Introducere
Sortarea datelor înseamnă aranjarea acestora într-o anumită ordine, adesea într-o structură de date asemănătoare array-ului. Puteți utiliza diferite criterii de comandă, cele comune fiind sortarea numerelor de la cel mai mic la cel mai mare sau invers, sau sortarea șirurilor lexicografic. Puteți defini chiar propriile criterii, și vom merge în moduri practice de a face acest lucru până la sfârșitul acestui articol.,dacă sunteți interesat de modul în care funcționează sortarea, vom acoperi diverși algoritmi, de la soluții ineficiente, dar intuitive, la algoritmi eficienți care sunt de fapt implementați în Java și în alte limbi.există diverși algoritmi de sortare și nu toți sunt la fel de eficienți. Vom analiza complexitatea lor de timp pentru a le compara și a vedea care dintre ele funcționează cel mai bine.,
lista de algoritmi veți învăța aici nu este exhaustivă, dar am compilat unele dintre cele mai comune și cele mai eficiente pentru a vă ajuta să începeți:
- Bubble Sort
- un Fel de introducere
- un Fel de Selecție
- un Fel de Îmbinare
- Heapsort
- Quicksort
- Sortare în Java
Notă: Acest articol nu va fi de-a face concomitent cu sortarea, deoarece este menit pentru incepatori.
Bubble Sort
explicație
Bubble sort funcționează prin schimbarea elementelor adiacente, dacă acestea nu sunt în ordinea dorită., Acest proces se repetă de la începutul matricei până când toate elementele sunt în ordine.
știm că toate elementele sunt în ordine atunci când reușim să facem întreaga iterație fără a schimba deloc-atunci toate elementele pe care le-am comparat au fost în ordinea dorită cu elementele adiacente și, prin extensie, întreaga matrice.
iată pașii pentru sortarea unui tablou de numere de la cel mai mic la cel mai mare:
-
4 2 1 5 3: primele două elemente sunt în ordine greșită, așa că le schimbăm.
-
2 4 1 5 3: și cele două elemente sunt în ordine greșită, așa că schimbăm.,2 1 4 5 3: Aceste două sunt în ordinea corectă, 4<5, așa că le lăsăm în pace.
-
2 1 4 5 3: Un alt schimb.
-
2 1 4 3 5: Iată matricea rezultată după o iterație.deoarece cel puțin un swap a avut loc în timpul primei treceri (au existat de fapt trei), trebuie să parcurgem din nou întreaga matrice și să repetăm același proces.prin repetarea acestui proces, până când nu se mai fac swap-uri, vom avea o matrice sortată.,
motivul pentru care acest algoritm se numește sortare cu bule se datorează faptului că numerele de tip ” bubble up „la” suprafață.”Dacă parcurgeți din nou exemplul nostru, urmând un anumit număr (4 este un exemplu excelent), îl veți vedea mișcându-se încet spre dreapta în timpul procesului.toate numerele se deplasează în locurile respective câte puțin, de la stânga la dreapta, ca niște bule care se ridică încet dintr-un corp de apă.
dacă doriți să citiți un articol detaliat, dedicat pentru sortare cu bule, ne-am luat te-a acoperit!,
implementare
vom implementa sortarea bulelor într-un mod similar pe care l-am prezentat în cuvinte. Funcția noastră intră într-o buclă în timp ce trece prin întreaga matrice schimbând după cum este necesar.
presupunem că matricea este sortată, dar dacă s-a dovedit că greșim în timpul sortării (dacă se întâmplă un swap), trecem printr-o altă iterație. Bucla while continuă apoi până când reușim să trecem prin întreaga matrice fără a schimba:
când folosim acest algoritm, trebuie să fim atenți la modul în care ne declarăm starea de swap.,
De exemplu, dacă am folosit
a >= as-ar putea s-au încheiat cu o buclă infinită, deoarece pentru elemente egale această relație ar fi mereutrue, și, prin urmare, mereu le schimba.pentru a afla complexitatea timpului de sortare cu bule, trebuie să ne uităm la cel mai rău scenariu posibil. Care este numărul maxim de ori avem nevoie pentru a trece prin întreaga matrice înainte de a le-am sortate?, Luați în considerare următorul exemplu:5 4 3 2 1în prima iterație, 5 va „bubble până la suprafață”, dar restul elementelor vor rămâne în ordine descrescătoare. Ar trebui să facem o iterație pentru fiecare element, cu excepția 1, și apoi o altă iterație pentru a verifica dacă totul este în ordine, deci un total de iterații 5.
