and its implementation in Python
In diesem Blog werden wir versuchen, tiefer in die zufällige Wald Taxonomie zu graben. Hier lernen wir Ensemble Learning kennen und werden versuchen, es mit Python zu implementieren.,
Den Code finden Sie hier.
Es ist ein Ensemble Baum-basierten Lernalgorithmus. Der Random Forest Classifier ist eine Gruppe von Entscheidungsbäumen aus einer zufällig ausgewählten Teilmenge des Trainingssatzes. Es aggregiert die Stimmen aus verschiedenen Entscheidungsbäumen, um die endgültige Klasse des Testobjekts zu bestimmen.
Ensemble-Algorithmus:
Ensemble-Algorithmen sind solche, die mehr als einen Algorithmus derselben oder anderer Art zur Klassifizierung von Objekten kombinieren. Zum Beispiel Vorhersage über Naive Bayes, SVM und Entscheidungsbaum ausführen und dann für die endgültige Prüfung der Klasse für das Testobjekt abstimmen.,

Types of Random Forest models:
1. Random Forest Prediction for a classification problem:
f(x) = majority vote of all predicted classes over B trees
2.,n :


The 9 decision tree classifiers shown above can be aggregated into a random forest ensemble which combines their input (on the right)., Die horizontalen und vertikalen Achsen der obigen Entscheidungsbaumausgaben können als Merkmale x1 und x2 betrachtet werden. Bei bestimmten Werten jedes Merkmals gibt der Entscheidungsbaum eine Klassifizierung von „blau“, „grün“, „rot“ usw. aus.
Diese obigen Ergebnisse werden durch Modellabstimmungen oder Mittelwertbildung zu einem einzelnen
– Ensemblemodell aggregiert, das die Ausgabe eines einzelnen Entscheidungsbaums übertrifft.
Eigenschaften und Vorteile von Random Forest:
- Es ist einer der genauesten verfügbaren Lernalgorithmen. Für viele Datensätze erzeugt es einen hochgenauen Klassifikator.,
- Es läuft effizient auf großen Datenbanken.
- Es kann Tausende von Eingabevariablen ohne Löschen von Variablen verarbeiten.
- Es gibt Schätzungen, welche Variablen in der Klassifizierung wichtig sind.
- Es erzeugt eine interne unvoreingenommene Schätzung des Verallgemeinerungsfehlers im Verlauf des Waldgebäudes.
- Es verfügt über eine effektive Methode zur Schätzung fehlender Daten und behält die Genauigkeit bei, wenn ein großer Teil der Daten fehlt.,
Nachteile von Random Forest:
- Bei einigen Datensätzen mit lauten Klassifizierungs – / Regressionsaufgaben wurde eine Überanpassung von Random Forests beobachtet.
- Für Daten, einschließlich kategorialer Variablen mit unterschiedlicher Anzahl von Ebenen, sind zufällige Wälder zugunsten dieser Attribute mit mehr Ebenen voreingenommen. Daher sind die Werte mit variabler Wichtigkeit aus Random Forest für diese Art von Daten nicht zuverlässig.,div>
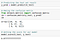
Creating a Random Forest Classification model and fitting it to the training data

Predicting the test set results and making the Confusion matrix
Conclusion :
In this blog we have learned about the Random forest classifier and its implementation., Wir haben uns den zusammengesetzten Lernalgorithmus in Aktion angesehen und versucht zu verstehen, was Random Forest von anderen Algorithmen für maschinelles Lernen unterscheidet.