introduktion
Sorteringsdata innebär att man ordnar det i en viss ordning, ofta i en array-liknande datastruktur. Du kan använda olika beställningskriterier, vanliga är sorteringsnummer från minst till största eller vice versa, eller sortering strängar lexikografiskt. Du kan även definiera dina egna kriterier, och vi kommer att gå in på praktiska sätt att göra det i slutet av den här artikeln.,
om du är intresserad av hur sortering fungerar täcker vi olika algoritmer, från ineffektiva men intuitiva lösningar, till effektiva algoritmer som faktiskt implementeras i Java och andra språk.
det finns olika sorteringsalgoritmer, och de är inte alla lika effektiva. Vi kommer att analysera sin tid komplexitet för att jämföra dem och se vilka som utför bäst.,
listan över algoritmer som du lär dig här är inte alls uttömmande, men vi har sammanställt några av de vanligaste och mest effektiva som hjälper dig att komma igång:
- Bubble Sort
- Insertionssort
- Selection Sort
- Merge Sort
- Heapsort
- Quicksort
- sortering i Java
Obs: den här artikeln kommer att inte att göra med samtidig sortering, eftersom det är avsett för nybörjare.
Bubble Sort
förklaring
Bubble sort fungerar genom att byta intilliggande element om de inte är i önskad ordning., Denna process upprepas från början av matrisen tills alla element är i ordning.
vi vet att alla element är i ordning när vi lyckas göra hela iterationen utan att byta alls-då var alla element vi jämförde i önskad ordning med sina intilliggande element, och i förlängningen hela matrisen.
här är stegen för att sortera en rad siffror från minst till största:
-
4 2 1 5 3: de två första elementen är i fel ordning,så vi byter dem.
-
2 4 1 5 3: de andra två elementen är också i fel ordning, så vi byter.,
-
2 1 4 5 3: Dessa två är i rätt ordning, 4 < 5, Så vi lämnar dem ensamma.
-
2 1 4 5 3: en annan swap.
-
2 1 4 3 5: här är den resulterande matrisen efter en iteration.
eftersom minst en swap inträffade under det första passet (det fanns faktiskt tre) måste vi gå igenom hela matrisen igen och upprepa samma process.
genom att upprepa denna process, tills inga fler swappar görs, har vi en sorterad array.,
anledningen till att denna algoritm kallas Bubble Sort beror på att siffrorna typ av ”bubbla upp” till ”ytan.”Om du går igenom vårt exempel igen, efter ett visst nummer (4 är ett bra exempel) ser du det långsamt flytta till höger under processen.
alla nummer flyttar till sina respektive platser bit för bit, vänster till höger, som bubblor långsamt stiger från en vattensamling.
om du vill läsa en detaljerad, dedikerad artikel för Bubble Sort, har vi dig täckt!,
implementering
Vi kommer att implementera bubbla Sortera på ett liknande sätt som vi har lagt ut det i ord. Vår funktion går in ett tag slinga där den går igenom hela matrisen byta efter behov.
vi antar att matrisen är sorterad, men om vi har visat oss fel vid sortering (om en swap händer) går vi igenom en annan iteration. While-loop fortsätter sedan tills vi lyckas passera genom hela matrisen utan att byta:
När vi använder denna algoritm måste vi vara försiktiga med hur vi anger vårt swap-tillstånd.,
om jag till exempel hade använt a >= akunde det ha slutat med en oändlig slinga, eftersom det för lika delar alltid skulle varatrue och därmed alltid byta dem.
tidskomplexitet
för att räkna ut tidskomplexitet av Bubbelsort måste vi titta på det värsta möjliga scenariot. Vad är det maximala antalet gånger vi behöver för att passera hela matrisen innan vi har sorterat det?, Tänk på följande exempel:
5 4 3 2 1i den första iterationen kommer 5 att” bubbla upp till ytan”, men resten av elementen skulle stanna i fallande ordning. Vi skulle behöva göra en iteration för varje element utom 1, och sedan en annan iteration för att kontrollera att allt är i ordning, så totalt 5 iterationer.
utöka detta till alla typer avn element, och det betyder att du måste göran iterationer., Om man tittar på koden skulle det innebära att vårawhile loop kan köra maximaltn gånger.
