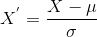Introducere în Funcția de Scalare
recent am fost de lucru cu un set de date care au mai multe caracteristici care acoperă diferite grade de magnitudine, gama, și unități. Acesta este un obstacol semnificativ, deoarece câțiva algoritmi de învățare automată sunt foarte sensibili la aceste caracteristici.sunt sigur că majoritatea dintre voi trebuie să fi confruntat cu această problemă în proiectele sau călătoria dvs. de învățare., De exemplu, o caracteristică este în întregime în kilograme, în timp ce cealaltă este în grame, alta este litri și așa mai departe. Cum putem folosi aceste caracteristici atunci când variază atât de mult în ceea ce privește ceea ce prezintă?
aici am apelat la conceptul de scalare a caracteristicilor. Este o parte crucială a etapei de preprocesare a datelor, dar am văzut o mulțime de începători care o ignoră (în detrimentul modelului lor de învățare automată).,

Aici e lucru curios despre funcția de scalare – imbunatateste (în mod semnificativ) performanța unor algoritmi de învățare mașină și nu funcționează la toate pentru alții. Care ar putea fi motivul din spatele acestei ciudățenii?
De asemenea, care este diferența dintre normalizare și standardizare? Acestea sunt două dintre cele mai frecvent utilizate tehnici de scalare a caracteristicilor în învățarea automată, dar există un nivel de ambiguitate în înțelegerea lor. Când trebuie să folosiți ce tehnică?,
voi răspunde la aceste întrebări și mai mult în acest articol pe scalarea caracteristică. De asemenea, vom implementa scalarea funcțiilor în Python pentru a vă oferi o înțelegere practică a modului în care funcționează pentru diferiți algoritmi de învățare automată.notă: presupun că sunteți familiarizat cu algoritmii Python și core machine learning., Dacă sunteți nou la acest lucru, vă recomandăm merge prin partea de jos cursuri:
- Python pentru Știință de Date
- Toate gratuit Machine Learning Cursuri de Analiză Vidhya
- Aplicat în Masina de Învățare
Cuprins
- de Ce Să utilizăm Funcția de Scalare?
- ce este normalizarea?
- ce este standardizarea?
- Marea întrebare-normalizați sau standardizați?,
- de punere în Aplicare Funcția de Scalare în Python
- Normalizarea folosind Sklearn
- Standardizare folosind Sklearn
- Aplicarea Funcția de Scalare pentru Algoritmi de Învățare Mașină
- K-cel mai Apropiat Vecini (KNN)
- Suport Vector de Frecvență
- Arbore de Decizie
de Ce Să utilizăm Funcția de Scalare?
prima întrebare pe care trebuie să o abordăm – de ce trebuie să scalăm variabilele din setul nostru de date? Unii algoritmi de învățare automată sunt sensibili la scalarea caracteristicilor, în timp ce alții sunt practic invarianți., Permiteți-mi să explic mai detaliat.
algoritmi bazați pe descendența gradientului
algoritmi de învățare automată precum regresia liniară, regresia logistică, rețeaua neuronală etc. utilizarea gradient descent ca tehnică de optimizare necesită scalarea datelor. Aruncați o privire la formula pentru coborârea gradientului de mai jos:

prezența valorii caracteristicii X în formulă va afecta dimensiunea pasului coborârii gradientului. Diferența dintre gamele de caracteristici va determina dimensiuni diferite de pas pentru fiecare caracteristică., Pentru a ne asigura că coborârea gradientului se deplasează lin spre minimele și că pașii pentru coborârea gradientului sunt actualizați în același ritm pentru toate caracteristicile, scalăm datele înainte de a le alimenta modelului.
Având caracteristici pe o scară similară poate ajuta gradient de coborâre converge mai repede spre minima.
algoritmi bazate pe distanță
algoritmi de distanță, cum ar fi KNN, K-înseamnă, și SVM sunt cele mai afectate de gama de caracteristici., Acest lucru se datorează faptului că în spatele scenei folosesc distanțe între punctele de date pentru a determina similitudinea lor.
De exemplu, să presupunem că avem de date care conțin liceu CGPA zeci de studenți (de la 0 la 5) și viitorul lor venituri (în mii de Rupii):

