introdução
dados de ordenação significa organizá-lo em uma determinada ordem, muitas vezes em uma estrutura de dados tipo matriz. Você pode usar vários critérios de ordenação, sendo os comuns números de ordenação do menos para o maior ou vice-versa, ou ordenando cadeias lexicograficamente. Você pode até mesmo definir seus próprios critérios, e vamos entrar em maneiras práticas de fazer isso até o final deste artigo.,
Se você está interessado em como a ordenação funciona, vamos cobrir vários algoritmos, desde soluções ineficientes mas intuitivas, a algoritmos eficientes que são realmente implementados em Java e outras linguagens.
existem vários algoritmos de ordenação, e eles não são todos igualmente eficientes. Vamos analisar a sua complexidade de tempo para os comparar e ver quais são os melhores.,
A lista de algoritmos que você vai aprender aqui, não é, de forma exaustiva, mas reunimos alguns dos mais comuns e mais eficientes para ajudar você a começar:
- Bubble Sort
- Tipo de Inserção
- Selection Sort
- Merge Sort
- Heapsort
- Quicksort
- Classificação em Java
Nota: Este artigo não será lidar com concorrentes de classificação, já que é destinado a iniciantes.
Bubble Sort
explicação
Bubble sort funciona trocando elementos adjacentes se não estiverem na ordem desejada., Este processo se repete desde o início do array até que todos os elementos estejam em ordem.
sabemos que todos os elementos estão em ordem quando conseguimos fazer toda a iteração sem trocar nada – então todos os elementos que comparamos estavam na ordem desejada com seus elementos adjacentes, e por extensão, toda a matriz.
Aqui estão os passos para classificar uma matriz de números do menor para maior:
-
4 2 1 5 3: Os dois primeiros elementos estão na ordem errada, então nós trocá-los.
-
2 4 1 5 3: os dois segundos elementos também estão na ordem errada, por isso trocamos.,
-
2 1 4 5 3: Estes dois estão na ordem certa, 4 < 5, por isso deixamo-los em paz.
-
2 1 4 5 3: outro swap.
-
2 1 4 3 5: Aqui está a matriz resultante após uma iteração.
Porque pelo menos uma troca ocorreu durante a primeira passagem (na verdade, houve três), precisamos passar por toda a matriz novamente e repetir o mesmo processo.
repetindo este processo, até que não haja mais trocas, teremos uma matriz ordenada.,
A razão pela qual este algoritmo é chamado de Bubble Sort é porque o tipo de números de “bubble up” para a “superfície”.”Se você passar por nosso exemplo novamente, seguindo um número particular (4 é um grande exemplo), você vai vê-lo lentamente se movendo para a direita durante o processo.
Todos os números se movem para seus respectivos lugares pouco a pouco, da esquerda para a direita, como bolhas subindo lentamente de um corpo de água.se você gostaria de ler um artigo detalhado e dedicado para Bubble Sort, temos você coberto!,
implementação
vamos implementar o Bubble Sort de uma forma semelhante, que expusemos em palavras. Nossa função entra em um laço while no qual passa por toda a matriz trocando conforme necessário.
assumimos que a matriz está ordenada, mas se for provado que estamos errados durante a ordenação (se uma troca acontecer), passamos por outra iteração. O while-loop, em seguida, continua indo até que conseguimos passar através de toda a matriz sem trocar:
ao usar este algoritmo, temos que ter cuidado com a forma como declaramos a nossa condição de troca.,
Por exemplo, se eu tivesse usado a >= a ele poderia ter acabado com um loop infinito, porque para elementos iguais a essa relação seria sempre true, e, portanto, sempre trocá-los.
complexidade de tempo
para descobrir a complexidade de tempo do Bubble Sort, precisamos olhar para o pior cenário possível. Qual é o número máximo de vezes que precisamos de passar por toda a matriz antes de resolvermos isso?, Considere o seguinte exemplo:
5 4 3 2 1na primeira iteração, 5 irá “borbulhar até a superfície”, mas o resto dos elementos permaneceria em ordem descendente. Teríamos que fazer uma iteração para cada elemento exceto 1, e então outra iteração para verificar se tudo está em ordem, então um total de 5 iterações.
