Einführung
Sortieren von Daten bedeutet, sie in einer bestimmten Reihenfolge anzuordnen, oft in einer Array-ähnlichen Datenstruktur. Sie können verschiedene Bestellkriterien verwenden, z. B. das Sortieren von Zahlen vom kleinsten zum Größten oder umgekehrt oder das lexikografische Sortieren von Zeichenfolgen. Sie können sogar Ihre eigenen Kriterien definieren, und wir werden bis zum Ende dieses Artikels auf praktische Weise vorgehen.,
Wenn Sie daran interessiert sind, wie Sortierung funktioniert, behandeln wir verschiedene Algorithmen, von ineffizienten, aber intuitiven Lösungen bis hin zu effizienten Algorithmen, die tatsächlich in Java und anderen Sprachen implementiert sind.
Es gibt verschiedene Sortieralgorithmen, und sie sind nicht alle gleich effizient. Wir werden ihre Zeitkomplexität analysieren, um sie zu vergleichen und zu sehen, welche die beste Leistung erbringen.,
Die Liste der Algorithmen, die Sie hier lernen, ist keineswegs erschöpfend, aber wir haben einige der häufigsten und effizientesten zusammengestellt, um Ihnen den Einstieg zu erleichtern:
- Bubble Sort
- Insertion Sort
- Selection Sort
- Merge Sort
- Heapsort
- Quicksort
- Sorting in Java
Hinweis: Dieser Artikel wird nicht mit gleichzeitiger Sortierung zu tun haben, da es für Anfänger gedacht ist.
Blasensortierung
Erklärung
Blasensortierung tauscht benachbarte Elemente aus, wenn sie nicht in der gewünschten Reihenfolge sind., Dieser Vorgang wird vom Anfang des Arrays wiederholt, bis alle Elemente in Ordnung sind.
Wir wissen, dass alle Elemente in Ordnung sind, wenn wir es schaffen, die gesamte Iteration ohne Austausch durchzuführen – dann waren alle Elemente, die wir verglichen haben, in der gewünschten Reihenfolge mit ihren benachbarten Elementen und damit dem gesamten Array.
Hier sind die Schritte zum Sortieren eines Arrays von Zahlen vom kleinsten zum Größten:
-
4 2 1 5 3: Die ersten beiden Elemente sind in der falschen Reihenfolge, also tauschen wir sie aus.
-
2 4 1 5 3: Die zweiten beiden Elemente sind auch in der falschen Reihenfolge, also tauschen wir.,
-
2 1 4 5 3: Diese beiden sind in der richtigen Reihenfolge, 4 < 5, so dass wir Sie allein lassen.
-
2 1 4 5 3: ein Anderes tauschen.
-
2 1 4 3 5: Hier ist das resultierende array nach einer iteration.
Da während des ersten Durchgangs mindestens ein Swap aufgetreten ist (es gab tatsächlich drei), müssen wir das gesamte Array erneut durchlaufen und denselben Vorgang wiederholen.
Wenn Sie diesen Vorgang wiederholen, haben wir ein sortiertes Array, bis keine Swaps mehr vorgenommen werden.,
Der Grund, warum dieser Algorithmus als Blasensortierung bezeichnet wird, liegt darin, dass die Zahlen auf die „Oberfläche“ sprudeln.“Wenn Sie unser Beispiel erneut durchgehen und einer bestimmten Zahl folgen (4 ist ein großartiges Beispiel), werden Sie feststellen, dass es sich während des Vorgangs langsam nach rechts bewegt.
Alle Zahlen bewegen sich Stück für Stück von links nach rechts an ihre jeweiligen Stellen, wie Blasen, die langsam aus einem Gewässer aufsteigen.
Wenn Sie einen detaillierten, speziellen Artikel für Bubble Sort lesen möchten, haben wir Sie abgedeckt!,
Implementierung
Wir werden die Blasensortierung auf ähnliche Weise implementieren, wie wir sie in Worten festgelegt haben. Unsere Funktion tritt in eine while-Schleife ein, in der sie das gesamte Array nach Bedarf durchläuft.
Wir gehen davon aus, dass das Array sortiert ist, aber wenn wir uns beim Sortieren als falsch erwiesen haben (wenn ein Tausch stattfindet), durchlaufen wir eine andere Iteration. Die while-Schleife geht dann weiter, bis wir es schaffen, das gesamte Array ohne Austausch zu durchlaufen:
Wenn wir diesen Algorithmus verwenden, müssen wir vorsichtig sein, wie wir unsere Swap-Bedingung angeben.,
Wenn ich zum Beispiel a >= a hätte, hätte es zu einer Endlosschleife kommen können, da diese Beziehung für gleiche Elemente immer true und daher immer ausgetauscht würde.
