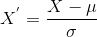Introdução à escala de recursos
I estava recentemente a trabalhar com um conjunto de dados que tinha várias características abrangendo vários graus de magnitude, gama e unidades. Este é um obstáculo significativo como alguns algoritmos de aprendizagem de máquinas são altamente sensíveis a essas características.estou certo de que a maioria de vocês deve ter enfrentado este problema em seus projetos ou em sua jornada de aprendizagem., Por exemplo, uma característica é inteiramente em quilogramas, enquanto a outra é em gramas, outra é litros, e assim por diante. Como podemos usar esses recursos quando eles variam tão vastamente em termos do que eles estão apresentando?
foi aqui que me virei para o conceito de escala de recursos. É uma parte crucial da fase de pré-processamento de dados, mas eu vi muitos iniciantes ignorá-lo (em detrimento de seu modelo de aprendizagem de máquina).,

Qual poderia ser a razão por trás desta peculiaridade?além disso, Qual é a diferença entre normalização e normalização? Estes são dois dos recursos mais comumente usados técnicas de escala na aprendizagem de máquinas, mas um nível de ambiguidade existe em sua compreensão. Quando você deve usar qual técnica?,
eu vou responder a estas perguntas e mais neste artigo sobre escala de recursos. Nós também implementaremos o scaling de recursos em Python para lhe dar uma compreensão prática de como ele funciona para diferentes algoritmos de aprendizagem de máquinas.
nota: eu assumo que você está familiarizado com Python e core machine learning algorithms., Se você é novo para isso, eu recomendo ir através dos cursos de:
- Python para Ciência de Dados
- Tudo de graça Máquina de Cursos de Aprendizagem pelo google Analytics Vidhya
- Aplicada Máquina de Aprendizagem
Índice
- Por que Usar o Recurso de Dimensionamento?o que é a normalização?o que é a normalização?a grande questão – normalizar ou padronizar?,
- Implementar o Recurso de Dimensionamento em Python
- Normalização usando Sklearn
- Padronização usando Sklearn
- a Aplicação de Recurso de Dimensionamento de Algoritmos de Aprendizado
- K-Vizinhos mais próximos (KNN)
- Suporte Vetor Regressor
- Árvore de Decisão
Por que Usar o Recurso de Dimensionamento?
a primeira questão que precisamos abordar-por que precisamos escalar as variáveis em nosso conjunto de dados? Alguns algoritmos de aprendizagem de máquinas são sensíveis à escala de recursos, enquanto outros são virtualmente invariantes a ele., Permitam-me que explique isso mais pormenorizadamente.
algoritmos de descida de gradientes
algoritmos de aprendizagem de máquinas como regressão linear, regressão logística, rede neural, etc. que usam descida gradiente como uma técnica de otimização exigem que os dados sejam dimensionados. Dê uma olhada na fórmula para descida do gradiente abaixo:

a presença do valor do recurso X na fórmula afetará o tamanho do passo da descida do gradiente. A diferença nas gamas de recursos irá causar diferentes tamanhos de etapas para cada característica., Para garantir que a descida do gradiente se move suavemente em direção aos mínimos e que os passos para descida do gradiente são atualizados na mesma taxa para todas as características, escalamos os dados antes de alimentá-lo ao modelo.
ter características em uma escala semelhante pode ajudar a descida gradiente convergir mais rapidamente para os mínimos.
algoritmos à distância
algoritmos à distância como KNN, K-means, e SVM são mais afetados pela gama de características., Isso é porque nos bastidores eles estão usando distâncias entre os pontos de dados para determinar sua similaridade.
Por exemplo, vamos dizer que nós temos dados que contém escola CGPA dezenas de estudantes (variando de 0 a 5) e seus rendimentos futuros (em milhares de Rúpias):

uma vez que ambos os recursos têm escalas diferentes, há uma chance de que a maior weightage é dado para recursos com maior magnitude. Isto irá impactar o desempenho do algoritmo de aprendizagem da máquina e, obviamente, não queremos que o nosso algoritmo seja bimensionado em direção a uma característica.,
portanto, escalamos os nossos dados antes de empregar um algoritmo à distância de modo que todas as características contribuam igualmente para o resultado.,nts A e B, e entre B e C, antes e após a escala, como mostrado abaixo:
- Distância AB antes de escala =>