Expandir isso para qualquer matriz de n elementos, e isto significa que você precisa fazer n iterações., Olhando o código, o que significaria que o nosso while loop pode executar o máximo de n vezes.
cada um desses n vezes que estamos iterando através de toda a matriz (for-loop no código), o que significa que a complexidade de tempo no pior caso seria O(n^2).
nota: a complexidade de tempo seria sempre O(n^2) Se não fosse o sorted verificação booleana, que termina o algoritmo se não houver nenhum swap dentro do loop interno – o que significa que o array está ordenado.,
Insertion Sort
Explanation
a ideia por trás do Insertion Sort está dividindo o array nas subarrays ordenadas e não triadas.
a parte ordenada é de comprimento 1 no início e corresponde ao primeiro elemento (mais à esquerda) da matriz. Nós iteramos através do array e durante cada iteração, nós expandimos a porção ordenada do array por um elemento.
ao expandir – se, colocamos o novo elemento no seu lugar próprio dentro do subarray ordenado. Fazemos isso mudando todos os elementos para a direita até encontrarmos o primeiro elemento que não temos que mudar.,
Por exemplo, se na seguinte lista a parte bolded estiver ordenada por ordem ascendente, o seguinte acontece:
-
3 5 7 8 4 2 1 9 6: tiramos 4 e lembramos que é isso que precisamos inserir. Since 8 > 4, we shift.
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
3 5 7 x 8 2 1 9 6: Quando o valor de x não é de importância crucial, uma vez que será substituído imediatamente (ou por 4 Se for o seu lugar apropriado ou por 7 se mudarmos). Since 7 > 4, we shift.,
Após esse processo, os classificados parcela foi expandido por um elemento, agora temos cinco em vez de quatro elementos. Cada iteração faz isso e no final teremos todo o Conjunto resolvido.se você gostaria de ler um artigo detalhado e dedicado para Insertion Sort, temos você coberto!,
Implementation
Time Complexity
Again, we have to look at the worst case scenario for our algorithm, and it will again be the example where the whole array is descending.
isto é porque em cada iteração, teremos que mover toda a lista ordenada por um, que é O(n). Temos que fazer isso para cada elemento em cada matriz, o que significa que ele será limitado por O(n^2).
Selection Sort
Explanation
Selection Sort also divides the array into a tried and unsorted subarray., Porém, desta vez, o classificados subarray é formado por inserir o elemento mínimo da indiferenciados subarray no final do array ordenado, por troca:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
Implantação
Em cada iteração, assumimos que o primeiro não-ordenada elemento é o mínimo e iterar o resto para ver se há um menor elemento.,
Depois de encontrar o mínimo atual da indiferenciados parte da matriz, trocá-lo com o primeiro elemento e o consideram uma parte da matriz ordenada:
Tempo de Complexidade
Encontrar o mínimo é de O(n) para o comprimento da matriz, porque temos de verificar todos os elementos. Temos que encontrar o mínimo para cada elemento da matriz, fazendo todo o processo limitado por O(n^2).,
Merge Sort
explicação
Merge Sort usa recursão para resolver o problema de ordenação de forma mais eficiente do que os algoritmos anteriormente apresentados, e em particular usa uma abordagem de dividir para conquistar.
Usando ambos os conceitos, vamos quebrar a matriz inteira em duas subarrays e, em seguida:
- Tipo a metade esquerda da matriz (recursivamente)
- Tipo a metade direita da matriz (recursivamente)
- Mesclar as soluções
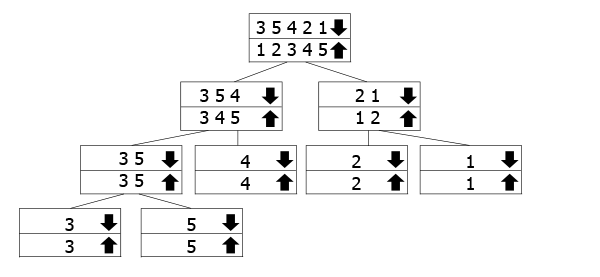
Esta árvore é utilizado para representar como as chamadas recursivas de trabalho., As matrizes marcadas com a seta para baixo são aquelas para as quais chamamos a função, enquanto estamos fundindo as Arqueiras para cima que voltam para cima. Então você segue a seta para baixo até o fundo da árvore, e então volta para cima e se funde.
No nosso exemplo, temos a matriz 3 5 3 2 1, então, divida-o em 3 5 4 e 2 1. Para separá-los, dividimo-los ainda mais em seus componentes. Assim que chegarmos ao fundo, começamos a fundir-nos e a separá-los à medida que avançamos.,se você gostaria de ler um artigo detalhado e dedicado para Merge Sort, temos você coberto!
implementação
a função principal funciona praticamente como estabelecido na explicação. Estamos apenas a passar índices left e right que são índices do elemento mais à esquerda e mais à direita do subarray que queremos classificar. Inicialmente, estes devem ser 0 e array.length-1, dependendo da implementação.,
A base da nossa recursão garante que vamos sair quando tivermos terminado, ou quando right e left conhecer uns aos outros. Encontramos um ponto médiomid, e ordenamos subarrays à esquerda e à direita dele recursivamente, em última análise, fundindo nossas soluções.