var och en av dessan gånger vi itererar genom hela matrisen (för-loop i koden), vilket betyder att den värsta falltidskomplexiteten skulle vara O(n^2).
notera: tidskomplexiteten skulle alltid vara O(n^2) om det inte var för sorted boolesk kontroll, vilket avslutar algoritmen om det inte finns några swappar inom den inre slingan – vilket innebär att matrisen sorteras.,
insättningssortering
förklaring
idén bakom insättningssortering delar upp matrisen i de sorterade och osorterade subarrayerna.
den sorterade delen är av Längd 1 i början och motsvarar det första (vänster mest) elementet i matrisen. Vi itererar genom matrisen och under varje iteration utökar vi den sorterade delen av matrisen med ett element.
När vi expanderar placerar vi det nya elementet på rätt plats inom den sorterade subarrayen. Vi gör detta genom att flytta alla element till höger tills vi möter det första elementet som vi inte behöver flytta.,
till exempel, om i följande matris den bultade delen sorteras i stigande ordning, händer följande:
-
3 5 7 8 4 2 1 9 6: Vi tar 4 och kom ihåg att det är vad vi behöver infoga. Eftersom 8> 4 skiftar vi.
-
3 5 7 x 8 2 1 9 6: där värdet av x inte är av avgörande betydelse, eftersom det kommer att skrivas över omedelbart (antingen med 4 om det är lämpligt ställe eller med 7 om vi byter). Eftersom 7> 4 skiftar vi.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Efter denna process utvidgades den sorterade delen med ett element, vi har nu fem snarare än fyra element. Varje iteration gör detta och i slutet kommer vi att ha hela matrisen sorterade.
om du vill läsa en detaljerad, dedikerad artikel för insättningssortering, har vi dig täckt!,
implementering
tidskomplexitet
igen måste vi titta på det värsta scenariot för vår algoritm, och det kommer igen att vara exemplet där hela matrisen sjunker.
detta beror på att i varje iteration måste vi flytta hela den sorterade listan efter en, vilket är O(n). Vi måste göra detta för varje element i varje matris, vilket innebär att det kommer att begränsas av O (N^2).
Selection Sort
Explanation
Selection Sort delar också matrisen i en sorterad och osorterad subarray., Men den här gången bildas den sorterade subarrayen genom att sätta in det minsta elementet i den osorterade subarrayen i slutet av den sorterade matrisen, genom att byta:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 5 1 2 3 4 5
-
1 2 3 4 5
implementering
i varje iteration antar vi att det första osorterade elementet är det minsta och iterera genom resten för att se om det finns ett mindre element.,
När vi hittar det nuvarande minimumet för den osorterade delen av matrisen byter vi det med det första elementet och anser att det är en del av den sorterade matrisen:
tidskomplexitet
att hitta minsta är O(n) för längden på matrisen eftersom vi måste kontrollera alla element. Vi måste hitta ett minimum för varje element i matrisen, vilket gör hela processen avgränsad av O (N^2).,
Merge Sort
förklaring
Merge Sort använder rekursion för att lösa problemet med sortering mer effektivt än algoritmer som tidigare presenterats, och i synnerhet den använder en klyfta och erövra strategi.
genom att använda båda dessa begrepp bryter vi ner hela matrisen i två subarrays och sedan:
- Sortera den vänstra halvan av matrisen (rekursivt)
- Sortera den högra halvan av matrisen (rekursivt)
- slå samman lösningarna
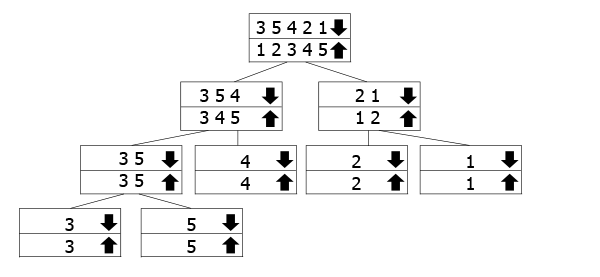
det här trädet är tänkt att representera hur rekursivsystemet fungerar.samtal fungerar., Matriserna markerade med nedåtpilen är de som vi kallar funktionen för, medan vi sammanfogar uppåtpilen som går tillbaka upp. Så du följer nedåtpilen till botten av trädet, och sedan gå tillbaka upp och slå samman.
