en sannolikhetsurvalsmetod är vilken provtagningsmetod som helst som använder någon form av slumpmässigt urval. För att ha en slumpmässig urvalsmetod måste du ställa in en process eller procedur som försäkrar att de olika enheterna i din befolkning har lika sannolikheter för att väljas. Människor har länge praktiserat olika former av slumpmässigt urval, som att plocka ett namn ur en hatt eller välja det korta strået. Dessa dagar tenderar vi att använda datorer som mekanism för att generera slumptal som grund för slumpmässigt urval.,
vissa definitioner
innan jag kan förklara de olika sannolikhetsmetoderna måste vi definiera några grundläggande termer. Dessa är:
-
När antalet fall i samplingsramen -
när antalet fall i provet -
NCn= antalet kombinationer (delmängder) avnfrånnfrån -
f = n/När samplingsfraktionen
det är det., Med dessa termer definierade kan vi börja definiera de olika sannolikhetsprovtagningsmetoderna.
enkel slumpmässig provtagning
den enklaste formen av slumpmässig provtagning kallas enkel slumpmässig provtagning. Ganska knepigt, va? Här är den snabba beskrivningen av enkel slumpmässig provtagning:
- Objective: to select
nunits out ofNsuch that eachNCnhas a equal chance of be selected. - procedur: använd en tabell med slumptal, en dator slumptalsgenerator eller en mekanisk enhet för att välja provet.,
en något styltad, om exakt, definition. Låt oss se om vi kan göra det lite mer verkligt.

hur väljer vi ett enkelt slumpmässigt prov? Låt oss anta att vi gör lite forskning med en liten servicebyrå som vill bedöma kundernas syn på kvaliteten på tjänsten under det senaste året. Först måste vi ordna provtagningsramen. För att åstadkomma detta, går vi igenom byrån register för att identifiera varje kund under de senaste 12 månaderna. Om vi har tur har byrån bra exakta datoriserade poster och kan snabbt producera en sådan lista., Då måste vi faktiskt rita provet. Bestäm antalet kunder du vill ha i det slutliga provet. För exemplet, låt oss säga att du vill välja 100 kunder att kartlägga och att det fanns 1000 kunder under de senaste 12 månaderna. Sedan är provtagningsfraktionen f = n/N = 100/1000 = .10 (eller 10%). Nu, för att faktiskt rita provet, har du flera alternativ. Du kan skriva ut listan över 1000 klienter, riva sedan i separata remsor, lägg remsorna i en hatt, blanda dem riktigt bra, stäng dina ögon och dra ut de första 100., Men det här mekaniska förfarandet skulle vara tråkigt och kvaliteten på provet skulle bero på hur noggrant du blandade dem och hur slumpmässigt Du nådde in. Kanske ett bättre förfarande skulle vara att använda den typ av boll maskin som är populär bland många av de statliga lotterier. Du skulle behöva tre uppsättningar bollar numrerade 0 till 9, en uppsättning för var och en av siffrorna från 000 till 999 (om vi väljer 000 vi kallar det 1000)., Numrera listan med namn från1 till1000 och använd sedan kulmaskinen för att välja de tre siffrorna som väljer varje person. Den uppenbara nackdelen här är att du måste få bollmaskinerna. (Var gör de dessa saker, hur som helst? Finns det en boll maskin industrin?).
ingen av dessa mekaniska procedurer är mycket genomförbar och med utvecklingen av billiga datorer finns det ett mycket enklare sätt. Här är ett enkelt förfarande som är särskilt användbart om du har namnen på klienterna redan på datorn., Många datorprogram kan generera en serie slumptal. Låt oss anta att du kan kopiera och klistra in listan över kundnamn i en kolumn i ett EXCEL-kalkylblad. Sedan, i kolumnen bredvid den klistra in funktionen =RAND() vilket är excels sätt att sätta ett slumptal mellan 0 och 1 I cellerna. Sortera sedan båda kolumnerna – listan över namn och slumptal – med slumptal. Detta omarrangerar listan i slumpmässig ordning från lägsta till högsta slumptal., Sedan, allt du behöver göra är att ta de första hundra namnen i denna sorterade lista. ganska enkelt. Du kan nog göra det på mindre än en minut.