Zeitkomplexität
Um die Zeitkomplexität der Blasensortierung herauszufinden, müssen wir uns das schlimmste Szenario ansehen. Wie oft müssen wir das gesamte Array maximal durchlaufen, bevor wir es sortiert haben?, Betrachten Sie das folgende Beispiel:
5 4 3 2 1In der ersten Iteration“ sprudelt “ 5 an die Oberfläche, aber der Rest der Elemente bleibt in absteigender Reihenfolge. Wir müssten eine Iteration für jedes Element außer 1 und dann eine weitere Iteration durchführen, um zu überprüfen, ob alles in Ordnung ist, also insgesamt 5 Iterationen.
Erweitern Sie dies auf ein beliebiges Array von n Elementen, und das bedeutet, dass Sie n Iterationen durchführen müssen., Wenn wir uns den Code ansehen, würde dies bedeuten, dass unsere while Schleife das Maximum von mal ausführen kann.
Jedes dieser -Zeiten durchlaufen wir das gesamte Array (for-Schleife im Code), was bedeutet, dass die Komplexität im schlimmsten Fall O(n^2).
Hinweis: Die Zeitkomplexität wäre immer O(n^2), wenn nicht die boolesche Prüfung sorted wäre, die den Algorithmus beendet, wenn es keine Swaps innerhalb der inneren Schleife gibt – was bedeutet, dass das Array sortiert ist.,
Insertion Sort
Erklärung
Die Idee hinter Insertion Sort teilt das Array in die sortierten und unsortierten Subarrays.
Der sortierte Teil hat am Anfang die Länge 1 und entspricht dem ersten (am weitesten links liegenden) Element im Array. Wir durchlaufen das Array und erweitern während jeder Iteration den sortierten Teil des Arrays um ein Element.
Beim Erweitern platzieren wir das neue Element an der richtigen Stelle innerhalb des sortierten Unterarrays. Dazu verschieben wir alle Elemente nach rechts, bis wir auf das erste Element stoßen, das wir nicht verschieben müssen.,
Wenn beispielsweise im folgenden Array der fett gedruckte Teil in aufsteigender Reihenfolge sortiert ist, geschieht Folgendes:
-
3 5 7 8 4 2 1 9 6: Wir nehmen 4 und denken daran, dass wir das einfügen müssen. Seit 8 > 4, verschieben wir.
-
3 5 7 x 8 2 1 9 6: Wobei der Wert von x nicht von entscheidender Bedeutung ist, da er sofort überschrieben wird (entweder durch 4, wenn es sein geeigneter Ort ist, oder durch 7, wenn wir verschieben). Seit 7 > 4, verschieben wir.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Nach diesem Prozess, werden die sortierten Teil wurde erweitert durch ein element, wir haben jetzt fünf statt vier Elemente. Jede Iteration tut dies und am Ende werden wir das ganze Array sortiert haben.
Wenn Sie einen ausführlichen, speziellen Artikel zur Einfügesortierung lesen möchten, haben wir Sie abgedeckt!,
Implementierung
Zeitkomplexität
Auch hier müssen wir uns das Worst-Case-Szenario für unseren Algorithmus ansehen, und es wird wieder das Beispiel sein, in dem das gesamte Array absteigend ist.
Dies liegt daran, dass wir in jeder Iteration die gesamte sortierte Liste um eins verschieben müssen, nämlich O(n). Wir müssen dies für jedes Element in jedem Array tun, was bedeutet, dass es durch O(n^2) begrenzt wird.
Auswahlsortierung
Erklärung
Auswahlsortierung teilt das Array auch in ein sortiertes und unsortiertes Subarray., Dieses Mal wird das sortierte Subarray jedoch gebildet, indem das minimale Element des unsortierten Subarray am Ende des sortierten Arrays eingefügt wird, indem Folgendes ausgetauscht wird:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 3 4 5
-
1 2 3 4 5
In jeder Iteration nehmen wir an, dass das erste unsortierte Element das Minimum ist, und durchlaufen den Rest, um festzustellen, ob es ein kleineres Element gibt.,
Sobald wir das aktuelle Minimum des unsortierten Teils des Arrays gefunden haben, tauschen wir es mit dem ersten Element aus und betrachten es als Teil des sortierten Arrays:
Zeitkomplexität
Das Minimum ist O(n) für die Länge des Arrays, da wir alle Elemente überprüfen müssen. Wir müssen das Minimum für jedes Element des Arrays finden, wodurch der gesamte Prozess durch O(n^2) begrenzt wird.,
Merge Sort
Erklärung
Merge Sort verwendet Rekursion, um das Problem der Sortierung effizienter zu lösen als zuvor vorgestellte Algorithmen und insbesondere einen Divide-and-Conquer-Ansatz.