i vårt exempel har vi matrisen 3 5 3 2 1, så vi delar upp den i 3 5 4 och 2 1. För att sortera dem delar vi dem vidare i sina komponenter. När vi har nått botten, börjar vi slå samman och sortera dem när vi går.,
om du vill läsa en detaljerad, dedikerad artikel för Merge Sort, har vi dig täckt!
implementering
kärnfunktionen fungerar ganska mycket som anges i förklaringen. Vi skickar bara index left och right som är index för den vänstra och högra delen av subarrayen vi vill sortera. Inledningsvis bör dessa vara0 ocharray.length-1, beroende på implementering.,
basen för vår rekursion säkerställer att vi avslutar när vi är klara, eller när rightochleft möter varandra. Vi hittar en mittpunkt mid, och sortera subarrays vänster och höger om det rekursivt, slutligen sammanfoga våra lösningar.
om du kommer ihåg vår trädgrafik kanske du undrar varför vi inte skapar två nya mindre matriser och skickar dem vidare istället. Detta beror på att på riktigt långa matriser skulle detta orsaka stor minnesförbrukning för något som i huvudsak är onödigt.,
sammanfoga Sortera fungerar redan inte på plats på grund av sammanfogningssteget, och detta skulle bara tjäna till att förvärra dess minneseffektivitet. Logiken i vårt rekursionsträd förblir annars densamma, men vi måste bara följa de index som vi använder:
för att slå samman de sorterade subarrayerna i en, måste vi beräkna längden på var och en och göra tillfälliga arrayer för att kopiera dem till, så att vi fritt kan ändra vår huvudmatris.
efter kopiering går vi igenom den resulterande matrisen och tilldelar den nuvarande miniminivån., Eftersom våra subarrays sorteras valde vi bara de mindre av de två elementen som inte har valts hittills och flyttar iteratorn för den subarrayen framåt:
tidskomplexitet
om vi vill härleda komplexiteten hos rekursiva algoritmer måste vi få lite mathy.
Huvudteoremet används för att räkna ut tidskomplexiteten hos rekursiva algoritmer. För icke-rekursiva algoritmer kan vi vanligtvis skriva den exakta tidskomplexiteten som någon form av ekvation, och sedan använder vi Big-O-Notation för att sortera dem i klasser av liknande algoritmer.,
problemet med rekursiva algoritmer är att samma ekvation skulle se ut så här:
$$
t(n) = aT(\frac{n}{b}) + cn^k
$$
ekvationen i sig är rekursiv! I denna ekvation berättar a hur många gånger vi kallar rekursionen, och b berättar för oss hur många delar vårt problem är uppdelat. I det här fallet kan det verka som en obetydlig skillnad eftersom de är lika för sammanslagningar, men för vissa problem kan de inte vara.,
resten av ekvationen är komplexiteten att slå samman alla dessa lösningar till en i slutet., Master Theorem löser denna ekvation för oss:
$$
t(n) = \Bigg\{
\begin{matrix}
o(n^{log_ba}), & a>b^k \\ O(n^klog n), & a = b^k \\ o(n^k), & a < b^k
\end{matrix}
$$
om T(n) är algoritmens körtid vid sortering av en matris av längden n, sammanfogningssortering skulle köras två gånger för matriser som är halva längden på den ursprungliga matrisen.,
så om vi har a=2, b=2. Sammanfogningssteget tar o (n) minne, så k=1. Det betyder att ekvationen för Sammanslagningssortering skulle se ut som följer:
$$
t(n) = 2T(\frac{n}{2})+cn
$$
om vi tillämpar Master-teoremet ser vi att vårt fall är det där a=b^k eftersom vi har 2=2^1. Det betyder att vår komplexitet är O (nlog n). Det här är en extremt bra tidskomplexitet för en sorteringsalgoritm, eftersom det har visat sig att en array inte kan sorteras snabbare än O(nlog n).,
medan den version vi har presenterat är minneskrävande, finns det mer komplexa versioner av Sammanslagningssortering som bara tar upp o(1) Utrymme.