enkel slumpmässig provtagning är enkel att utföra och är lätt att förklara för andra. Eftersom enkel slumpmässig provtagning är ett rättvist sätt att välja ett prov är det rimligt att generalisera resultaten från provet tillbaka till befolkningen. Enkel slumpmässig provtagning är inte den mest statistiskt effektiva provtagningsmetoden och du kan, bara på grund av dragningens tur, inte få bra representation av undergrupper i en population., För att hantera dessa frågor måste vi vända oss till andra provtagningsmetoder.
stratifierad slumpmässig provtagning
stratifierad slumpmässig provtagning, även ibland kallad proportionell eller kvot slumpmässig provtagning, innebär att din befolkning delas upp i homogena undergrupper och sedan tar ett enkelt slumpmässigt prov i varje undergrupp. I mer formella termer:
det finns flera viktiga skäl till varför du kanske föredrar stratifierad provtagning över enkel slumpmässig provtagning., För det första försäkrar det att du kommer att kunna representera inte bara den totala befolkningen utan också viktiga undergrupper av befolkningen, särskilt små minoritetsgrupper. Om du vill kunna prata om undergrupper, kan detta vara det enda sättet att effektivt försäkra dig om att du kommer att kunna. Om undergruppen är extremt liten kan du använda olika provtagningsfraktioner (f) inom de olika lagren för att slumpmässigt överprova den lilla gruppen (även om du då måste väga inomgruppsuppskattningarna med hjälp av provtagningsfraktionen när du vill ha övergripande populationsuppskattningar)., När vi använder samma provtagningsfraktion inom strata genomför vi proportionell stratifierad slumpmässig provtagning. När vi använder olika provtagningsfraktioner i lagren kallar vi denna oproportionerliga stratifierade slumpmässiga provtagning. För det andra kommer stratifierad slumpmässig provtagning i allmänhet att ha mer statistisk precision än enkel slumpmässig provtagning. Detta kommer bara att vara sant om lagren eller grupperna är homogena. Om de är, förväntar vi oss att variabiliteten inom-grupper är lägre än variabiliteten för befolkningen som helhet. Stratifierad provtagning kapitaliserar på det faktum.,
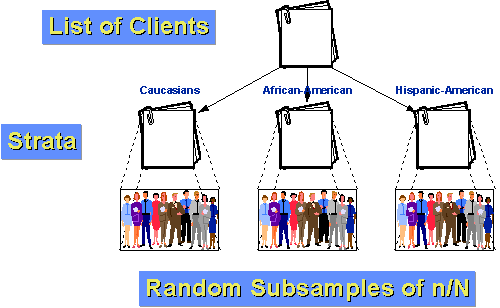
till exempel, låt oss säga att befolkningen av kunder för vår byrå kan delas in i tre grupper: kaukasiska, afroamerikanska och latinamerikanska-amerikanska. Låt oss dessutom anta att både afroamerikaner och latinamerikaner är relativt små minoriteter av kundkretsen (10% och 5% respektive)., Om vi bara gjorde ett enkelt slumpmässigt urval av n=100 med en provtagningsfraktion av 10%, förväntar vi oss av en slump att vi bara skulle få 10 och 5 personer från var och en av våra två mindre grupper. Och av en slump kan vi få färre än så! Om vi stratifierar, kan vi göra bättre. Låt oss först bestämma hur många människor vi vill ha i varje grupp. Låt oss säga att vi fortfarande vill ta ett urval av 100 från befolkningen på 1000 kunder under det senaste året. Men vi tror att för att kunna säga något om undergrupper behöver vi minst 25 fall i varje grupp., Så, låt oss prova 50 Kaukasier, 25 afroamerikaner och 25 Spanskamerikaner. Vi vet att 10% av befolkningen, eller 100 kunder, är afroamerikanska. Om vi slumpmässigt provar 25 av dessa har vi en provtagningsfraktion inom stratum av 25/100 = 25%. På samma sätt vet vi att 5% eller 50 kunder är Spanskamerikaner. Så vår samplingsfraktion inom stratum kommer att vara 25/50 = 50%. Slutligen, genom subtraktion vet vi att det finns 850 kaukasiska kunder. Vår samplingsfraktion inom stratum för dem är 50/850 = about 5.88%., Eftersom grupperna är mer homogena inom gruppen än över hela befolkningen som helhet kan vi förvänta oss större statistisk precision (mindre varians). Och eftersom vi stratifierade, vet vi att vi kommer att ha tillräckligt med fall från varje grupp för att göra meningsfulla undergrupper slutsatser.,e är de steg du måste följa för att uppnå ett systematiskt slumpmässigt urval:
- numrera enheterna i befolkningen från
1tillN - Bestäm om
n(provstorlek) som du vill ha eller behöver - iv id=”c0508aea2e = intervallstorleken
- välj slumpmässigt ett heltal mellan
1tillk - ta sedan varje
kthenhet

ar mycket tydligare med ett exempel., Låt oss anta att vi har en befolkning som bara har n = 100 personer i den och att du vill ta ett urval av n=20. För att använda systematisk provtagning måste populationen listas i slumpmässig ordning. Provtagningsfraktionen skulle varaf = 20/100 = 20%. i detta fall är intervallstorleken,k, lika medN/n = 100/20 = 5. Välj nu ett slumpmässigt heltal från1 to 5. I vårt exempel, föreställ dig att du valde4., Nu, för att välja provet, börja med enheten4thI listan och ta varjek-thenhet (var 5: e, eftersom k=5). Du skulle vara provtagningsenheter 4, 9, 14, 19, och så vidare till 100 och du skulle sluta med 20 enheter i ditt prov.
