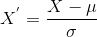introduktion till funktionen skalning
Jag arbetade nyligen med en dataset som hade flera funktioner som spänner över varierande grad av magnitud, intervall och enheter. Detta är ett betydande hinder eftersom några maskininlärningsalgoritmer är mycket känsliga för dessa funktioner.
Jag är säker på att de flesta av er måste ha mött problemet i era projekt eller er inlärningsresa., Till exempel är en funktion helt i kilo medan den andra är i gram, en annan är liter och så vidare. Hur kan vi använda dessa funktioner när de varierar så mycket när det gäller vad de presenterar?
det var här jag vände mig till begreppet funktionsskalning. Det är en viktig del av dataförädlingsstadiet men jag har sett många nybörjare förbise det (till nackdel för deras maskininlärningsmodell).,

här är det nyfikna med funktionsskalning – det förbättrar (signifikant) prestandan hos vissa maskininlärningsalgoritmer och fungerar inte alls för andra. Vad kan vara orsaken till denna quirk?
vad är skillnaden mellan normalisering och standardisering? Dessa är två av de vanligaste funktionerna skalning tekniker i maskininlärning men en nivå av tvetydighet finns i deras förståelse. När ska du använda vilken teknik?,
Jag kommer att svara på dessa frågor och mer i den här artikeln om funktionsskalning. Vi kommer också att implementera funktionsskalning i Python för att ge dig en praktisk förståelse för hur det fungerar för olika maskininlärningsalgoritmer.
OBS: Jag antar att du är bekant med Python och core maskininlärningsalgoritmer., Om du är ny på detta rekommenderar jag att du går igenom följande kurser:
- Python för datavetenskap
- Alla gratis Maskininlärningskurser genom Analytics Vidhya
- tillämpad maskininlärning
Innehållsförteckning
- Varför ska vi använda Funktionsskalning?
- Vad är normalisering?
- Vad är standardisering?
- den stora frågan – normalisera eller standardisera?,
- implementering av Funktionsskalning i Python
- normalisering med Sklearn
- standardisering med Sklearn
- tillämpa Funktionsskalning till maskininlärningsalgoritmer
- k-närmaste grannar (KNN)
- stöd Vektorregressor
- beslutsträd
varför ska vi använda Funktionsskalning?
den första frågan vi behöver ta itu med – varför behöver vi skala variablerna i vår datauppsättning? Vissa maskininlärningsalgoritmer är känsliga för skalning medan andra är praktiskt taget oföränderliga för det., Låt mig förklara det mer detaljerat.
Gradient Descent baserade algoritmer
maskininlärningsalgoritmer som linjär regression, logistisk regression, neuralt nätverk, etc. att använda gradient nedstigning som en optimeringsteknik kräver att data skalas. Ta en titt på formeln för gradient descent nedan:

närvaron av funktionsvärde X i formeln påverkar stegstorleken för gradient descent. Skillnaden i olika funktioner kommer att orsaka olika stegstorlekar för varje funktion., För att säkerställa att gradient nedstigningen rör sig smidigt mot minima och att stegen för gradient nedstigning uppdateras i samma takt för alla funktioner, skalar vi data innan vi matar den till modellen.
att ha funktioner på en liknande skala kan hjälpa gradient descent konvergera snabbare mot minima.
avståndsbaserade algoritmer
Avståndsalgoritmer som KNN, K-means och SVM påverkas mest av olika funktioner., Detta beror på att bakom kulisserna använder de avstånd mellan datapunkter för att bestämma deras likhet.
låt oss till exempel säga att vi har data som innehåller högskolans CGPA-poäng av studenter (från 0 till 5) och deras framtida inkomster (i tusentals Rupier):

eftersom båda funktionerna har olika skalor finns det en chans att högre viktning ges till funktioner med högre Storlek. Detta kommer att påverka prestanda maskininlärningsalgoritmen och självklart vill vi inte att vår algoritm ska vara biased mot en funktion.,
därför skalar vi våra data innan vi använder en avståndsbaserad algoritm så att alla funktioner bidrar lika till resultatet.,B och C, före och efter skalning enligt nedan:
- Distance AB before scaling =>