Deoarece ambele caracteristici au scări diferite, acolo este o șansă că mai mare weightage este dat de caracteristici cu mărime mai mare. Acest lucru va afecta performanța algoritmului de învățare automată și, evident, nu dorim ca algoritmul nostru să fie înclinat către o caracteristică.,
prin Urmare, vom scara noastra de date înainte de a angaja o distanță pe bază de algoritm, astfel încât toate caracteristicile contribuie în mod egal la rezultat.,snt a și B, și între B și C, înainte și după scalarea așa cum se arată mai jos:
- Distanța AB înainte de scalare =>

- Distanta BC înainte de scalare =>

- Distanța AB după scalare =>

- Distanta Î. hr., după scalare =>

Scalare a adus ambele caracteristici în imagine și distanțele sunt acum mai comparabile decât au fost înainte de a aplica scalarea.,
algoritmi pe bază de arbori
algoritmi pe bază de arbori, pe de altă parte, sunt destul de insensibili la scara caracteristicilor. Gândiți-vă, un arbore de decizie împarte doar un nod bazat pe o singură caracteristică. Arborele de decizie împarte un nod pe o caracteristică care crește omogenitatea nodului. Această împărțire pe o caracteristică nu este influențată de alte caracteristici.deci, practic nu există niciun efect al caracteristicilor rămase asupra împărțirii. Aceasta este ceea ce le face invariante la scara caracteristicilor!
ce este normalizarea?,
normalizare este o tehnică de scalare în care valorile sunt deplasate și rescalate, astfel încât acestea ajung variind între 0 și 1. Este, de asemenea, cunoscut sub numele de scalare Min-Max.
Iată formula pentru normalizare:
aici, Xmax și Xmin sunt valorile maxime și, respectiv, minime ale caracteristicii.,
- atunci Când valoarea lui X este valoarea minimă în coloana, numărătorul va fi 0, și, prin urmare, X este 0
- Pe de altă parte, atunci când valoarea lui X este valoarea maximă în coloană, numărătorul este egal cu numitorul și, astfel, valoarea lui X este 1
- Dacă valoarea lui X este cuprinsă între valoarea minimă și valoarea maximă, atunci valoarea lui X este între 0 și 1
Ce este Standardizare?
standardizarea este o altă tehnică de scalare în care valorile sunt centrate în jurul mediei cu o abatere standard a unității., Aceasta înseamnă că media atributului devine zero, iar distribuția rezultată are o abatere standard de unitate.
Aici este formula pentru standardizare:
este valoarea medie a caracteristicii valorilor și
este abaterea standard a caracteristicii valori. Rețineți că, în acest caz, valorile nu sunt limitate la un anumit interval.acum, marea întrebare în mintea ta trebuie să fie când ar trebui să folosim normalizarea și când ar trebui să folosim standardizarea? Să aflăm!,
Marea întrebare-normalizați sau standardizați?
normalizare vs. standardizare este o întrebare eternă în rândul noilor veniți de învățare automată. Permiteți-mi să detaliez răspunsul din această secțiune.normalizarea este bine de utilizat atunci când știți că distribuția datelor dvs. nu urmează o distribuție Gaussiană. Acest lucru poate fi util în algoritmi care nu presupun nicio distribuție a datelor, cum ar fi K-cei mai apropiați vecini și rețele neuronale.