- Distância BC antes de escala =>

- Distância AB após scaling =>

- Distância BC após scaling =>

o Dimensionamento trouxe tanto os recursos para a imagem e as distâncias são agora mais próxima do que eles eram antes de aplicada a escala.,
algoritmos baseados em árvores
algoritmos baseados em árvores, por outro lado, são bastante insensíveis à escala das características. Pense nisso, uma árvore de decisão está apenas dividindo um nó baseado em uma única característica. A árvore de decisão divide um nó em uma característica que aumenta a homogeneidade do nó. Esta divisão em uma característica não é influenciada por outras características.
assim, não há praticamente nenhum efeito das características restantes na divisão. Isto é o que os torna invariantes à escala das características!o que é a normalização?,
normalização é uma técnica de escala na qual os valores são deslocados e redimensionados de modo que eles terminam variando entre 0 e 1. É também conhecido como Min-Max scaling.
Aqui está a fórmula para a normalização:
Aqui, Xmax e Xmin são os valores máximo e mínimo da funcionalidade, respectivamente.,
- Quando o valor de X é o valor mínimo na coluna, o numerador será 0, e portanto X’ é 0
- por outro lado, quando o valor de X é o valor máximo da coluna, o valor do numerador é igual ao denominador e, portanto, o valor de X’ 1
- Se o valor de X é entre o mínimo e o valor máximo, em seguida, o valor de X entre 0 e 1
o Que é Padronização?
padronização é outra técnica de escala onde os valores são centrados em torno da média com um desvio padrão unitário., Isto significa que a média do atributo se torna zero e a distribuição resultante tem um desvio padrão unitário.
Aqui está a fórmula para padronização:
é a média dos valores de recurso e
é o desvio padrão dos valores de recurso. Note-se que, neste caso, os valores não se restringem a uma determinada gama.
Agora, a grande questão em sua mente deve ser quando devemos usar a normalização e quando devemos usar a padronização? Vamos descobrir!,
a grande questão – normalizar ou padronizar?
normalização vs. normalização é uma questão eterna entre os recém-chegados ao aprendizado de máquina. Permitam-me que explique melhor a resposta nesta secção.
- normalização é bom de usar quando você sabe que a distribuição dos seus dados não segue uma distribuição gaussiana. Isso pode ser útil em algoritmos que não assumem qualquer distribuição dos dados, como vizinhos K-mais próximos e Redes Neurais.por outro lado, a normalização pode ser útil nos casos em que os dados seguem uma distribuição gaussiana., No entanto, isto não tem de ser necessariamente verdade. Além disso, ao contrário da normalização, a normalização não tem uma gama delimitadora. Assim, mesmo que você tenha valores anómalos em seus dados, eles não serão afetados pela padronização.
No entanto, no final do dia, a escolha de usar a normalização ou normalização dependerá do seu problema e do algoritmo de aprendizagem da máquina que está a usar. Não há nenhuma regra dura e rápida para dizer quando normalizar ou padronizar seus dados., Você pode sempre começar por ajustar o seu modelo a dados brutos, normalizados e padronizados e comparar o desempenho para melhores resultados.
é uma boa prática ajustar o escalador nos dados de treinamento e, em seguida, usá-lo para transformar os dados de teste. Isto evitaria qualquer fuga de dados durante o processo de teste do modelo. Além disso, a escala dos valores alvo não é geralmente necessária.
implementando escala de recursos em Python
Agora vem a parte divertida-colocando o que aprendemos em prática., Vou aplicar a escala de recursos a alguns algoritmos de aprendizagem de máquinas no conjunto de dados do Big Mart que tomei a plataforma do DataHack.
eu vou saltar as etapas de pré-processamento, uma vez que eles estão fora do escopo deste tutorial. Mas você pode encontrá-los bem explicados neste artigo. Esses passos irão permitir que você alcance o Top 20 percentil no hackathon leaderboard de modo que vale a pena conferir!
assim, vamos primeiro dividir os nossos dados em conjuntos de treino e testes:
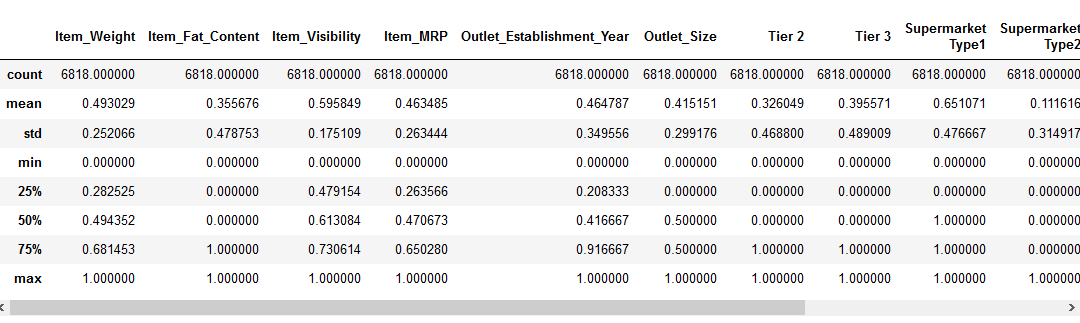
Antes de passar para a parte de escala de recurso, Vamos olhar para os detalhes sobre os nossos dados usando a pd.,describe (): método:
podemos ver que há uma enorme diferença no intervalo de valores presentes no nosso características numéricas: Item_Visibility, Item_Weight, Item_MRP, e Outlet_Establishment_Year. Vamos tentar corrigir isso usando escala de recursos!
