sie jedek-th – Einheit (jede 5., weil k=5). Sie würden die Einheiten 4, 9, 14, 19 usw. auf 100 abtasten und Sie würden mit 20 Einheiten in Ihrer Probe enden.
Damit dies funktioniert, ist es wichtig, dass die Einheiten in der Population zumindest in Bezug auf die von Ihnen gemessenen Merkmale zufällig geordnet sind. Warum sollten Sie jemals systematische Zufallsstichproben verwenden möchten? Zum einen ist es ziemlich einfach zu tun. Sie müssen nur eine einzelne Zufallszahl auswählen, um die Dinge zu starten., Es kann auch genauer sein als einfache Zufallsstichproben. Schließlich gibt es in einigen Situationen einfach keine einfachere Möglichkeit, eine Zufallsstichprobe durchzuführen. Zum Beispiel musste ich einmal eine Studie durchführen, bei der alle Bücher in einer Bibliothek entnommen wurden. Einmal ausgewählt, müsste ich in das Regal gehen, das Buch suchen und aufzeichnen, wann es zuletzt im Umlauf war. Ich wusste, dass ich einen ziemlich guten Stichprobenrahmen in Form der Regalliste hatte (ein Kartenkatalog, in dem die Einträge in der Reihenfolge angeordnet sind, in der sie im Regal vorkommen)., Um eine einfache Zufallsstichprobe durchzuführen, hätte ich die Gesamtzahl der Bücher schätzen und Zufallszahlen generieren können, um die Stichprobe zu zeichnen. aber wie würde ich book #74,329 leicht finden, wenn das die Nummer ist, die ich ausgewählt habe? Ich konnte die Karten nicht sehr gut zählen, bis ich zu 74,329 kam! Stratifizierung würde dieses Problem auch nicht lösen. Zum Beispiel hätte ich nach Kartenkatalogschublade geschichtet und eine einfache Zufallsstichprobe in jeder Schublade gezeichnet. Aber ich würde immer noch Karten zählen. Stattdessen habe ich eine systematische Zufallsstichprobe gemacht. Ich schätzte die Anzahl der Bücher in der gesamten Sammlung. Stellen wir uns vor, es waren 100.000., Ich entschied, dass ich eine Stichprobe von 1000 für einen Abtastanteil von 1000/100,000 = 1%. Um das Abtastintervall k zu erhalten, habe ich N/n = 100,000/1000 = 100geteilt. Dann habe ich eine zufällige Ganzzahl zwischen 1 und 100ausgewählt. Angenommen, ich habe 57.
Als nächstes habe ich eine kleine Nebenstudie durchgeführt, um festzustellen, wie dick tausend Karten im Kartenkatalog sind (unter Berücksichtigung des unterschiedlichen Alters der Karten)., Nehmen wir an, ich habe im Durchschnitt festgestellt, dass zwei Karten, die durch 100 Karten getrennt waren, in der Katalogschublade etwa .75 auseinander lagen. Diese Information gab mir alles, was ich brauchte, um die Probe zu zeichnen. Ich zählte bis zum 57. von Hand und zeichnete die Buchinformationen auf. Dann nahm ich einen Kompass. (Erinnern Sie sich an die aus Ihrer High-School-Mathe-Klasse? Sie sind die lustigen kleinen Metallinstrumente mit einem scharfen Stift an einem Ende und einem Bleistift am anderen Ende, mit denen Sie Kreise in der Geometrieklasse gezeichnet haben.,) Dann setze ich den Kompass auf .75", steckte das Stiftende in die 57.Karte und zeigte mit dem Stiftende auf die nächste Karte (ca. Auf diese Weise näherte ich mich der Auswahl der 157., 257., 357. und so weiter. Mit diesem systematischen Zufallsstichprobenansatz konnte ich das gesamte Auswahlverfahren in kürzester Zeit durchführen. Ich würde wahrscheinlich immer noch Karten zählen, wenn ich eine andere Zufallsstichprobenmethode ausprobiert hätte. (Okay, also ich habe kein Leben. Ich bin gut entschädigt worden, ich habe nichts dagegen zu sagen, dass ich dieses Schema entwickelt habe.,)
Cluster (Area) Random Sampling
Das Problem bei Zufallsstichprobenverfahren, wenn wir eine Population abtasten müssen, die in einer breiten geografischen Region ausgezahlt wird, besteht darin, dass Sie viel Boden abdecken müssen geographisch, um zu jeder der Einheiten zu gelangen, die Sie abgetastet haben. Stellen Sie sich vor, Sie nehmen eine einfache Zufallsstichprobe aller Einwohner des Staates New York, um persönliche Interviews zu führen. Durch das Glück der Auslosung werden Sie mit Befragten enden, die aus dem ganzen Staat kommen. Ihre Interviewer werden viel Reisen zu tun haben., Genau für dieses Problem wurde eine Cluster – oder Flächenzufallsstichprobe erfunden.