se Extindă acest lucru pentru orice matrice de
nelemente, și asta înseamnă că trebuie să faciniterații., Privind Codul, asta ar însemna căwhilebucla poate rula maximulnori.Fiecare dintre aceste
nori suntem iterarea prin toată gama (pentru buclă în cod), în sensul cel mai rău caz, complexitatea ar fi O(n^2).Notă: complexitatea timp va fi întotdeauna O(n^2) dacă n
sortedboolean verificare, care se termină algoritmul dacă nu sunt swap-uri în bucla interioara – ceea ce înseamnă că vectorul este sortat.,Insertion Sort
explicație
ideea din spatele Insertion Sort împarte matricea în subarrays sortate și nesortate.
partea sortată are lungimea 1 la început și corespunde primului element (cel mai din stânga) din matrice. Iterăm prin matrice și în timpul fiecărei iterații, extindem porțiunea sortată a matricei cu un element.
la extindere, plasăm noul element în locul său corespunzător în subarray sortate. Facem acest lucru mutând toate elementele spre dreapta până când întâlnim primul element pe care nu trebuie să-l schimbăm.,
de exemplu, dacă în următoarea matrice partea boldată este sortată într-o ordine crescătoare, se întâmplă următoarele:
-
3 5 7 8 4 2 1 9 6: luăm 4 și ne amintim că asta trebuie să inserăm. Din moment ce 8 > 4, schimbăm.3 5 7 x 8 2 1 9 6: unde valoarea lui x nu are o importanță crucială, deoarece va fi suprascrisă imediat (fie cu 4 dacă este locul potrivit, fie cu 7 dacă schimbăm). Din moment ce 7 > 4, schimbăm.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Dupa acest proces, porțiunea sortate fost extins de către un element, acum avem cinci în loc de patru elemente. Fiecare iterație face acest lucru și până la sfârșit vom sorta întreaga matrice.
dacă doriți să citiți un articol detaliat, dedicat pentru sortare inserție, ne-am luat te-a acoperit!,
implementare
complexitatea timpului
Din nou, trebuie să ne uităm la cel mai rău scenariu pentru algoritmul nostru și va fi din nou exemplul în care întreaga matrice coboară.
Acest lucru se datorează faptului că în fiecare iterație, va trebui să mutăm întreaga listă sortată cu una, care este O(n). Trebuie să facem acest lucru pentru fiecare element din fiecare matrice, ceea ce înseamnă că va fi delimitat de O(n^2).
Sortare selecție
explicație
Sortare selecție împarte, de asemenea, matrice într-un subarray sortate și nesortate., Totuși, de această dată, sortate subarray este format prin introducerea elementul minim din nesortate subarray la sfârșitul sortat, de pompare:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
Aplicare
În fiecare iterație, vom presupune că primul element nesortate este minim și parcurge restul pentru a vedea dacă există un element mai mic.,odată ce găsim minimul curent al părții nesortate a tabloului, îl schimbăm cu primul element și îl considerăm o parte a tabloului sortat:
complexitatea timpului
găsirea minimului este O(n) pentru lungimea tabloului, deoarece trebuie să verificăm toate elementele. Trebuie să găsim minimul pentru fiecare element al matricei, făcând întregul proces delimitat de O(n^2).,
Merge Sort
explicație
Merge Sort folosește recursivitatea pentru a rezolva problema sortării mai eficient decât algoritmii prezentați anterior și, în special, folosește o abordare divide și conquer.
Folosind aceste concepte, vom rupe întreaga matrice în două subarrays și apoi:
- Sorta jumătatea stângă de matrice (recursiv)
- un Fel de matrice (recursiv)
- Fuzioneze soluții
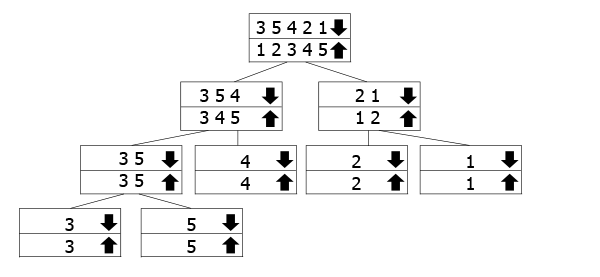
Acest copac este menit să reprezinte cât apelurile recursive de muncă., Matricele marcate cu săgeata în jos sunt cele pentru care numim funcția, în timp ce fuzionăm cele cu săgeata în sus mergând înapoi. Deci, urmați săgeata în jos la partea de jos a copacului, și apoi du-te înapoi în sus și fuziona.