Nota: você vai notar valores negativos na funcionalidade Item_visibilidade porque eu tomei a transformação de log para lidar com a skewness na funcionalidade.
normalização usando o sklearn
para normalizar os seus dados, terá de importar a Minmaxscar da biblioteca sklearn e aplicá-la ao nosso conjunto de dados., Então, vamos fazer isso!
Vamos ver como a normalização tem afetado nosso conjunto de dados:
Todos os recursos que agora têm um valor mínimo de 0 e um valor máximo de 1. Perfeito!
tente o código acima na janela de codificação ao vivo abaixo!!
a seguir, vamos tentar padronizar os nossos dados.
padronização usando sklearn
para padronizar seus dados, você precisa importar o padrão da biblioteca sklearn e aplicá-lo ao nosso conjunto de dados., Aqui está como você pode fazer isso:
você teria notado que eu só aplicei padronização nas minhas colunas numéricas e não nas outras características codificadas a quente. Padronizar as características codificadas a quente significaria atribuir uma distribuição a características categóricas. Não queres fazer isso!mas por que não fiz o mesmo ao normalizar os dados? Porque as funcionalidades codificadas a quente já estão no intervalo entre 0 e 1. Assim, a normalização não afetaria seu valor.,
Right, let’s have a look at how standardization has transformed our data:
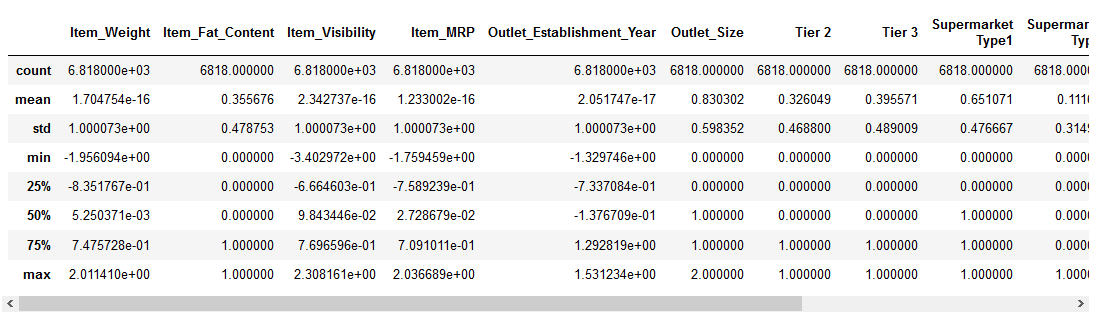
The numerical features are now centered on the mean with a unit standard deviation. Da hora!
comparar dados não emparelhados, normalizados e padronizados
é sempre óptimo visualizar os seus dados para compreender a distribuição presente. Podemos ver a comparação entre os nossos dados sem escala e sem escala usando boxplots.
pode aprender mais sobre a visualização de dados aqui.,
Você pode notar como a escala das características traz tudo para a perspectiva. As características são agora mais comparáveis e terão um efeito semelhante nos modelos de aprendizagem.
aplicando escalas para algoritmos de aprendizagem de máquinas
Agora é hora de treinar alguns algoritmos de aprendizagem de máquinas em nossos dados para comparar os efeitos de diferentes técnicas de escalação no desempenho do algoritmo. Eu quero ver o efeito da escala em três algoritmos em particular: K-vizinhos mais próximos, suporte Regressor de vetores, e árvore de decisão.,K-vizinhos mais próximos
Como vimos antes, KNN é um algoritmo à distância que é afetado pela gama de características. Vamos ver como funciona nos nossos dados, antes e depois da escala:
pode ver que a escala das funcionalidades fez baixar a pontuação RMSE do nosso modelo KNN. Especificamente, os dados normalizados realizam um pouco melhor do que os dados padronizados.Nota: estou a medir a RMSE aqui porque este concurso avalia a RMSE.
Support Vector Regressor
SVR is another distance-based algorithm., Então vamos verificar se ele funciona melhor com normalização ou normalização:
podemos ver que a escala das características faz baixar a pontuação RMSE. E os dados padronizados têm realizado melhor do que os dados normalizados. Porque achas que é esse o caso?
a documentação do sklearn afirma que a SVM, com o kernel RBF, assume que todas as características são centradas em torno de zero e variância é da mesma ordem. Isto é porque uma característica com uma variância maior do que a de outros impede o estimador de aprender de todas as características., Muito bom!
Árvore de decisão
já sabemos que uma árvore de decisão é invariável para caracterizar a escala. Mas eu queria mostrar um exemplo prático de como ele funciona nos dados:
você pode ver que a pontuação RMSE não moveu uma polegada ao dimensionar as características. Portanto, fique descansado quando você está usando algoritmos baseados em árvores em seus dados!,
End Notes
este tutorial cobriu a relevância de usar a escala de recursos em seus dados e como a normalização e normalização têm efeitos variáveis no trabalho de algoritmos de aprendizagem de máquinas
tenha em mente que não há uma resposta correta para quando usar a normalização e vice-versa. Tudo depende dos seus dados e do algoritmo que está a usar.
Como próximo passo, eu encorajo você a experimentar a escala de recursos com outros algoritmos e descobrir o que funciona melhor – normalização ou padronização?, Eu recomendo que você use os dados de vendas BigMart para essa finalidade para manter a continuidade com este artigo. E não se esqueça de compartilhar seus insights na seção de comentários abaixo!
Você também pode ler este artigo no nosso aplicativo móvel