Mit diesen beiden Konzepten teilen wir das gesamte Array in zwei Unterarrays auf und sortieren dann:
- Sortieren Sie die linke Hälfte des Arrays (rekursiv)
- Sortieren Sie die rechte Hälfte des Arrays (rekursiv)
- Führen Sie die Lösungen zusammen
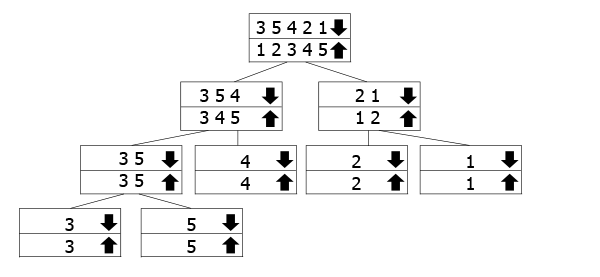
Dieser Baum soll darstellen, wie der rekursive anrufe arbeiten., Die mit dem Abwärtspfeil markierten Arrays sind diejenigen, für die wir die Funktion aufrufen, während wir die Aufwärtspfeil-Arrays wieder nach oben zusammenführen. Sie folgen also dem Abwärtspfeil zum unteren Rand des Baumes und gehen dann wieder nach oben und zusammenführen.
In unserem Beispiel haben wir das Array 3 5 3 2 1, also teilen wir es in 3 5 4 und 2 1. Um sie zu sortieren, teilen wir sie weiter in ihre Komponenten auf. Sobald wir den Boden erreicht haben, fangen wir an, sie zu verschmelzen und zu sortieren.,
Wenn Sie einen ausführlichen, speziellen Artikel für Merge Sort lesen möchten, haben wir Sie abgedeckt!
Implementierung
Die Kernfunktion funktioniert so ziemlich wie in der Erklärung beschrieben. Wir übergeben nur die Indizes left und right, die Indizes des am weitesten links und rechts liegenden Elements des Subarrays sind, das wir sortieren möchten. Anfangs sollten diese je nach Implementierung 0 und array.length-1 sein.,
Die Basis unserer Rekursion stellt sicher, dass wir beenden, wenn wir fertig sind, oder wenn right und left einander treffen. Wir finden einen Mittelpunkt mid und sortieren Subarrays links und rechts davon rekursiv und verschmelzen letztendlich unsere Lösungen.
Wenn Sie sich an unsere Baumgrafik erinnern, fragen Sie sich vielleicht, warum wir nicht zwei neue kleinere Arrays erstellen und sie stattdessen weitergeben. Dies liegt daran, dass dies bei wirklich langen Arrays zu einem enormen Speicherverbrauch für etwas führen würde, das im Wesentlichen unnötig ist.,
Die Zusammenführungssortierung funktioniert aufgrund des Zusammenführungsschritts bereits nicht an Ort und Stelle, und dies würde nur dazu dienen, die Speichereffizienz zu verschlechtern. Die Logik unseres Rekursionsbaums bleibt ansonsten gleich, wir müssen jedoch nur den Indizes folgen, die wir verwenden:
Um die sortierten Unterarrays zu einem zusammenzuführen, müssen wir die Länge jedes einzelnen berechnen und temporäre Arrays erstellen, in die wir sie kopieren können, damit wir unser Hauptarray frei ändern können.
Nach dem Kopieren gehen wir das resultierende Array durch und weisen ihm das aktuelle Minimum zu., Da unsere Subarrays sortiert sind, haben wir nur das kleinere der beiden Elemente ausgewählt, die bisher nicht ausgewählt wurden, und den Iterator für dieses Subarray nach vorne verschoben:
Zeitkomplexität
Wenn wir die Komplexität rekursiver Algorithmen ableiten möchten, müssen wir ein wenig mathy bekommen.