În exemplul nostru, avem matrice
3 5 3 2 1, așa că l-am împărți în3 5 4și2 1. Pentru a le sorta, le împărțim în continuare în componentele lor. Odată ce am ajuns în partea de jos, începem să fuzionăm și să le sortăm pe măsură ce mergem.,dacă doriți să citiți un articol detaliat, dedicat pentru Merge Sort, v-am acoperit!
implementare
funcția de bază funcționează destul de mult așa cum este prevăzut în explicație. Suntem doar in trecere indici
leftșirightcare sunt indici de cea mai din stânga și dreapta pe elementul cel mai de subarray vrem la fel. Inițial, acestea ar trebui să fie0șiarray.length-1, în funcție de punerea în aplicare.,baza recursivității noastre ne asigură că ieșim când am terminat sau când
rightșileftne întâlnim. Vom găsi un mijlocmid, și un fel subarrays stânga și la dreapta de ea recursiv, în cele din urmă fuzionează soluțiile noastre.dacă vă amintiți graficul nostru arbore, s-ar putea să vă întrebați de ce nu creăm două noi tablouri mai mici și să le transmitem mai departe. Acest lucru se datorează faptului că pe matrice foarte lungi, acest lucru ar provoca un consum imens de memorie pentru ceva care este în esență inutil.,
Merge Sort deja nu funcționează în loc din cauza merge pas, iar acest lucru ar servi doar pentru a agrava eficiența memoriei sale. Logica arborelui nostru de recursivitate rămâne altfel aceeași, totuși, trebuie doar să urmăm indexurile pe care le folosim:
pentru a îmbina subarrays sortate într-una, va trebui să calculăm lungimea fiecăruia și să facem matrice temporare pentru a le copia, astfel încât să putem schimba liber matricea noastră principală.după copiere, parcurgem matricea rezultată și îi atribuim minimul curent., Pentru că subarrays sunt sortate, doar că am ales cel mai mic dintre cele două elemente care nu au fost alese atât de departe, și pentru a muta iterator pentru că subarray înainte:
Complexitatea Timp
Dacă vrem să obțină complexității algoritmi recursive, vom avea pentru a obține un pic mathy.Teorema Master este folosită pentru a descoperi complexitatea timpului algoritmilor recursivi. Pentru algoritmii non-recursivi, de obicei am putea scrie complexitatea exactă a timpului ca un fel de ecuație, și apoi folosim notația Big-O pentru a le sorta în clase de algoritmi cu comportament similar.,
problema cu algoritmi recursivi este că aceeași ecuație ar arăta ceva de genul:
$$
T (n) = aT(\frac{n}{b}) + cn^k
$$ecuația în sine este recursivă! În această ecuație,
ane spune cât de multe ori o numim recursivitate, șibne spune în câte părți problema noastră este divizată. În acest caz, acest lucru poate părea o distincție neimportantă, deoarece acestea sunt egale pentru mergesort, dar pentru unele probleme este posibil să nu fie.,restul ecuației este complexitatea fuzionării tuturor acestor soluții într-una la sfârșit., Maestrul Teorema rezolvă această ecuație pentru noi:
$$
T(n) = \Bigg\{
\begin{matrix}
O(n^{log_ba}), &>b^k \\ O(n^klog n), & a = b^k \\ O(n^k), & < b^k
\end{matrix}
$$Dacă
T(n)este de execuție a algoritmului atunci când sortarea un array de lungimen, un Fel de Îmbinare va rula de două ori pentru tablouri, care sunt jumătate din lungimea de matrice inițială.,Deci, dacă avem
a=2,b=2. Pasul de îmbinare are o (n) memorie, decik=1. Acest lucru înseamnă ecuația de Îmbinare Fel ar arăta după cum urmează:$$
T(n) = 2T(\frac{n}{2})+nc
$$Dacă vom aplica Teorema Master, vom vedea că, în cazul nostru este cea în care
a=b^kpentru că avem2=2^1. Asta înseamnă că complexitatea noastră este O (nlog n). Aceasta este o complexitate de timp extrem de bună pentru un algoritm de sortare, deoarece s-a dovedit că o matrice nu poate fi sortată mai repede decât O(nlog n).,în timp ce versiunea pe care am prezentat-o consumă memorie, există versiuni mai complexe de Merge Sort care ocupă doar o(1) Spațiu.în plus, algoritmul este extrem de ușor de paralelizat, deoarece apelurile recursive de la un nod pot fi rulate complet independent de ramuri separate. În timp ce nu vom intra în cum și de ce, deoarece este dincolo de domeniul de aplicare al acestui articol, merită să țineți cont de avantajele utilizării acestui algoritm special.,