standardizarea, pe de altă parte, poate fi utilă în cazurile în care datele urmează o distribuție Gaussiană., Totuși, acest lucru nu trebuie să fie neapărat adevărat. De asemenea, spre deosebire de normalizare, standardizarea nu are un interval de delimitare. Deci, chiar dacă aveți valori aberante în datele dvs., acestea nu vor fi afectate de standardizare.cu toate acestea, la sfârșitul zilei, alegerea utilizării normalizării sau standardizării va depinde de problema dvs. și de algoritmul de învățare automată pe care îl utilizați. Nu există nici o regulă greu și rapid să-ți spun când să normalizeze sau să standardizeze datele., Puteți începe întotdeauna prin adaptarea modelului la date brute, normalizate și standardizate și puteți compara performanța pentru cele mai bune rezultate. este o practică bună să se potrivească scaler pe datele de formare și apoi să-l utilizați pentru a transforma datele de testare. Acest lucru ar evita orice scurgere de date în timpul procesului de testare a modelului. De asemenea, scalarea valorilor țintă nu este, în general, necesară.
implementarea scalării caracteristicilor în Python
acum vine partea distractivă-punerea în practică a ceea ce am învățat., Voi aplica scalarea caracteristicilor la câțiva algoritmi de învățare a mașinilor pe setul de date Big Mart pe care l-am luat pe platforma DataHack.
voi sări peste pașii de preprocesare, deoarece acestea sunt în afara domeniului de aplicare al acestui tutorial. Dar le puteți găsi explicate în acest articol. Acești pași vă va permite să ajungă la partea de sus 20 percentila pe clasament hackathon, astfel încât merită verificat!deci, Să împărțim mai întâi datele noastre în seturi de instruire și testare:
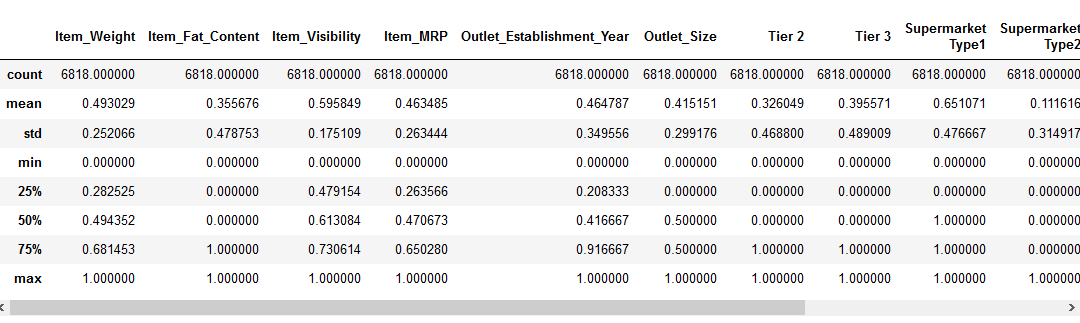
înainte de a trece la partea de scalare a caracteristicilor, să aruncăm o privire asupra detaliilor despre datele noastre folosind pd.,descrie metoda ():
putem vedea că există o mare diferență în intervalul de valori prezente în nostru numerice caracteristici: Item_Visibility, Item_Weight, Item_MRP, și Outlet_Establishment_Year. Să încercăm să remediem acest lucru folosind scalarea funcțiilor!
Notă: veți observa valori negative în caracteristica Item_Visibility, deoarece am luat log-transformare pentru a face față cu skewness în caracteristica.
normalizare folosind sklearn
pentru a vă normaliza datele, trebuie să importați MinMaxScalar din biblioteca sklearn și să îl aplicați în setul nostru de date., Deci, hai să facem asta!
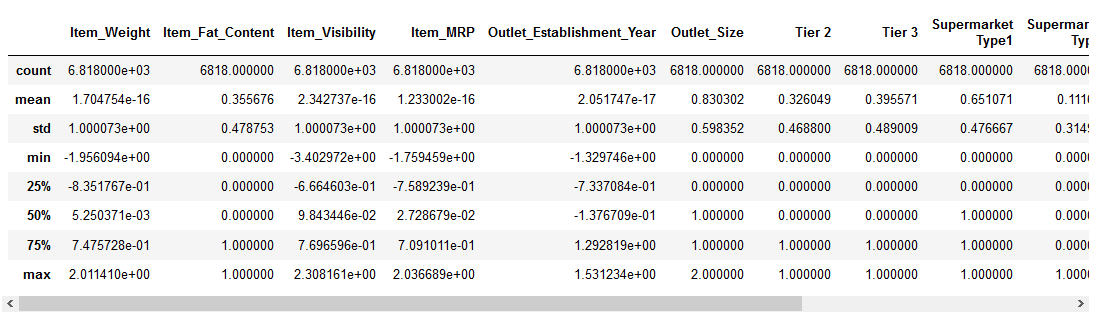
Să vedem cât de normalizare a afectat setul nostru de date:
Toate caracteristicile au acum o valoare minimă de 0 și o valoare maximă de 1. Perfect!
încercați codul de mai sus în fereastra de codare live de mai jos!!apoi, să încercăm să ne standardizăm datele.
Standardizare folosind sklearn
Pentru a standardiza datele dumneavoastră, aveți nevoie pentru a importa StandardScalar din sklearn bibliotecă și se aplică la setul nostru de date., Iată cum puteți face acest lucru:
ați fi observat că am aplicat standardizarea doar coloanelor mele numerice și nu celeilalte caracteristici codificate la cald. Standardizarea caracteristicilor codificate la cald ar însemna atribuirea unei distribuții caracteristicilor categorice. Nu vrei să faci asta!dar de ce nu am făcut același lucru în timp ce normalizez datele? Deoarece caracteristicile codificate la cald sunt deja în intervalul cuprins între 0 și 1. Deci, normalizarea nu le-ar afecta valoarea.,
corect, să aruncăm o privire la modul în care standardizarea a transformat datele noastre:
caracteristicile numerice sunt acum centrate pe media cu o abatere standard a unității. Minunat!
comparând datele nescalate, normalizate și standardizate
este întotdeauna minunat să vizualizați datele dvs. pentru a înțelege distribuția prezentă. Putem vedea comparația dintre datele noastre necalificate și scalate folosind boxplots.puteți afla mai multe despre vizualizarea datelor aici.,