dessutom är algoritmen extremt lätt att parallellisera, eftersom rekursiva samtal från en nod kan köras helt oberoende av separata grenar. Medan vi inte kommer att komma in i hur och varför, eftersom det ligger utanför ramen för den här artikeln, är det värt att komma ihåg proffsen att använda den här algoritmen.,
Heapsort
förklaring
för att korrekt förstå varför Heapsort fungerar måste du först förstå strukturen den bygger på – högen. Vi kommer att prata när det gäller en binär hög specifikt, men du kan generalisera det mesta till andra högstrukturer också.
en hög är ett träd som uppfyller heap-egenskapen, vilket är att för varje nod är alla dess barn i en given relation till den. Dessutom måste en hög vara nästan komplett., Ett nästan komplett binärt djupträd d har en underträd av djup d-1 med samma rot som är komplett, och där varje nod med en vänster nedförsbacke har en komplett vänster underträd. Med andra ord, när vi lägger till en nod, går vi alltid till vänster i högsta ofullständiga nivå.
om högen är en maxhög, är alla barnen mindre än föräldern, och om det är en minhög är alla större.,
med andra ord, när du flyttar ner trädet, kommer du till mindre och mindre tal (min-heap) eller större och större tal (max-heap). Här är ett exempel på en max-heap:
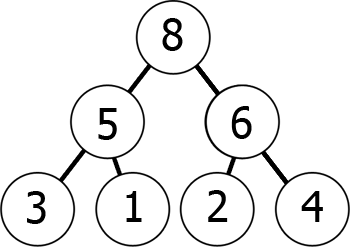
Vi kan representera denna max-heap i minnet som en array på följande sätt:
8 5 6 3 1 2 4Du kan föreställa dig det som att läsa från grafnivån efter nivå, vänster till höger., Vad vi har uppnått med detta är att om vi tar kth – elementet i matrisen är dess barnpositioner 2*k+1 och 2*k+2 (förutsatt att indexeringen börjar vid 0). Du kan kontrollera detta själv.
omvänt, för elementetkth är den överordnade positionen alltid(k-1)/2.
att veta detta kan du enkelt ”max-heapify” någon given array. För varje element, kontrollera om något av dess barn är mindre än det., Om de är, Byt en av dem med föräldern och upprepa detta steg rekursivt med föräldern (eftersom det nya stora elementet fortfarande kan vara större än det andra barnet).
löv har inga barn, så de är trivialt max-heaps av sina egna:
-
6 1 8 3 5 2 4: båda barnen är mindre än föräldern, så allt förblir detsamma.
-
6 1 8 3 5 2 4: Eftersom 5 > 1 byter vi dem. Vi rekursivt heapify för 5 nu.
-
6 5 8 3 1 2 4: båda barnen är mindre, så ingenting händer.,
-
6 5 8 3 1 2 4: Eftersom 8> 6 byter vi dem.
-
8 5 6 3 1 2 4:vi fick högen bilden ovan!
När vi har lärt oss att heapify en array är resten ganska enkel. Vi byter roten till högen med slutet av matrisen och förkortar matrisen med en.,
vi heapify den förkortade matrisen igen och upprepar processen:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: swapped
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: swapped
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: swapped
och så vidare är jag säker på att du kan se mönstret som dyker upp.
implementering
tidskomplexitet
när vi tittar på funktionenheapify() verkar allt göras i O(1), men då finns det det det irriterande rekursiva samtalet.,
hur många gånger kommer det att kallas, i värsta fall? Tja, i värsta fall kommer det att sprida sig hela vägen till toppen av högen. Det kommer att göra det genom att hoppa till föräldern i varje nod, så runt positionen i/2. det betyder att det kommer att göra i värsta fall log n hoppar innan den når toppen, så komplexiteten är O(log n).
eftersom heapSort() är klart O(n) på grund av att för-loopar itererar genom hela matrisen, skulle detta göra den totala komplexiteten hos Heapsort O(nlog n).,
Heapsort är en in-place sort, vilket innebär att det tar O (1) extra utrymme, i motsats till sammanfoga Sortera, men det har också vissa nackdelar, som att vara svårt att parallellisera.