för att detta ska fungera är det viktigt att enheterna i befolkningen slumpmässigt beställs, åtminstone med avseende på de egenskaper du mäter. Varför skulle du någonsin vilja använda systematisk slumpmässig provtagning? För en sak är det ganska lätt att göra. Du behöver bara välja ett enda slumptal för att starta saker., Det kan också vara mer exakt än enkel slumpmässig provtagning. Slutligen finns det i vissa situationer helt enkelt inget enklare sätt att göra slumpmässig provtagning. Till exempel var jag en gång tvungen att göra en studie som involverade provtagning från alla böcker i ett bibliotek. När jag väl valt, skulle jag behöva gå till hyllan, hitta boken och spela in när den senast cirkulerade. Jag visste att jag hade en ganska bra samplingsram i form av hylllistan (vilket är en kortkatalog där posterna är ordnade i den ordning de förekommer på hyllan)., För att göra ett enkelt slumpmässigt prov kunde jag ha uppskattat det totala antalet böcker och genererade slumptal för att rita provet; men hur skulle jag hitta bok #74,329 enkelt om det är det nummer jag valde? Jag kunde inte mycket väl räkna korten tills jag kom till 74,329! Stratifiering skulle inte lösa det problemet heller. Till exempel kunde jag ha stratifierat med kortkatalog låda och ritat ett enkelt slumpmässigt prov inom varje låda. Men jag skulle fortfarande vara fast räkna kort. Istället gjorde jag ett systematiskt slumpmässigt prov. Jag uppskattade antalet böcker i hela samlingen. Tänk att det var 100 000., Jag bestämde mig för att jag ville ta ett prov på 1000 för en provtagningsfraktion av 1000/100,000 = 1%. För att få samplingsintervalletk delade jagN/n = 100,000/1000 = 100. Sedan valde jag ett slumpmässigt heltal mellan 1 och 100. Låt oss säga att jag fick 57.
därefter gjorde jag en liten sidostudie för att bestämma hur tjocka tusen kort finns i kortkatalogen (med hänsyn till kortens olika åldrar)., Låt oss säga att i genomsnitt fann jag att två kort som separerades av100 kort handlade om.75 inches isär i kataloglådan. Den informationen gav mig allt jag behövde för att rita provet. Jag räknade till den 57: e för hand och spelade in bokinformationen. Sen tog jag en kompass. (Minns du dem från din high-school matte klass? De är de roliga små metallinstrumenten med en skarp stift på ena änden och en penna på den andra som du brukade rita cirklar i geometri klass.,) Sedan satte jag kompassen på .75", fast stiftänden på det 57: e kortet och pekade med penna änden till nästa kort (cirka 100 böcker bort). På så sätt approximerade jag valet av 157: e, 257: e, 357: e och så vidare. Jag kunde utföra hela urvalsförfarandet på väldigt lite tid med hjälp av denna systematiska slumpmässiga provtagningsmetod. Jag skulle förmodligen fortfarande vara där räkna kort om jag hade provat en annan slumpmässig provtagningsmetod. (Okej, så jag har inget liv. Jag fick bra ersättning, jag har inget emot att säga, för att komma med detta system.,)
kluster (område) slumpmässig provtagning
problemet med slumpmässiga provtagningsmetoder när vi måste prova en population som betalas ut över en bred geografisk region är att du måste täcka mycket mark geografiskt för att komma till var och en av de enheter du samplade. Tänk dig att ta ett enkelt slumpmässigt urval av alla invånare i New York State för att genomföra personliga intervjuer. Med tur av dragningen kommer du att sluta med respondenter som kommer från hela staten. Dina intervjuare kommer att ha en hel del resor att göra., Det är för just detta problem att kluster eller area random sampling uppfanns.