Se você se lembrar do gráfico da nossa árvore, você pode se perguntar por que não criamos duas novas matrizes menores e as passamos em seu lugar. Isto é porque em arrays realmente longos, isso causaria um enorme consumo de memória para algo que é essencialmente desnecessário.,
Merge Sort já não funciona no local por causa do passo merge, e isso só serviria para piorar sua eficiência de memória. A lógica da nossa árvore da recursão, caso contrário, permanece a mesma, no entanto, apenas temos que seguir os índices que estamos usando:
para fundir os subarrays ordenados em um, vamos precisar calcular o comprimento de cada um e fazer arrays temporários para copiá-los, para que possamos mudar livremente a nossa matriz principal.
Após copiar, passamos pela matriz resultante e atribuímos-lhe o mínimo actual., Porque a nossa subarrays são classificados, nós apenas escolher o menor dos dois elementos que ainda não foi escolhido até agora, e mover o iterador para que subarray para a frente:
Tempo de Complexidade
Se quisermos derivar a complexidade de algoritmos recursivos, vamos ter um pouco mathy.
O Teorema Mestre é usado para descobrir a complexidade de tempo de algoritmos recursivos. Para algoritmos não-recursivos, poderíamos normalmente escrever a complexidade de tempo precisa como algum tipo de equação, e então usamos notação Big-O para classificá-los em classes de algoritmos de comportamento similar.,
O problema com algoritmos recursivos é que essa mesma equação seria algo parecido com isto:
$$
T(n) = aT(\frac{n}{b}) + cn^k
$$
A equação em si é recursiva! Nesta equação, a diz-nos quantas vezes nós chamamos de recursividade, e b nos diz em quantas partes o nosso problema é dividido. Neste caso, pode parecer uma distinção sem importância porque são iguais para fusões, mas para alguns problemas podem não ser.,
O resto da equação é a complexidade de juntar todas essas soluções em uma no final., O Principal Teorema resolve esta equação para nós:
$$
T(n) = \Bigg\{
\begin{matrix}
O(n^{log_ba}), &>b^k \\ O(n^klog n), & a = b^k \\ O(n^k), & < b^k
\end{matrix}
$$
Se T(n) é o tempo de execução do algoritmo quando ordenar uma matriz de comprimento n Merge Sort seria executado duas vezes para matrizes que são metade do tamanho da matriz original.,
so if we have a=2, b=2. The merge step takes O (n) memory, so k=1. Isto significa que a equação para a Classificação em mescla ficaria da seguinte forma:
$$
T(n) = 2T(\frac{n}{2})+cn
$$
Se aplicar O Teorema Mestre, nós vamos ver que o nosso caso é aquele em que a=b^k porque temos 2=2^1. Isso significa que nossa complexidade é O (nlog n). Esta é uma complexidade de tempo extremamente boa para um algoritmo de ordenação, uma vez que foi provado que um array não pode ser ordenado mais rápido do que O(nlog n).,
embora a versão que mostramos seja consumidora de memória, existem versões mais complexas do Merge Sort que ocupam apenas O(1) espaço.
In addition, the algorithm is extremely easy to parallelize, since recursive calls from one node can be run completely independently from separate branches. Embora não vamos entrar em como e por que, como está além do escopo deste artigo, vale a pena ter em mente os prós de usar este algoritmo em particular.,
Heappsort
explicação
para entender corretamente por que o Heapsort funciona, você deve primeiro entender a estrutura em que ele é baseado – o heap. Nós estaremos falando em termos de um heap binário especificamente, mas você pode generalizar a maior parte disso para outras estruturas de heap também.
um heap é uma árvore que satisfaz a propriedade heap, que é que para cada nó, todos os seus filhos estão em uma dada relação com ele. Além disso, um monte deve estar quase completo., Uma quase completa árvore binária de profundidade d tem uma subárvore de profundidade d-1 com a mesma raiz que é completa, e em que cada nó com o botão esquerdo do descendente tem uma subárvore esquerda. Em outras palavras, ao adicionar um nó, nós sempre vamos para a posição mais à esquerda no nível mais alto incompleto.
Se o heap é um heap Max-heap, então todas as crianças são menores que o pai, e se é um heap min-heap todos eles são maiores.,
em outras palavras, à medida que você desce a árvore, você chega a números menores e menores (min-heap) ou maiores e maiores números (max-heap). Aqui está um exemplo de um max-heap:
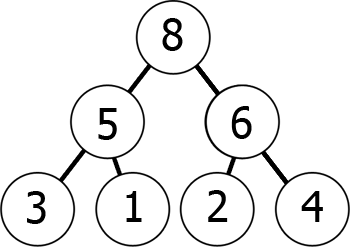
podemos representar esse max-heap de memória como uma matriz da seguinte forma:
8 5 6 3 1 2 4Você pode imaginar como a leitura do gráfico, nível por nível, da esquerda para a direita., O que nós temos conseguido com isso é que, se tomarmos o kth elemento na matriz, seus filhos posições são 2*k+1 e 2*k+2 (supondo que a indexação começa em 0). Pode verificar isto por si mesmo.
inversamente, para o elementokth a posição do pai é sempre(k-1)/2.sabendo isso, você pode facilmente “Max-heapify” qualquer matriz dada. Para cada elemento, verifique se algum dos seus filhos é menor do que ele., Se estiverem, troque um deles com o pai, e repita recursivamente este passo com o Pai (porque o novo grande elemento ainda pode ser maior do que o outro filho).