Quicksort
förklaring
Quicksort är en annan Divide and Conquer algoritm. Den plockar ett element i en array som pivot och sorterar alla andra element runt den, till exempel mindre element till vänster och större till höger.
detta garanterar att pivot är på rätt plats efter processen., Då gör algoritmen rekursivt detsamma för vänster och höger delar av matrisen.
implementering
tidskomplexitet
tidskomplexiteten hos Quicksort kan uttryckas med följande ekvation:
$ $
t(n) = t(k) + t(n-k-1) + o (n)
$$
det värsta scenariot är när det största eller minsta elementet alltid plockas för pivot. Ekvationen skulle då se ut så här:
$$
t(n) = t(0) + t(n-1) + O(n) = t(n-1) + O(n)
$$
detta visar sig vara O (n^2).,
detta kan låta dåligt, eftersom vi redan har lärt oss flera algoritmer som körs i O (nlog n) tid som sitt värsta fall, men Quicksort används faktiskt mycket ofta.
detta beror på att den har en riktigt bra genomsnittlig runtime, även avgränsad av O(nlog n), och är mycket effektiv för en stor del av möjliga ingångar.
en av anledningarna till att det är att föredra att slå samman Sortera är att det inte tar något extra utrymme, all sortering sker på plats, och det finns inga dyra allokerings-och avallokeringsanrop.,
Prestandajämförelse
att allt som sägs är det ofta användbart att köra alla dessa algoritmer på din maskin några gånger för att få en uppfattning om hur de fungerar.
de kommer att utföra olika med olika samlingar som sorteras naturligtvis, men även med det i åtanke bör du kunna märka några trender.
låt oss köra alla implementeringar, en efter en, var och en på en kopia av en blandad matris med 10 000 heltal:
Vi kan uppenbarligen se att Bubbelsorteringen är värst när det gäller prestanda., Undvik att använda den i produktion om du inte kan garantera att den kommer att hantera endast små samlingar och det kommer inte att stalla programmet.
HeapSort och QuickSort är de bästa prestanda-wise. Även om de matar ut liknande resultat tenderar QuickSort att vara lite bättre och mer konsekvent – vilket checkar ut.
sortering i Java
jämförbart gränssnitt
Om du har egna typer kan det bli besvärligt att implementera en separat sorteringsalgoritm för var och en. Därför tillhandahåller Java ett gränssnitt som låter dig användaCollections.sort() på dina egna klasser.,
för att göra detta måste din klass implementera gränssnittetComparable<T>, där T är din typ och åsidosätta en metod som heter .compareTo().
denna metod returnerar ett negativt heltal om this är mindre än argumentet, 0 om de är lika, och ett positivt heltal om this är större.
i vårt exempel har vi gjort en klass Student, och varje elev identifieras av en id och ett år började de sina studier.,
vi vill sortera dem främst efter generationer, men också sekundärt av ID:
och här är hur man använder det i ett program:
Output:
Komparatorgränssnitt
vi kanske vill sortera våra objekt på ett oortodoxt sätt för ett visst ändamål, men vi vill inte implementera det som standardbeteendet i vår klass, eller vi kan vara Sortera en samling av en inbyggd typ på ett icke-standard sätt.
för detta kan vi använda gränssnittet Comparator., Låt oss till exempel ta vår Student – klass och sortera endast efter ID:
om vi ersätter sorteringssamtalet i huvudsak med följande:
Arrays.sort(a, new SortByID());utgång:
hur allt fungerar
Collection.sort() fungerar genom att anropa den underliggande Arrays.sort() – metoden, medan sorteringen själv använder insättningssortering för matriser som är kortare än 47 och Quicksort för resten.,
den är baserad på en specifik två-pivot implementering av Quicksort som säkerställer att den undviker de flesta av de typiska orsakerna till nedbrytning i kvadratisk prestanda, enligt jdk10-dokumentationen.
slutsats
sortering är en mycket vanlig operation med datauppsättningar, oavsett om det är att analysera dem ytterligare, påskynda sökningen genom att använda mer effektiva algoritmer som förlitar sig på de data som sorteras, filtrera data, etc.
sortering stöds av många språk och gränssnitten döljer ofta vad som faktiskt händer med programmeraren., Även om denna abstraktion är välkommen och nödvändig för effektivt arbete, kan det ibland vara dödligt för effektivitet, och det är bra att veta hur man implementerar olika algoritmer och vara bekant med sina fördelar och nackdelar, samt hur man enkelt kan komma åt inbyggda implementeringar.