Heapsort
explicație
pentru a înțelege corect de ce funcționează Heapsort, trebuie să înțelegeți mai întâi structura pe care se bazează – heap. Vom vorbi în termeni de un heap binar în mod specific, dar puteți generaliza cele mai multe dintre acestea la alte structuri heap, de asemenea.un heap este un copac care satisface proprietatea heap, care este că pentru fiecare nod, toți copiii săi se află într-o relație dată cu acesta. În plus, o grămadă trebuie să fie aproape completă., Aproape un arbore binar complet de adâncime
dare un subarbore al adâncimed-1cu aceeași rădăcină, care este completă, și în care fiecare nod cu o stânga descendent a o finaliza subarborele stâng. Cu alte cuvinte, atunci când adăugăm un nod, mergem întotdeauna pentru poziția din stânga la cel mai înalt nivel incomplet.dacă heap-ul este un heap max, atunci toți copiii sunt mai mici decât părintele, iar dacă este un heap min, toți sunt mai mari.,cu alte cuvinte, pe măsură ce vă deplasați în copac, ajungeți la numere mai mici și mai mici (min-heap) sau numere mai mari și mai mari (max-heap). Aici este un exemplu de un max-heap: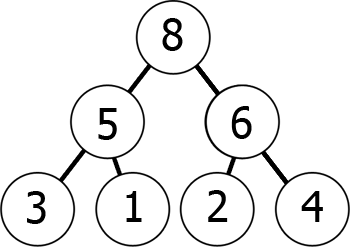
putem reprezenta acest lucru max-heap în memorie ca o matrice în felul următor:
8 5 6 3 1 2 4Vă puteți imagina cât de lectură din graficul de nivel de nivel, de la stânga la dreapta., Ceea ce am realizat prin asta este că dacă luăm
kthelement în matrice, copii sa poziții sunt2*k+1și2*k+2(presupunând că indexarea incepe de la 0). Puteți verifica acest lucru pentru tine.invers, pentru elementul
kthpoziția părintelui este întotdeauna(k-1)/2.știind acest lucru, puteți cu ușurință „max-heapify” orice matrice dată. Pentru fiecare element, verificați dacă vreunul dintre copiii săi este mai mic decât acesta., Dacă sunt, schimbați unul dintre ele cu părintele și repetați recursiv acest pas cu părintele (deoarece noul element mare ar putea fi în continuare mai mare decât celălalt copil).frunzele nu au copii, deci sunt trivial max-grămezi proprii:
-
6 1 8 3 5 2 4: ambii copii sunt mai mici decât părintele, deci totul rămâne la fel.
-
6 1 8 3 5 2 4: deoarece 5> 1, le schimbăm. Noi heapify recursiv pentru 5 Acum.6 5 8 3 1 2 4: ambii copii sunt mai mici, deci nu se întâmplă nimic.,
-
6 5 8 3 1 2 4: deoarece 8> 6, le schimbăm.
-
8 5 6 3 1 2 4: avem heap imaginea de mai sus!odată ce am învățat să heapify o matrice restul este destul de simplu. Schimbăm rădăcina grămezii cu sfârșitul matricei și scurtăm matricea cu una.,
Ne-heapify scurtat matrice din nou, și repetați procesul:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: schimbat
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: schimbat
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: schimbat
Și așa mai departe, sunt sigur că puteți vedea modelul în curs de dezvoltare.
implementare
complexitatea timpului
când ne uităm la funcția
heapify(), totul pare să se facă în O(1), dar apoi există acel apel recursiv plictisitor.,de câte ori va fi numit, în cel mai rău caz? Ei bine, cel mai rău caz, se va propaga tot drumul la partea de sus a grămezii. Se va face acest lucru sărind la părintele fiecărui nod, deci în jurul poziției
i/2. asta înseamnă că va face în cel mai rău caz log n salturi înainte de a ajunge în partea de sus, astfel încât complexitatea este O(log n).heapSort()este în mod clar O(n), ca urmare a de-bucle iterarea prin întreaga matrice, acest lucru ar face complexitatea totală de Heapsort O(nlog n).,Heapsort este un fel în loc, ceea ce înseamnă că este nevoie de o(1) spațiu suplimentar, Spre deosebire de Merge Sort, dar are și unele dezavantaje, cum ar fi dificil de paralelizat.