Der Hauptsatz wird verwendet, um die Zeitkomplexität rekursiver Algorithmen herauszufinden. Für nicht rekursive Algorithmen könnten wir normalerweise die genaue Zeitkomplexität als eine Art Gleichung schreiben, und dann verwenden wir die Big-O-Notation, um sie in Klassen ähnlich verhaltender Algorithmen zu sortieren.,
Das problem mit rekursiven algorithmen ist, dass dieselbe Gleichung würde wie folgt Aussehen:
$$
T(n) = aT(\frac{n}{b}) + cn^k
$$
Die Gleichung selbst ist rekursiv! In dieser Gleichung gibt a an, wie oft wir die Rekursion aufrufen, und b teilt uns mit, in wie viele Teile unser Problem unterteilt ist. In diesem Fall scheint dies eine unwichtige Unterscheidung zu sein, da sie für Mergesort gleich sind, für einige Probleme jedoch möglicherweise nicht.,
Der Rest der Gleichung ist die Komplexität der Verschmelzung all dieser Lösungen zu einer am Ende., Das Master-Theorem löst diese Gleichung für uns:
$$
T(n) = \Bigg\{
\begin{matrix}
O(n^{log_ba}), &>b^k \\ O(n^klog n), & a = b^k \\ O(n^k), & < b^k
\end{matrix}
$$
Wenn T(n) ist die Laufzeit von Algorithmus beim Sortieren eines Arrays der Länge n -, Merge-Sort zweimal ausführen würde für arrays, die die Hälfte der Länge des ursprünglichen Arrays.,
Also, wenn wir a=2, b=2. Der merge-Schritt O(n) Speicher, also k=1. Dies bedeutet, dass die Gleichung für die Zusammenführungssortierung wie folgt aussehen würde:
$$
T (n) = 2T(\frac{n}{2})+cn
$$
Wenn wir den Hauptsatz anwenden, werden wir sehen, dass unser Fall derjenige ist, bei dem a=b^k, weil wir 2=2^1. Das bedeutet, dass unsere Komplexität O (nlog n) ist. Dies ist eine äußerst gute Zeitkomplexität für einen Sortieralgorithmus, da nachgewiesen wurde, dass ein Array nicht schneller als O(nlog n) sortiert werden kann.,
Während die von uns präsentierte Version speicherintensiv ist, gibt es komplexere Versionen von Merge Sort, die nur O(1) Speicherplatz beanspruchen.
Darüber hinaus ist der Algorithmus extrem einfach zu parallelisieren, da rekursive Aufrufe von einem Knoten völlig unabhängig von separaten Zweigen ausgeführt werden können. Wir werden uns zwar nicht mit dem Wie und Warum befassen, da dies über den Rahmen dieses Artikels hinausgeht, aber es lohnt sich, die Vorteile der Verwendung dieses speziellen Algorithmus zu berücksichtigen.,
Heapsort
Erklärung
Um richtig zu verstehen, warum Heapsort funktioniert, müssen Sie zuerst die Struktur verstehen, auf der es basiert – den Heap. Wir werden speziell in Bezug auf einen binären Heap sprechen, aber Sie können das meiste auch auf andere Heap-Strukturen verallgemeinern.
Ein Heap ist ein Baum, der die Heap-Eigenschaft erfüllt, dh für jeden Knoten befinden sich alle untergeordneten Elemente in einer bestimmten Beziehung dazu. Außerdem muss ein Heap fast vollständig sein., Ein fast vollständiger Binärbaum der Tiefe d hat einen Teilbaum der Tiefe d-1 mit demselben vollständigen Stamm und in dem jeder Knoten mit einem linken Nachkommen einen vollständigen linken Teilbaum hat. Mit anderen Worten, wenn wir einen Knoten hinzufügen, wählen wir immer die Position ganz links in der höchsten unvollständigen Ebene.
Wenn der Heap ein Max-Heap ist, sind alle untergeordneten Elemente kleiner als das übergeordnete Element, und wenn es sich um einen Min-Heap handelt, sind alle größer.,
Mit anderen Worten, wenn Sie den Baum hinuntergehen, gelangen Sie zu immer kleineren Zahlen (min-Heap) oder immer größeren Zahlen (max-Heap). Hier ist ein Beispiel für einen Max-Heap:
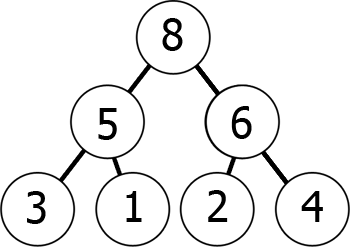
Wir können diesen Max-Heap im Speicher wie folgt als Array darstellen:
8 5 6 3 1 2 4Sie können sich vorstellen, dass es von der Diagrammebene nach Ebene von links nach rechts gelesen wird., Was wir dadurch erreicht haben, ist, dass, wenn wir das kth Element im Array nehmen, die Positionen seiner Kinder 2*k+1 und 2*k+2 (vorausgesetzt, die Indizierung beginnt bei 0). Sie können dies selbst überprüfen.