Bei der Clusterstichprobe führen wir folgende Schritte aus:
- Bevölkerung in Cluster unterteilen (normalerweise entlang geografischer Grenzen)
- zufällig ausgewählte Cluster
- Messen Sie alle Einheiten in abgetasteten Clustern
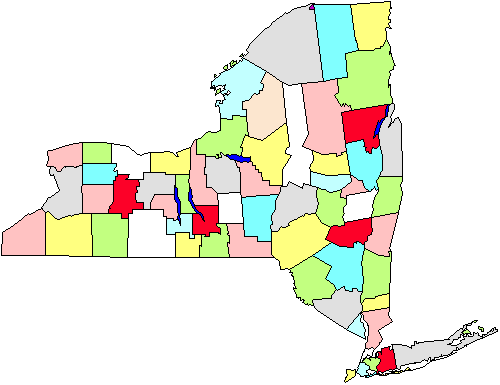
In der Abbildung sehen wir beispielsweise eine Karte der Grafschaften im Bundesstaat New York. Nehmen wir an, wir müssen eine Umfrage unter den Stadtregierungen durchführen, bei der wir persönlich in die Städte gehen müssen., Wenn wir eine einfache Zufallsstichprobe landesweit machen, müssen wir den gesamten Staat geographisch abdecken. Stattdessen entscheiden wir uns für eine Cluster-Stichprobe von fünf Landkreisen (in der Abbildung rot markiert). Sobald diese ausgewählt sind, gehen wir zu jeder Stadtregierung in den fünf Bereichen. Diese Strategie wird uns natürlich helfen, unsere Laufleistung zu sparen. Cluster-oder Flächenstichproben sind daher in solchen Situationen nützlich und werden hauptsächlich zur Effizienz der Verwaltung durchgeführt., Beachten Sie auch, dass wir uns wahrscheinlich keine Gedanken über die Verwendung dieses Ansatzes machen müssen, wenn wir eine E-Mail-oder Telefonumfrage durchführen, da es nicht so wichtig ist (oder mehr kostet oder Ineffizienz erhöht), wo wir anrufen oder Briefe senden.
Mehrstufige Probenahme
Die vier bisher behandelten Methoden – einfache, geschichtete, systematische und Cluster – sind die einfachsten Zufallsstichprobenstrategien. In den meisten realen angewandten Sozialforschung würden wir Stichprobenverfahren verwenden, die wesentlich komplexer sind als diese einfachen Variationen., Das wichtigste Prinzip hierbei ist, dass wir die zuvor beschriebenen einfachen Methoden auf eine Vielzahl nützlicher Arten kombinieren können, die uns helfen, unsere Stichprobenanforderungen so effizient und effektiv wie möglich zu erfüllen. Wenn wir Probenahmeverfahren kombinieren, nennen wir diese mehrstufige Probenahme.
Betrachten Sie zum Beispiel die Idee, Einwohner des Staates New York für persönliche Interviews zu befragen. Natürlich möchten wir als erste Phase des Prozesses eine Art Cluster-Sampling durchführen. Wir könnten Townships oder Census Tracts im ganzen Staat probieren., Bei der Clusterstichprobe würden wir dann jedoch alle in den von uns ausgewählten Clustern messen. Selbst wenn wir Census Tracts proben, können wir möglicherweise nicht jeden messen, der sich im Census Tract befindet. Wir könnten also einen geschichteten Stichprobenprozess innerhalb der Cluster einrichten. In diesem Fall hätten wir einen zweistufigen Probenahmevorgang mit geschichteten Proben innerhalb von Clusterproben. Oder betrachten Sie das Problem der Stichprobe von Schülern in Grundschulen. Wir könnten mit einer nationalen Stichprobe von Schulbezirken beginnen, die nach Wirtschaft und Bildungsniveau geschichtet sind., Innerhalb ausgewählter Bezirke könnten wir eine einfache Zufallsstichprobe von Schulen durchführen. Innerhalb von Schulen können wir eine einfache Zufallsstichprobe von Klassen oder Klassen durchführen. Und innerhalb des Unterrichts können wir sogar eine einfache Zufallsstichprobe von Schülern durchführen. In diesem Fall haben wir drei oder vier Stufen im Stichprobenprozess und verwenden sowohl geschichtete als auch einfache Zufallsstichproben. Durch die Kombination verschiedener Stichprobenmethoden sind wir in der Lage, eine Vielzahl probabilistischer Stichprobenmethoden zu erreichen, die in einer Vielzahl von Sozialforschungskontexten eingesetzt werden können.