- Distance BC before scaling =>

- Distance AB efter skalning =>

- distans BC efter skalning =>

skalning har fört både funktionerna i bilden och avstånden är nu mer jämförbara än de var innan vi tillämpade skalning.,
Trädbaserade algoritmer
Trädbaserade algoritmer är å andra sidan ganska okänsliga för omfattningen av funktionerna. Tänk på det, ett beslutsträd delar bara en nod baserat på en enda funktion. Beslutsträdet delar en nod på en funktion som ökar nodens homogenitet. Denna uppdelning på en funktion påverkas inte av andra funktioner.
så det finns praktiskt taget ingen effekt av de återstående funktionerna på uppdelningen. Detta är vad som gör dem invariant till omfattningen av funktionerna!
Vad är normalisering?,
normalisering är en skalningsteknik där värdena skiftas och räddas så att de hamnar mellan 0 och 1. Det är också känt som Min-Max skalning.
här är formeln för normalisering:
Här är Xmax och Xmin de maximala och minimivärdena för funktionen respektive.,
- när värdet av X är det minsta värdet i kolumnen, kommer täljaren att vara 0, och därmed X’ är 0
- å andra sidan, när värdet av X är det maximala värdet i kolumnen, är täljaren lika med nämnaren och därmed värdet av X ’ är 1
- om värdet av X är mellan det lägsta och det maximala värdet, är värdet av X mellan 0 och 1
Vad är standardisering?
standardisering är en annan skalningsteknik där värdena är centrerade kring medelvärdet med en standardavvikelse., Detta innebär att attributets medelvärde blir noll och den resulterande fördelningen har en enhetsstandardavvikelse.
här är formeln för standardisering:
är medelvärdet av funktionsvärdena och
är standardavvikelsen för funktionsvärdena. Observera att värdena i detta fall inte är begränsade till ett visst intervall.
nu måste den stora frågan i ditt sinne vara när ska vi använda normalisering och när ska vi använda standardisering? Låt oss ta reda på det!,
den stora frågan – normalisera eller standardisera?
normalisering vs. standardisering är en evig fråga bland maskininlärning nykomlingar. Låt mig utveckla svaret i det här avsnittet.
- normalisering är bra att använda när du vet att distributionen av dina data inte följer en Gaussisk distribution. Detta kan vara användbart i algoritmer som inte antar någon distribution av data som k-närmaste grannar och neurala nätverk.
- standardisering, å andra sidan, kan vara till hjälp i de fall där data följer en Gaussisk distribution., Detta behöver dock inte nödvändigtvis vara sant. Till skillnad från normalisering har standardisering inte heller ett avgränsningsområde. Så, även om du har outliers i dina data, kommer de inte att påverkas av standardisering.
i slutet av dagen beror valet av att använda normalisering eller standardisering på ditt problem och maskininlärningsalgoritmen du använder. Det finns ingen hård och snabb regel att berätta när du ska normalisera eller standardisera dina data., Du kan alltid börja med att anpassa din modell till rå, normaliserad och standardiserad data och jämföra prestanda för bästa resultat.
det är en bra praxis att passa scaler på träningsdata och sedan använda den för att omvandla testdata. Detta skulle undvika dataläckage under modelltestprocessen. Dessutom krävs inte skalning av målvärden i allmänhet.
implementering av Funktionsskalning i Python
nu kommer det roliga att sätta det vi har lärt oss i praktiken., Jag kommer att tillämpa funktionsskalning till några maskininlärningsalgoritmer på Big Mart dataset jag har tagit DataHack-plattformen.
Jag kommer att hoppa över förbehandlingsstegen eftersom de inte omfattas av denna handledning. Men du kan hitta dem snyggt förklarade i den här artikeln. Dessa steg gör att du kan nå toppen 20 percentilen på hackathon leaderboard så det är värt att kolla in!
så, låt oss först dela upp våra data i träning och testuppsättningar:
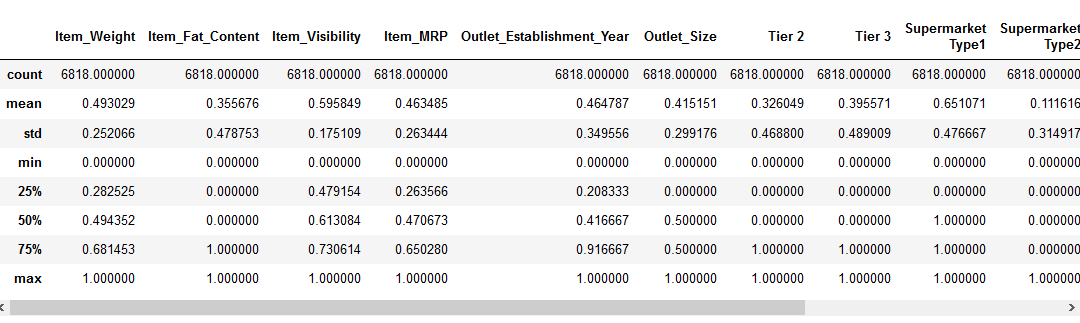
innan vi flyttar till funktionsskalningsdelen, låt oss titta på detaljerna om våra data med PD.,beskriv () metod:
Vi kan se att det finns en stor skillnad i intervallet av värden som finns i våra numeriska funktioner: Item_Visibility, Item_Weight, Item_MRP och Outlet_Establishment_Year. Låt oss försöka fixa det med hjälp av funktionsskalning!