Umgekehrt ist für das Element kth die Position des Elternteils immer (k-1)/2.
Wenn Sie dies wissen, können Sie jedes Array einfach „max-heapify“. Überprüfen Sie für jedes Element, ob eines seiner untergeordneten Elemente kleiner ist., Wenn dies der Fall ist, tauschen Sie einen von ihnen mit dem übergeordneten Element aus und wiederholen Sie diesen Schritt rekursiv mit dem übergeordneten Element (da das neue große Element möglicherweise immer noch größer als das andere untergeordnete Element ist).
Blätter haben keine Kinder, also sind sie trivial max-Haufen ihrer eigenen:
-
6 1 8 3 5 2 4: Beide Kinder sind kleiner als die Eltern, also bleibt alles gleich.
-
6 1 8 3 5 2 4: 5 und > 1, wir tauschen. Wir heapify rekursiv für 5 jetzt.
-
6 5 8 3 1 2 4: Beide Kinder sind kleiner, so passiert nichts.,
-
6 5 8 3 1 2 4: Da 8 > 6, wir tauschen.
-
8 5 6 3 1 2 4: Wir haben die Haufen oben im Bild!
Sobald wir gelernt haben, ein Array zu heapifizieren, ist der Rest ziemlich einfach. Wir tauschen die Wurzel des Heaps mit dem Ende des Arrays aus und verkürzen das Array um eins.,
Wir häufen das verkürzte Array erneut und wiederholen den Vorgang:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: getauscht
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: getauscht
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: getauscht
Und so weiter, ich bin sicher, Sie können das Muster auftauchen sehen.
Implementierung
Zeitkomplexität
Wenn wir uns die heapify() Funktion ansehen, scheint alles in O(1) zu sein, aber dann gibt es diesen lästigen rekursiven Aufruf.,
Wie oft wird das im schlimmsten Fall aufgerufen? Nun, im schlimmsten Fall wird es sich bis an die Spitze des Heaps ausbreiten. Dies geschieht, indem zum übergeordneten Element jedes Knotens gesprungen wird, also um die Position i/2. das bedeutet, dass es im schlimmsten Fall log n Sprünge macht, bevor es die Spitze erreicht, also ist die Komplexität O(log n).
Da heapSort() aufgrund von For-Schleifen, die das gesamte Array durchlaufen, eindeutig O(n) ist, würde dies die Gesamtkomplexität von Heapsort O(nlog n).,
Heapsort ist eine In-Place-Sortierung, was bedeutet, dass O(1) zusätzlichen Platz benötigt, im Gegensatz zur Merge-Sortierung, aber es hat auch einige Nachteile, wie z. B. schwierig zu parallelisieren.
Quicksort
Erklärung
Quicksort ist ein weiterer Divide and Conquer-Algorithmus. Es wählt ein Element eines Arrays als Drehpunkt aus und sortiert alle anderen Elemente um es herum, z. B. kleinere Elemente nach links und größere nach rechts.
Dies garantiert, dass sich der Pivot nach dem Vorgang an der richtigen Stelle befindet., Dann macht der Algorithmus rekursiv dasselbe für den linken und rechten Teil des Arrays.
Implementierung
Zeitkomplexität
Die Zeitkomplexität von Quicksort kann mit der folgenden Gleichung ausgedrückt werden:
$$
T(n) = T(k) + T(n-k-1) + O(n)
$$
Das Worst-Case-Szenario ist, wenn das größte oder kleinste Element immer für Pivot ausgewählt wird. Die Gleichung würde dann wie folgt Aussehen:
$$
T(n) = T(0) + T(n-1) + O(n) = T(n-1) + O(n)
$$
Diese stellt sich heraus zu sein, O(n^2).,
Dies mag schlecht klingen, da wir bereits mehrere Algorithmen gelernt haben, die im schlimmsten Fall in O(nlog n) – Zeit ausgeführt werden, aber Quicksort ist tatsächlich sehr weit verbreitet.
Dies liegt daran, dass es eine wirklich gute durchschnittliche Laufzeit hat, die ebenfalls durch O(nlog n) begrenzt ist und für einen großen Teil der möglichen Eingaben sehr effizient ist.
