um método de amostragem de probabilidades é qualquer método de amostragem que utilize alguma forma de selecção aleatória. Para ter um método de seleção Aleatório, você deve configurar algum processo ou procedimento que garanta que as diferentes unidades de sua população têm probabilidades iguais de serem escolhidas. Os seres humanos há muito tempo praticam várias formas de seleção aleatória, tais como escolher um nome de um chapéu, ou escolher a palha curta. Hoje em dia, nós tendemos a usar computadores como o mecanismo para gerar números aleatórios como a base para a seleção aleatória.,
algumas definições
antes que eu possa explicar os vários métodos de probabilidade que temos de definir alguns termos básicos. Estas são:
-
Né o número de casos na amostra) -
né o número de casos na amostra -
NCn= o número de combinações (subconjuntos) dendeN -
f = n/Né a amostragem da fração
Que é isso., Com esses termos definidos podemos começar a definir os diferentes métodos de amostragem de probabilidade.
amostragem aleatória simples
a forma mais simples de amostragem aleatória é chamada amostragem aleatória simples. É complicado, não é? Aqui está a rápida descrição de amostragem aleatória simples:
- Objetivo: selecionar
nunidades deNtais que cadaNCntem uma chance igual de ser selecionado.procedimento - : Usar uma tabela de Números Aleatórios, um gerador de números aleatórios por computador, ou um dispositivo mecânico para selecionar a amostra.,
uma definição ligeiramente estilada, se exacta. Vamos ver se conseguimos torná-lo um pouco mais real.

Como selecionamos uma amostra aleatória simples? Vamos supor que estamos fazendo alguma pesquisa com uma pequena agência de serviços que deseja avaliar os pontos de vista dos clientes sobre a qualidade do serviço ao longo do último ano. Primeiro, temos de organizar a base de amostragem. Para isso, vamos ver os registos da Agência para identificar todos os clientes nos últimos 12 meses. Se tivermos sorte, a agência tem bons registos computadorizados precisos e pode rapidamente produzir essa lista., Então, temos que realmente desenhar a amostra. Decidir sobre o número de clientes que você gostaria de ter na amostra final. Para o bem do exemplo, vamos dizer que você quer selecionar 100 clientes para examinar e que havia 1000 clientes nos últimos 12 meses. Em seguida, a fração de amostragem é f = n/N = 100/1000 = .10 (ou 10%). Agora, para realmente desenhar a amostra, você tem várias opções. Podes imprimir a lista de 1000 clientes, rasgar em tiras separadas, colocar as tiras num chapéu, misturá-las bem, fechar os olhos e tirar as primeiras 100., Mas este procedimento mecânico seria tedioso e a qualidade da amostra dependeria da forma como os misturavas e da forma como os atingiste aleatoriamente. Talvez um procedimento melhor seria usar o tipo de máquina de bola que é popular com muitas das loterias do estado. Você iria precisar de três conjuntos de bolas numeradas de 0 a 9, um conjunto para cada um dos dígitos a partir de 000 999 (se não seleccionar 000 vamos chamar-se de que 1000)., Numerar a lista de nomes de 1 para 1000 e então usar a máquina de bolas para selecionar os três dígitos que selecionam cada pessoa. A desvantagem óbvia aqui é que você precisa obter as máquinas de bola. (Onde eles fazem essas coisas, afinal? Existe uma indústria de máquinas de bolas?).
nenhum destes procedimentos mecânicos é muito viável e, com o desenvolvimento de computadores baratos, há uma maneira muito mais fácil. Aqui está um procedimento simples que é especialmente útil se você tiver os nomes dos clientes já no computador., Muitos programas de computador podem gerar uma série de números aleatórios. Vamos assumir que você pode copiar e colar a lista de nomes de clientes em uma coluna em uma planilha do EXCEL. Em seguida, na coluna direita ao lado colar a função =RAND() qual é o EXCEL do modo de colocar um número aleatório entre 0 e 1 nas células. Em seguida, Ordenar ambas as colunas – a lista de nomes e o número aleatório – pelos números aleatórios. Isto reorganiza a lista em ordem aleatória do menor para o maior número aleatório., Então, tudo que você tem que fazer é pegar os primeiros cem nomes nesta lista ordenada. muito simples. Talvez consigas fazer tudo em menos de um minuto.
