quantos genes estão num genoma?
modo de leitor
já examinámos a grande diversidade de tamanhos de genoma em todo o mundo vivo (Ver Tabela na vinheta sobre ” quão grandes são os genomas?”). Como um primeiro passo para refinar a nossa compreensão do conteúdo informativo destes genomas, precisamos de uma noção do número de genes que eles abrigam. Quando nos referimos a genes, estaremos pensando em genes codificadores de proteínas excluindo a coleção cada vez maior de regiões codificadoras de RNA em genomas.,
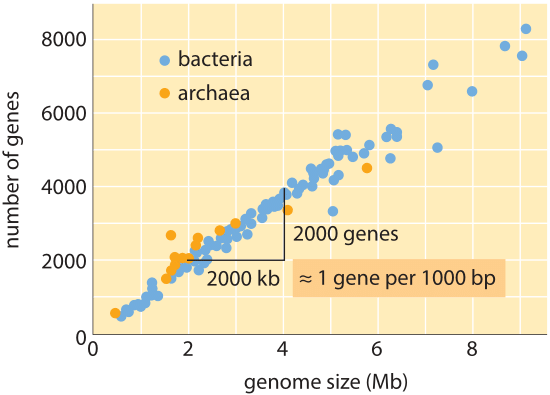
Figura 1: Número de genes em função do tamanho do genoma. A figura mostra dados para uma variedade de bactérias e archaea, com a inclinação da linha de dados confirmando a regra de ouro simples que relaciona o tamanho do genoma e o número do gene. (Adaptado de M. Lynch, the Origins of Genome Architecture.,)
ao Longo de toda a árvore da vida, que o genoma de tamanhos diferentes, quanto de 8 ordens de grandeza (de <2 kb para o vírus da Hepatite D (BNID 105570) para >100 Gbp para o Mármore lungfish (BNID 100597) e certas Fritillaria flores (BNID 102726)), a variedade no número de genes varia de menos de 5 ordens de grandeza (de vírus como o MS2 e QB bacteriófagos tendo apenas 4 genes para cerca de cem mil no trigo). Muitas bactérias têm vários milhares de genes., Este conteúdo genético é proporcional ao tamanho do genoma e às proteínas, como mostrado abaixo. Curiosamente, os genomas eucarióticos, que são muitas vezes mil vezes maiores do que os dos procariontes, contêm apenas uma ordem de magnitude mais genes do que seus homólogos procarióticos. A incapacidade de estimar com sucesso o número de genes em eucariontes com base no conhecimento do conteúdo genético dos procariontes foi uma das reviravoltas inesperadas da biologia moderna.,
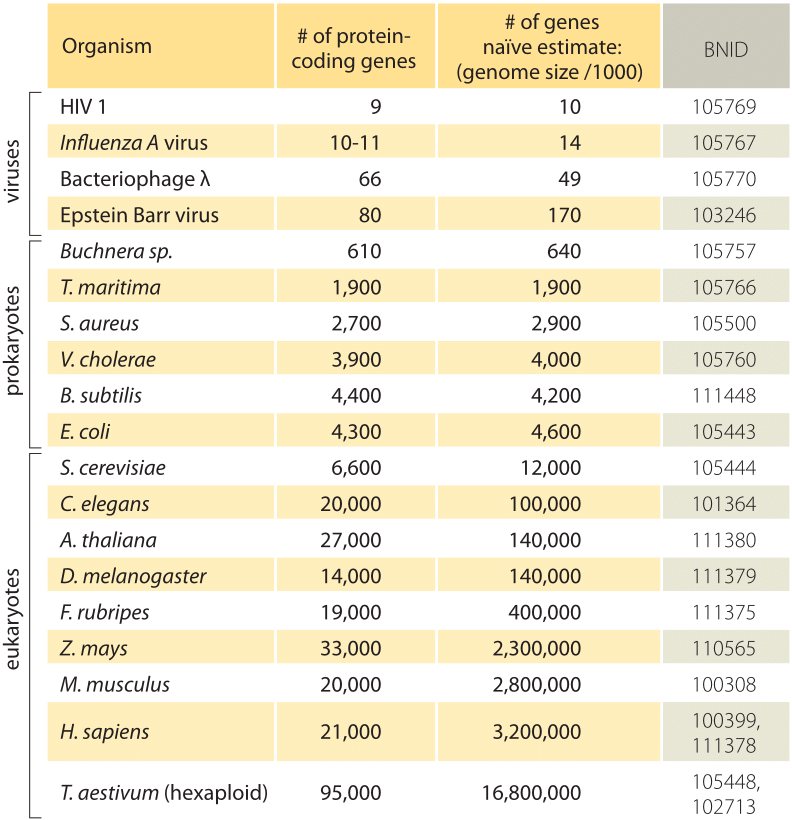
Tabela 1: comparação entre o número de genes de um organismo e uma ingênua estimativa com base no tamanho do genoma dividido por um fator constante de 1000bp/gene, i.e. número previsto de genes = tamanho do genoma/1000. Descobre-se que esta regra grosseira funciona surpreendentemente bem para muitas bactérias e archaea, mas falha miseravelmente para organismos multicelulares.