Einer der Gründe, warum die Zusammenführung der Sortierung bevorzugt wird, ist, dass kein zusätzlicher Speicherplatz benötigt wird, die gesamte Sortierung an Ort und Stelle erfolgt und keine teuren Zuweisungs-und Zuweisungsaufrufe erfolgen.,
Leistungsvergleich
Davon abgesehen ist es oft nützlich, all diese Algorithmen einige Male auf Ihrem Computer auszuführen, um eine Vorstellung davon zu erhalten, wie sie funktionieren.
Sie werden mit verschiedenen Sammlungen, die natürlich sortiert werden, unterschiedlich funktionieren, aber selbst in diesem Sinne sollten Sie einige Trends bemerken können.
Lassen Sie uns alle Implementierungen einzeln auf einer Kopie eines gemischten Arrays von 10.000 ganzen Zahlen ausführen:
Wir können offensichtlich sehen, dass die Blasensortierung die schlechteste ist, wenn es um Leistung geht., Vermeiden Sie es, es in der Produktion zu verwenden, wenn Sie nicht garantieren können, dass es nur kleine Sammlungen verarbeitet und die Anwendung nicht zum Stillstand bringt.
HeapSort und QuickSort sind die leistungsstärksten. Obwohl sie ähnliche Ergebnisse ausgeben, ist QuickSort tendenziell etwas besser und konsistenter – was sich herausstellt.
Sortierung in Java
Vergleichbare Schnittstelle
Wenn Sie eigene Typen haben, kann es umständlich werden, einen separaten Sortieralgorithmus für jeden zu implementieren. Aus diesem Grund bietet Java eine Schnittstelle, mit der Sie Collections.sort() für Ihre eigenen Klassen verwenden können.,
Dazu muss Ihre Klasse die Comparable<T> – Schnittstelle implementieren, wobei T Ihr Typ ist und eine Methode namens .compareTo()überschreiben.
Diese Methode gibt eine negative Ganzzahl zurück, wenn this kleiner als das Argumentelement ist, 0, wenn sie gleich sind, und eine positive Ganzzahl, wenn this größer ist.
In unserem Beispiel haben wir eine Klasse Student erstellt, und jeder Schüler wird durch eine id und ein Jahr identifiziert Sie begannen ihr Studium.,
Wir möchten sie hauptsächlich nach Generationen sortieren, aber auch sekundär nach IDs:
Und so verwenden Sie sie in einer Anwendung:
Ausgabe:
Komparatorschnittstelle
Wir möchten unsere Objekte möglicherweise für einen bestimmten Zweck auf unorthodoxe Weise sortieren, aber wir möchten dies nicht als Standardverhalten unserer Klasse implementieren, oder wir möchten es in einer sortieren Sie eine Sammlung eines integrierten Typs auf nicht standardmäßige Weise.
Dazu können wir die Comparator Schnittstelle verwenden., Nehmen wir zum Beispiel unsere Student Klasse und sortieren nur nach ID:
Wenn wir den Sortieraufruf in main durch den folgenden ersetzen:
Arrays.sort(a, new SortByID());Ausgabe:
Wie alles funktioniert
Collection.sort() ruft die zugrunde liegende Arrays.sort() – Methode auf, während die Sortierung selbst die Einfügesortierung für Arrays verwendet, die kürzer als 47 sind, und Quicksort für den Rest.,
Es basiert auf einer spezifischen Zwei-Pivot-Implementierung von Quicksort, die sicherstellt, dass die meisten typischen Ursachen für die Verschlechterung der quadratischen Leistung gemäß der JDK10-Dokumentation vermieden werden.
Fazit
Das Sortieren ist bei Datensätzen eine sehr häufige Operation, sei es, um sie weiter zu analysieren, die Suche zu beschleunigen, indem effizientere Algorithmen verwendet werden, die sich auf die zu sortierenden Daten stützen, Daten filtern usw.
Die Sortierung wird von vielen Sprachen unterstützt und die Schnittstellen verdecken oft, was tatsächlich mit dem Programmierer passiert., Diese Abstraktion ist zwar willkommen und für eine effektive Arbeit notwendig, kann jedoch manchmal für die Effizienz tödlich sein, und es ist gut zu wissen, wie verschiedene Algorithmen implementiert und mit ihren Vor-und Nachteilen vertraut gemacht werden und wie leicht auf integrierte Implementierungen zugegriffen werden kann.