amostragem aleatória simples é simples de realizar e é fácil de explicar aos outros. Porque a amostragem aleatória simples é uma maneira justa para selecionar uma amostra, é razoável generalizar os resultados da amostra de volta para a população. Amostragem aleatória simples não é o método de amostragem estatisticamente mais eficiente e você pode, apenas por causa da sorte do sorteio, não obter uma boa representação dos subgrupos em uma população., Para lidar com estas questões, temos de recorrer a outros métodos de amostragem.
amostragem aleatória estratificada
amostragem aleatória estratificada, também por vezes chamada de amostragem aleatória proporcional ou quota, envolve a divisão da sua população em subgrupos homogéneos e, em seguida, a recolha de uma amostra aleatória simples em cada subgrupo. Em termos mais formais:
Existem várias razões principais pelas quais você pode preferir amostragem estratificada em vez de amostragem aleatória simples., Em primeiro lugar, garante que você será capaz de representar não só a população global, mas também subgrupos chave da população, especialmente pequenos grupos minoritários. Se você quiser ser capaz de falar sobre subgrupos, esta pode ser a única maneira eficaz de garantir que você será capaz de. Se o subgrupo for extremamente pequeno, poderá usar fracções de amostragem diferentes (f) dentro dos diferentes estratos para sobrepor aleatoriamente a amostra do pequeno grupo (embora tenha então de pesar as estimativas internas do grupo usando a fracção de amostragem sempre que quiser as estimativas globais da população)., Quando usamos a mesma fracção de amostragem dentro dos estratos estamos a realizar uma amostragem aleatória estratificada proporcional. Quando usamos diferentes frações de amostragem nos estratos, chamamos isso de amostragem aleatória estratificada desproporcional. Em segundo lugar, a amostragem aleatória estratificada terá geralmente mais precisão estatística do que a amostragem aleatória simples. Isto só será verdade se os estratos ou grupos forem homogêneos. Se forem, esperamos que a variabilidade dentro dos grupos seja menor do que a variabilidade para a população como um todo. Amostragem estratificada capitaliza sobre esse fato.,
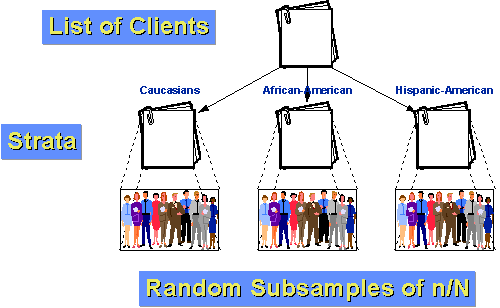
por exemplo, digamos que a população de clientes para a nossa agência pode ser dividida em três grupos: Caucasiano, afro-americano e Hispano-Americano. Além disso, vamos assumir que tanto os afro-americanos e hispânicos-americanos são minorias relativamente pequenas da clientela (10% e 5% respectivamente)., Se nós apenas fizemos uma amostra aleatória simples de n=100 com uma fração de amostragem de 10%, que seria de esperar por acaso que nós só iria ficar 10 e 5 pessoas de cada um dos nossos dois grupos menores. E, por acaso, podemos ter menos do que isso! Se nos estratificarmos, podemos fazer melhor. Primeiro, vamos determinar quantas pessoas queremos ter em cada grupo. Digamos que ainda queremos tirar uma amostra de 100 da população de 1000 clientes no último ano. Mas pensamos que para dizer alguma coisa sobre subgrupos precisaremos de pelo menos 25 casos em cada grupo., Então, vamos provar 50 caucasianos, 25 afro-americanos, e 25 hispânicos-americanos. Sabemos que 10% da população, ou 100 clientes, são afro-americanos. Se provarmos aleatoriamente 25 destes, temos uma fração de amostragem dentro do estrato de 25/100 = 25%. Da mesma forma, sabemos que 5% ou 50 clientes são hispânicos-americanos. Assim, a nossa fracção de amostragem dentro do estrato será 25/50 = 50%. Finalmente, por subtracção sabemos que existem 850 clientes caucasianos. A nossa fracção de amostragem no interior do estrato é 50/850 = about 5.88%., Como os grupos são mais homogêneos dentro do grupo do que em toda a população como um todo, podemos esperar maior precisão estatística (menos variância). E, porque nós estratificamos, sabemos que teremos casos suficientes de cada grupo para fazer inferências significativas de subgrupo.,e são os passos que você precisa seguir para conseguir uma amostra aleatória sistemática:
- número de unidades na população de
1N - decidir sobre o
n(tamanho da amostra) o que você quer ou precisa -
k = N/n= intervalo de tamanho - selecione aleatoriamente um número inteiro entre
1k - , em seguida, tomar a cada
kthunidade