i klusterprovtagning följer vi följande steg:
- dela upp befolkningen i kluster (vanligtvis längs geografiska gränser)
- slumpmässigt urvalskluster
- mät alla enheter inom samplade kluster
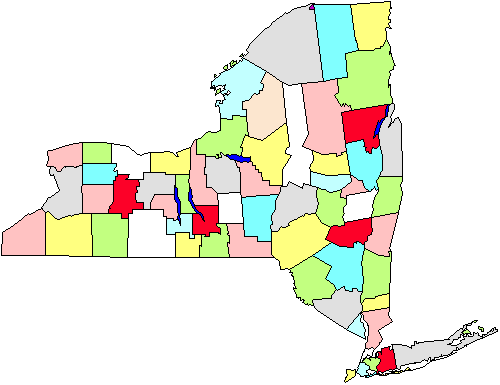
till exempel i figuren ser vi en karta över länen i New York-Staten. Låt oss säga att vi måste göra en undersökning av stadsregeringar som kommer att kräva att vi går till städerna personligen., Om vi gör ett slumpmässigt urval över hela staten måste vi täcka hela staten geografiskt. Istället bestämmer vi oss för att göra en klusterprovtagning av fem län (markerad i rött i figuren). När de har valts ut, går vi till varje stadsregering i de fem områdena. Uppenbarligen kommer denna strategi att hjälpa oss att spara på vår körsträcka. Kluster-eller områdesprovtagning är då användbar i situationer som denna och görs främst för effektivitet i administrationen., Observera också att vi förmodligen inte behöver oroa oss för att använda detta tillvägagångssätt om vi genomför en post-eller telefonundersökning eftersom det inte spelar någon roll så mycket (eller kostar mer eller ökar ineffektiviteten) där vi ringer eller skickar brev till.
Flerstegsprovtagning
de fyra metoderna vi hittills har täckt-enkla, stratifierade, systematiska och kluster – är de enklaste slumpmässiga provtagningsstrategierna. I de flesta verkliga tillämpad social forskning skulle vi använda provtagningsmetoder som är betydligt mer komplexa än dessa enkla variationer., Den viktigaste principen här är att vi kan kombinera de enkla metoder som beskrivits tidigare på olika användbara sätt som hjälper oss att ta itu med våra provtagningsbehov på det mest effektiva och effektiva sättet. När vi kombinerar provtagningsmetoder kallar vi denna flerstegsprovtagning.
till exempel, överväga idén om provtagning New York State invånare för ansikte mot ansikte intervjuer. Det är uppenbart att vi vill göra någon form av klusterprovtagning som det första steget i processen. Vi kan prova townships eller folkräkningar i hela staten., Men i klusterprovtagning skulle vi sedan fortsätta att mäta alla i de kluster vi väljer. Även om vi tar prov på folkräkningskanaler kanske vi inte kan mäta alla som är i folkräkningen. Så vi kan skapa en stratifierad provtagningsprocess inom klustren. I det här fallet skulle vi ha en tvåstegsprovtagningsprocess med stratifierade prover inom klusterprover. Eller överväga problemet med provtagning av studenter i klassskolor. Vi kan börja med ett nationellt urval av skoldistrikt stratifierade av ekonomi och utbildningsnivå., Inom utvalda distrikt kan vi göra ett enkelt slumpmässigt urval av skolor. Inom skolorna kan vi göra ett enkelt slumpmässigt urval av klasser eller betyg. Och inom klasserna kan vi till och med göra ett enkelt slumpmässigt urval av studenter. I det här fallet har vi tre eller fyra steg i provtagningsprocessen och vi använder både stratifierad och enkel slumpmässig provtagning. Genom att kombinera olika provtagningsmetoder kan vi uppnå ett rikt utbud av probabilistiska provtagningsmetoder som kan användas i ett brett spektrum av sociala forskningssammanhang.