Obs! du kommer att märka negativa värden i Item_Visibility-funktionen eftersom jag har tagit log-transformation för att hantera skevheten i funktionen.
normalisering med sklearn
för att normalisera dina data måste du importera MinMaxScalar från sklearn-biblioteket och tillämpa det på vår dataset., Så, låt oss göra det!
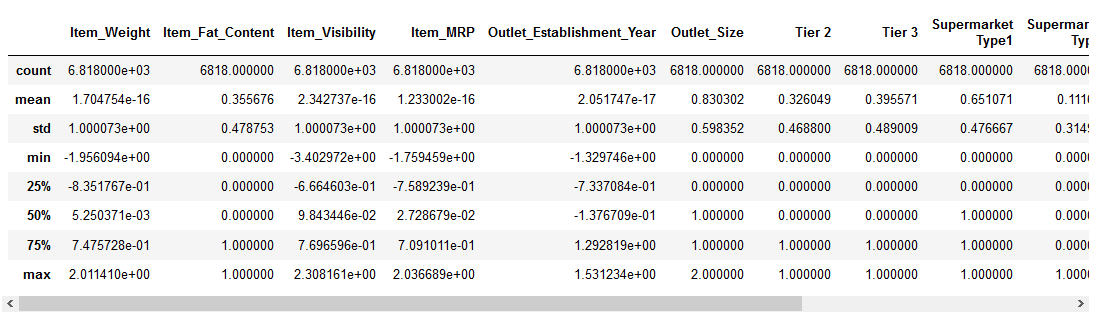
låt oss se hur normalisering har påverkat vår dataset:
alla funktioner har nu ett minimivärde på 0 och ett maximalt värde på 1. Perfekt!
prova ovanstående kod i live coding fönstret nedan!!
låt oss sedan försöka standardisera våra data.
standardisering med sklearn
för att standardisera dina data måste du importera StandardScalar från sklearn-biblioteket och tillämpa det på vår dataset., Så här kan du göra det:
du skulle ha märkt att jag bara tillämpade standardisering på mina numeriska kolumner och inte de andra en-heta kodade funktionerna. Standardisering av de en-Hot-kodade funktionerna skulle innebära att tilldela en distribution till kategoriska funktioner. Du vill inte göra det!
men varför gjorde jag inte detsamma när jag normaliserade data? Eftersom en-Hot-kodade funktioner redan är i intervallet mellan 0 till 1. Så skulle normalisering inte påverka deras värde.,
rätt, låt oss ta en titt på hur standardisering har förändrat våra data:
de numeriska funktionerna är nu centrerade på medelvärdet med en standardavvikelse. Häftig!
jämföra oskalade, normaliserade och standardiserade data
det är alltid bra att visualisera dina data för att förstå distributionen närvarande. Vi kan se jämförelsen mellan våra oskalade och skalade data med hjälp av boxplots.
Du kan läsa mer om datavisualisering här.,
Du kan märka hur skalning funktionerna ger allt i perspektiv. Funktionerna är nu mer jämförbara och kommer att ha en liknande effekt på inlärningsmodellerna.
tillämpa skalning till maskininlärningsalgoritmer
det är nu dags att träna några maskininlärningsalgoritmer på våra data för att jämföra effekterna av olika skalningstekniker på algoritmens prestanda. Jag vill se effekten av skalning på tre algoritmer i synnerhet: K-närmaste grannar, Support Vector Regressor och Decision Tree.,
k-närmaste grannar
som vi såg tidigare är KNN en avståndsbaserad algoritm som påverkas av olika funktioner. Låt oss se hur det fungerar på våra data, före och efter skalning:
Du kan se att skalning av funktionerna har fört ner RMSE-poängen i vår KNN-modell. Specifikt utför de normaliserade data en smula bättre än de standardiserade data.
Obs! jag mäter RMSE här eftersom den här tävlingen utvärderar RMSE.
Support Vector Regressor
SVR är en annan avståndsbaserad algoritm., Så låt oss kolla om det fungerar bättre med normalisering eller standardisering:
Vi kan se att skalning av funktionerna leder ner RMSE-poängen. Och de standardiserade uppgifterna har utförts bättre än de normaliserade uppgifterna. Varför tror du det är så?
sklearn dokumentation anger att SVM, med RBF kärnan, förutsätter att samtliga funktioner är centrerade kring noll och variansen är av samma storleksordning. Detta beror på att en funktion med en varians som är större än andras hindrar estimatorn från att lära av alla funktioner., Toppen!
beslutsträd
vi vet redan att ett beslutsträd är invariant att funktionen skalning. Men jag ville visa ett praktiskt exempel på hur det fungerar på data:
Du kan se att RMSE-poängen inte har flyttat en tum på att skala funktionerna. Så vara säker när du använder trädbaserade algoritmer på dina data!,
slutnot
denna handledning omfattade relevansen av att använda funktionsskalning på dina data och hur normalisering och standardisering har varierande effekter på arbetet med maskininlärningsalgoritmer
Tänk på att det inte finns något korrekt svar på när man ska använda normalisering över standardisering och vice versa. Allt beror på dina data och algoritmen du använder.
som nästa steg uppmuntrar jag dig att prova funktionsskalning med andra algoritmer och räkna ut vad som fungerar bäst-normalisering eller standardisering?, Jag rekommenderar att du använder BigMart försäljningsdata för detta ändamål för att upprätthålla kontinuiteten med den här artikeln. Och glöm inte att dela dina insikter i kommentarerna nedan!
Du kan också läsa den här artikeln i vår mobilapp