Tudo isso vai ser muito mais clara com um exemplo., Vamos supor que temos uma população que só tem N=100 pessoas nela e que você quer tirar uma amostra de n=20. Para utilizar a amostragem sistemática, a população deve ser listada por ordem aleatória. A fracção de amostragem seria f = 20/100 = 20%. neste caso, o tamanho do intervalo, k, é igual a N/n = 100/20 = 5. Agora, selecione um inteiro aleatório de 1 to 5. No nosso exemplo, imagine que você escolheu 4., Agora, para selecionar a amostra, comece com o 4th unidade na lista e tome cada k-th unidade (a cada 5, porque k=5). Seriam as unidades de amostragem 4, 9, 14, 19, e assim por diante 100 e acabariam com 20 unidades na amostra.para que isto funcione, é essencial que as unidades da população sejam ordenadas aleatoriamente, pelo menos no que diz respeito às características que está a medir. Porque haverias de querer usar amostras aleatórias sistemáticas? Por um lado, é bastante fácil de fazer. Você só tem que selecionar um único número aleatório para começar as coisas., Pode também ser mais precisa do que uma simples amostragem aleatória. Finalmente, em algumas situações não há simplesmente nenhuma maneira mais fácil de fazer a amostragem aleatória. Por exemplo, uma vez tive que fazer um estudo que envolvia amostras de todos os livros de uma biblioteca. Uma vez selecionado, eu teria que ir para a prateleira, localizar o livro, e gravar quando circulou pela última vez. Eu sabia que eu tinha uma moldura de amostragem bastante boa na forma da lista de prateleira (que é um catálogo de cartão onde as entradas são organizadas na ordem que ocorrem na prateleira)., Para fazer uma amostra aleatória simples, eu poderia ter estimado o número total de livros e gerado números aleatórios para desenhar a amostra; mas como eu poderia encontrar o livro #74.329 facilmente se esse é o número que eu selecionei? Não consegui contar as cartas até chegar aos 74.329! Estratificar também não resolveria esse problema. Por exemplo, eu poderia ter estratificado pela gaveta do catálogo de cartões e ter desenhado uma amostra aleatória simples dentro de cada gaveta. Mas ainda estaria a contar cartas. Em vez disso, fiz uma amostra aleatória sistemática. Estimei o número de livros em toda a colecção. Imaginemos que eram 100 mil., Decidi que queria colher uma amostra de 1000 para uma fracção de amostragem de . Para obter o intervalo de amostragem k, dividi N/n = 100,000/1000 = 100. Então eu selecionei um inteiro aleatório entre 1 e 100. Digamos que tenho 57.em seguida, eu fiz um pequeno estudo paralelo para determinar a espessura de mil cartas no catálogo de cartas (levando em conta as diferentes idades das cartas)., Digamos que, em média, descobri que dois cartões separados por100 cartões eram cerca de.75 polegadas de diferença na gaveta do catálogo. Essa informação deu – me tudo o que precisava para tirar a amostra. Contei até o 57º à mão e registrei a informação do livro. Depois, peguei numa bússola. Lembras-te daqueles da tua aula de matemática do Liceu? São os instrumentos de metal engraçados com um alfinete pontiagudo numa ponta e um lápis na outra que costumavas desenhar círculos na aula de geometria.,) Então eu ajustei a bússola em.75", espetei a ponta do pino na 57ª carta e apontei com a ponta do lápis para a próxima carta (aproximadamente 100 livros de distância). Desta forma, eu aproximei-me de escolher o 157º, 257º, 357º, e assim por diante. Consegui realizar todo o processo de selecção em muito pouco tempo, utilizando esta abordagem sistemática de amostragem aleatória. Provavelmente ainda estaria lá a contar cartas se tivesse tentado outro método aleatório de amostragem. (OK, então eu não tenho vida. Fui bem recompensado, não me importo de dizer, por ter inventado este esquema.,)
Cluster (área) amostragem aleatória
o problema com métodos de amostragem aleatória quando temos de amostrar uma população que é desembolsada através de uma vasta região geográfica é que você terá que cobrir um monte de terreno geograficamente, a fim de chegar a cada uma das unidades que você amostrou. Imagine tirar uma amostra aleatória de todos os residentes do Estado de Nova Iorque para realizar entrevistas pessoais. Com a sorte do sorteio você vai acabar com os entrevistados que vêm de todo o estado. Os seus entrevistadores vão ter muitas viagens para fazer., Foi precisamente para este problema que foi inventada a amostragem aleatória de aglomerados ou áreas.