puteți observa cum scalarea caracteristicilor aduce totul în perspectivă. Caracteristicile sunt acum mai comparabile și vor avea un efect similar asupra modelelor de învățare.
aplicarea scalării algoritmilor de învățare automată
acum este timpul să instruim niște algoritmi de învățare automată pe datele noastre pentru a compara efectele diferitelor tehnici de scalare asupra performanței algoritmului. Vreau să văd efectul scalării asupra a trei algoritmi în special: K-vecinii cei mai apropiați, Regresorul vectorului de suport și arborele de decizie.,așa cum am văzut mai înainte, KNN este un algoritm bazat pe distanță, care este afectat de gama de caracteristici. Să vedem cum funcționează pe datele noastre, înainte și după scalare:
puteți vedea că scalarea caracteristicilor a redus scorul RMSE al modelului nostru KNN. Mai exact, datele normalizate efectuează un pic mai bine decât datele standardizate.
notă: eu sunt de măsurare RMSE aici, deoarece această competiție evaluează RMSE.
suport Vector Regresor
SVR este un alt algoritm bazat pe distanță., Deci, să vedem dacă funcționează mai bine cu normalizarea sau standardizarea:
putem vedea că scalarea caracteristicilor reduce scorul RMSE. Și datele standardizate au avut performanțe mai bune decât datele normalizate. De ce crezi că este cazul?documentația sklearn afirmă că SVM, cu kernel RBF, presupune că toate caracteristicile sunt centrate în jurul valorii de zero și varianța este de aceeași ordine. Acest lucru se datorează faptului că o caracteristică cu o variație mai mare decât cea a altora împiedică Estimatorul să învețe din toate caracteristicile., Grozav!
Arborele decizional
știm deja că un arbore decizional este invariant pentru scalarea caracteristicilor. Dar am vrut să arăt un exemplu practic al modului în care funcționează datele:
puteți vedea că scorul RMSE nu sa mutat cu un centimetru pe scalarea caracteristicilor. Deci, fiți siguri atunci când utilizați algoritmi pe bază de copac pe datele dvs.!,
End Note
Acest tutorial acoperite relevanța folosind funcția de scalare pe date și cât de normalizare și standardizare au diferite efecte pe lucru de algoritmi de învățare mașină
Țineți minte că nu există nici un răspuns corect atunci când pentru a utiliza normalizarea peste standardizare și vice-versa. Totul depinde de datele dvs. și de algoritmul pe care îl utilizați.
ca un pas următor, vă încurajez să încercați scalarea caracteristicilor cu alți algoritmi și să vă dați seama ce funcționează cel mai bine – normalizare sau standardizare?, Vă recomandăm să utilizați datele de vânzări BigMart în acest scop pentru a menține continuitatea cu acest articol. Și nu uitați să împărtășiți informațiile dvs. în secțiunea de comentarii de mai jos!
puteți citi acest articol și pe aplicația noastră mobilă