Quicksort
explicație
Quicksort este un alt algoritm de divizare și cucerire. Alege un element dintr-o matrice ca pivot și Sortează toate celelalte elemente din jurul său, de exemplu elemente mai mici la stânga și mai mari la dreapta.acest lucru garantează că pivotul este în locul potrivit după proces., Apoi algoritmul recursiv face același lucru pentru porțiunile din stânga și din dreapta ale matricei.
implementare
complexitatea timpului
complexitatea timpului Quicksort poate fi exprimată cu următoarea ecuație:
$$
T (n) = T(k) + T(n-k-1) + O(n)
$$cel mai rău caz este atunci când cel mai mare sau cel mai mic element este întotdeauna ales pentru pivot. Ecuația ar arăta astfel:
$$
T (N) = T(0) + T(n-1) + O(n) = T(N-1) + O(n)
$$Acest lucru se dovedește a fi O(n^2).,acest lucru poate suna rău, așa cum am învățat deja mai mulți algoritmi care rulează în timpul O(nlog n) ca cel mai rău caz, dar Quicksort este de fapt foarte utilizat pe scară largă.acest lucru se datorează faptului că are o durată medie de rulare foarte bună, de asemenea limitată de O(nlog n) și este foarte eficientă pentru o mare parte din intrările posibile.
unul dintre motivele pentru care este preferată îmbinarea sortării este că nu necesită spațiu suplimentar, toată sortarea se face în loc și nu există apeluri de alocare și dealocare costisitoare.,
comparație de performanță
toate acestea fiind spuse, este adesea util să rulați toți acești algoritmi pe mașina dvs. de câteva ori pentru a vă face o idee despre modul în care acestea funcționează.
vor avea performanțe diferite cu diferite colecții care sunt sortate, desigur, dar chiar și având în vedere acest lucru, ar trebui să puteți observa unele tendințe.
să rulăm toate implementările, una câte una, fiecare pe o copie a unei matrice amestecate de 10.000 de numere întregi:
putem vedea în mod evident că Bubble Sort este cel mai rău atunci când vine vorba de performanță., Evitați să-l utilizați în producție dacă nu puteți garanta că se va ocupa doar de colecții mici și nu va bloca aplicația.HeapSort și QuickSort sunt cele mai bune performanțe. Deși obțin rezultate similare, QuickSort tinde să fie un pic mai bun și mai consistent – ceea ce se verifică.
sortare în Java
interfață comparabilă
Dacă aveți propriile tipuri, poate fi greoaie implementarea unui algoritm de sortare separat pentru fiecare. De aceea Java oferă o interfață care vă permite să utilizați
Collections.sort()pe propriile clase.,Pentru a face acest lucru, clasa trebuie să implementeze
Comparable<T>interfață, în cazul în careTeste genul tău, și suprascrie o metoda numita.compareTo().Această metodă returnează un număr întreg negativ dacă
thiseste mai mic decât argumentul element, 0 dacă sunt egale, și un număr întreg pozitiv dacăthiseste mai mare.În exemplul nostru, am făcut o clasă
Student, și fiecare elev este identificat printr-unidși un an au început studiile lor.,și iată cum să-l folosească într-o aplicație:Output:
interfață Comparator
am putea dori să sorteze obiectele noastre într-un mod neortodox pentru un anumit scop, dar nu vrem să pună în aplicare că, ca comportamentul implicit al clasei noastre, sau am putea sorta o colecție de tip încorporat într-un mod non-implicit.pentru aceasta, putem folosi interfața
Comparator., De exemplu, să luămStudentclasă, și un fel doar de ID-ul:Dacă am înlocui un fel de apel în principal cu următoarele:
Arrays.sort(a, new SortByID());Ieșire:
Cum Funcționează
Collection.sort()lucrări de asteptare de fond al sistemuluiArrays.sort()metodă, în timp ce sortarea se folosește un Fel de introducere pentru tablouri mai scurtă decât 47 de ani, și Quicksort pentru restul.,se bazează pe o implementare specifică cu două pivoți a Quicksort, care asigură evitarea majorității cauzelor tipice de degradare în performanță pătratică, conform documentației JDK10.concluzie
sortarea este o operație foarte frecventă cu seturi de date, fie că este vorba de a le analiza în continuare, de a accelera căutarea folosind algoritmi mai eficienți care se bazează pe datele sortate, filtrarea datelor etc.
sortarea este susținută de multe limbi, iar interfețele ascund adesea ceea ce se întâmplă de fapt cu programatorul., În timp ce această abstractizare este binevenită și necesară pentru o muncă eficientă, uneori poate fi mortală pentru eficiență și este bine să știți cum să implementați diferiți algoritmi și să vă familiarizați cu avantajele și dezavantajele acestora, precum și cum să accesați cu ușurință implementările încorporate.
-
-