No cluster de amostragem, nós siga estes passos:
- dividir a população em grupos (geralmente ao longo de fronteiras geográficas)
- amostragem aleatória de clusters
- medida de todas as unidades de amostragem clusters
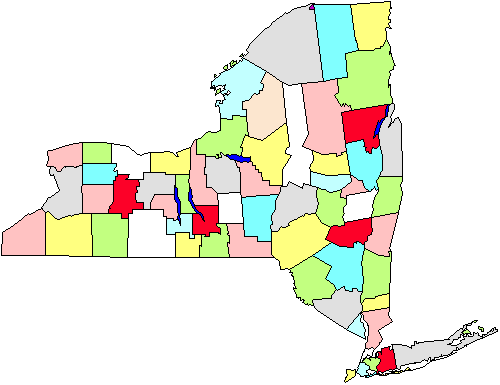
Por exemplo, na figura podemos ver um mapa dos condados do Estado de Nova York. Digamos que temos que fazer uma pesquisa sobre os governos da cidade que vai exigir que vamos às cidades pessoalmente., Se fizermos uma amostra aleatória em todo o estado, teremos de cobrir todo o estado geograficamente. Em vez disso, decidimos fazer uma amostragem em grupo de cinco condados (marcado a vermelho na figura). Uma vez que estes são selecionados, vamos a cada governo da cidade nas cinco áreas. É evidente que esta estratégia nos ajudará a economizar na nossa quilometragem. A amostragem por aglomerado ou área, então, é útil em situações como esta, e é feito principalmente para a eficiência da administração., Note também, que provavelmente não temos que nos preocupar em usar esta abordagem se estamos conduzindo uma pesquisa por correio ou telefone porque não importa tanto (ou custar mais ou aumentar a ineficiência) para onde chamamos ou enviamos cartas.
Amostragem em várias fases
os quatro métodos que cobrimos até agora – simples, estratificados, sistemáticos e cluster-são as estratégias de amostragem aleatória mais simples. Na maioria das Pesquisas Sociais Aplicadas reais, usaríamos métodos de amostragem que são consideravelmente mais complexos do que essas simples variações., O princípio mais importante aqui é que podemos combinar os métodos simples descritos anteriormente em uma variedade de maneiras úteis que nos ajudam a atender às nossas necessidades de amostragem da forma mais eficiente e eficaz possível. Quando combinamos métodos de amostragem, chamamos a isto amostragem em várias fases.por exemplo, considere a ideia de amostrar residentes do Estado de Nova Iorque para entrevistas cara-a-cara. É evidente que gostaríamos de fazer algum tipo de amostragem por aglomerado como primeira fase do processo. Podemos experimentar cidades ou censos por todo o estado., Mas na amostragem por cluster nós iríamos então para medir todos os clusters que selecionamos. Mesmo que estejamos a amostrar os recenseamentos, podemos não ser capazes de medir todos os que estão no recenseamento. Então, podemos montar um processo de amostragem estratificada dentro dos aglomerados. Neste caso, teríamos um processo de amostragem em duas fases com amostras estratificadas dentro de amostras de aglomerados. Ou, considere o problema da amostragem de estudantes em escolas primárias. Podemos começar com uma amostra nacional de distritos escolares estratificados por nível de economia e educação., Dentro de distritos seleccionados, podemos fazer uma simples amostra aleatória de escolas. Dentro das escolas, podemos fazer uma simples amostra aleatória de classes ou notas. E, dentro das aulas, podemos até fazer uma simples amostra aleatória de alunos. Neste caso, temos três ou quatro fases no processo de amostragem e usamos amostragem aleatória estratificada e simples. Combinando diferentes métodos de amostragem somos capazes de alcançar uma grande variedade de métodos de amostragem probabilísticos que podem ser usados em uma ampla gama de contextos de pesquisa social.