a estimativa mais simples do número de genes num genoma desenrola-se assumindo que a totalidade dos códigos do genoma para genes de interesse., Para progredir com a estimativa, precisamos ter uma medida do número de aminoácidos em uma proteína típica que vai demorar para ser aproximadamente 300, cientes, contudo, o fato de que, como genomas, proteínas vêm em uma ampla variedade de tamanhos de si, como é revelado na vinheta sobre o assunto, “quais são os tamanhos das proteínas?”. Com base nesta suposição escassa, vemos que o número de bases necessárias para codificar a nossa proteína típica é de aproximadamente 1000 (3 pares de base por aminoácido)., Assim, dentro dessa mentalidade, o número de genes contidos em um genoma é estimado como sendo o tamanho do genoma / 1000. Para genomas bacterianos, esta estratégia funciona surpreendentemente bem como pode ser visto na tabela 1 e na Figura 1. Por exemplo, quando aplicado à E. coli K-12, genoma de 4.6 x 106 bp, esta regra de ouro leva a uma estimativa de 4600 genes, que podem ser comparados com o melhor conhecimento atual desta quantidade, que é 4225. Ao passar por uma dúzia de bactérias representativas e genealogias na tabela, observa-se um poder preditivo igualmente impressionante a cerca de 10%., Por outro lado, esta estratégia falha espectacularmente quando a aplicamos aos genomas eucarióticos, resultando, por exemplo, na estimativa de que o número de genes no genoma humano deveria ser de 3.000.000, uma sobrestimação grosseira. A falta de fiabilidade desta estimativa ajuda a explicar a existência do Genesweep betting pool que, ainda no início dos anos 2000, tinha pessoas a apostar no número de genes no genoma humano, com as estimativas das pessoas variando em mais do que um factor de dez.,
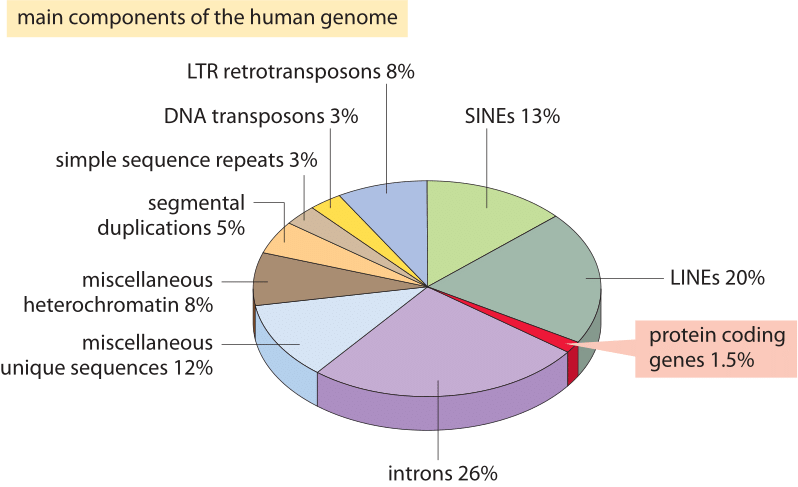
Figura 2: os diferentes componentes da sequência que compõem o genoma humano. Cerca de 1,5% do genoma consiste das cerca de 20.000 sequências codificadoras de proteínas que são intercaladas pelos intrões não codificadores, perfazendo cerca de 26%. Elementos transponíveis são a maior fração (40-50%), incluindo, por exemplo, elementos nucleares intercalados longos (linhas), e elementos nucleares intercalados curtos (SINEs). A maioria dos elementos transponíveis são remanescentes genômicos, que estão atualmente extintos. (BNID 110283, Adapted from T. R. Gregory Nat Rev Genet., 9: 699-708, 2005 based on International Human Genome Sequencing Consortium. Sequenciamento inicial e análise do genoma humano. Nature 409: 860 2001.)
o que explica esta falha espectacular da estimativa mais ingénua e o que nos ensina sobre a informação organizada em genomas? Genomas eucarióticos, especialmente aqueles associados com organismos multicelulares, são caracterizados por uma série de características intrigantes que perturbam a simples imagem de codificação explorada na estimativa ingênua., Estas diferenças na utilização do genoma são ilustradas pictorialmente na Figura 2, que mostra a percentagem do genoma utilizado para outros fins que não a codificação das proteínas. Como é evidente na Figura 1, os procariontes podem compactar eficazmente as suas sequências de codificação de proteínas de modo a que sejam quase contínuas e resultem em que menos de 10% dos seus genomas sejam atribuídos a ADN não codificante (12% na E. coli, BNID 105750), enquanto que nos seres humanos mais de 98% (BNID 103748) é código não proteico.,
a descoberta destes outros usos do genoma constituem alguns dos insights mais importantes sobre o DNA, e biologia mais geralmente, a partir dos últimos 60 anos. Uma dessas utilizações alternativas para o genômico imobiliário é o genoma regulatório, ou seja, a forma como grandes pedaços do genoma são usados como alvos para a ligação de proteínas regulatórias que dão origem ao controle combinatório tão típico dos genomas em organismos multicelulares., Outra das principais características dos genomas eucarióticos é a organização de seus genes em intrões e exões, com os exons expressos sendo muito menores do que os intrões interventes e articulados. Para além destas características, existem retrovírus endógenos, relíquias fósseis de antigas infecções virais e, surpreendentemente, mais de 50% do genoma é absorvido pela existência de elementos repetitivos e transposões, várias formas das quais podem talvez ser interpretadas como genes egoístas que têm mecanismos para proliferar num genoma hospedeiro., Alguns desses elementos repetitivos e transposons ainda estão ativos hoje, enquanto outros permaneceram uma relíquia depois de perder a capacidade de proliferar ainda mais no genoma.em conclusão, os genomas podem ser divididos em duas classes principais: compacto e expansivo. Os primeiros são de densidade genética, com apenas cerca de 10% da região não-codificadora e estrita proporcionalidade entre o tamanho do genoma e o número do genoma. Este grupo estende-se a genomas de tamanho até cerca de 10 Mbp, cobrindo vírus, bactérias, archaea e alguns eucariotas unicelulares., A última classe não mostra nenhuma correlação clara entre o tamanho do genoma e o número do gene, é composto principalmente de elementos não codificantes e abrange todos os organismos multi-celulares.