As folhas não têm filhos, por isso são trivialmente Max-heaps próprios:
-
6 1 8 3 5 2 4: ambos os filhos são menores que o pai, por isso tudo permanece o mesmo.
-
6 1 8 3 5 2 4: dado que 5 > 1, trocamo-las. Nós aumentamos recursivamente para 5 agora.
-
6 5 8 3 1 2 4: dado que 8 > 6, trocamo-los.
6 5 8 3 1 2 4: ambas as crianças são menores, por isso nada acontece.,
8 5 6 3 1 2 4: temos o Monte ilustrado acima!
Uma vez que aprendemos a aumentar um array, o resto é bastante simples. Nós trocamos a raiz do heap com o fim do array, e encurta o array por um.,
Nós heapify o reduzido matriz novamente, e repita o processo:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: trocado
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: trocado
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: trocado
E assim por diante, tenho certeza de que você pode ver o padrão emergente.
implementação
complexidade de tempo
quando olhamos para a funçãoheapify(), tudo parece ser feito em O(1), mas então há aquela chamada recursiva irritante.,
quantas vezes isso será chamado, no pior cenário? Na pior das hipóteses, vai propagar-se até ao topo da pilha. Ele fará isso saltando para o pai de cada nó, então em torno da posição i/2. isso significa que ele vai fazer no pior log n saltos antes de atingir o topo, de modo que a complexidade é O(log n).
porque heapSort() é claramente O(n) Devido à iteração de for-loops através de toda a matriz, isso faria com que a complexidade total do Heapsort O(nlog n).,
Heapsort é um tipo In-place, o que significa que leva o(1) espaço adicional, em oposição ao Merge Sort, mas também tem algumas desvantagens, como ser difícil de paralelizar.
Quicksort
explicação
Quicksort é outro algoritmo de dividir para conquistar. Ele escolhe um elemento de uma matriz como o pivô e ordena todos os outros elementos ao seu redor, por exemplo, elementos menores para a esquerda, e maiores para a direita.
isto garante que o pivô está em seu lugar próprio após o processo., Em seguida, o algoritmo recursivamente faz o mesmo para as porções esquerda e direita da matriz.
Implantação
Tempo de Complexidade
O tempo de complexidade do Quicksort pode ser expressa com a seguinte equação:
$$
T(n) = T(k) + T(n-k-1) + S(n)
$$
O cenário de pior caso é quando a maior ou menor elemento é sempre escolhido para o pivô. The equation would then look like this:
$
t (n) = T(0) + T(n-1) + O(n) = t(n-1) + O(N)
$
isto acaba por ser O(n^2).,
isto pode soar mal, uma vez que já aprendemos vários algoritmos que rodam no tempo O(nlog n) Como Seu pior caso, mas Quicksort é realmente muito amplamente utilizado.
isto é porque ele tem um tempo de execução médio realmente bom, também limitado por O(nlog n), e é muito eficiente para uma grande parte de entradas possíveis.
uma das razões pelas quais é preferível juntar o Sort é que ele não precisa de espaço extra, toda a ordenação é feita no local, e não há nenhuma alocação cara e chamadas de desalocação.,
comparação de desempenho
que tudo dito, muitas vezes é útil executar todos esses algoritmos em sua máquina algumas vezes para ter uma idéia de como eles funcionam.
eles vão atuar de forma diferente com diferentes coleções que estão sendo ordenadas, é claro, mas mesmo com isso em mente, você deve ser capaz de notar algumas tendências.
vamos executar todas as implementações, uma por uma, cada uma em uma cópia de uma matriz baralhada de 10.000 inteiros:
Podemos evidentemente ver que o Bubble Sort é o pior quando se trata de desempenho., Evite usá-lo na produção, se você não pode garantir que ele vai lidar com apenas pequenas coleções e não vai empatar a aplicação.
HeapSort e QuickSort são os melhores resultados em termos de desempenho. Embora eles estejam superando resultados semelhantes, QuickSort tende a ser um pouco melhor e mais consistente – o que confere.
ordenação em Java
Interface comparável
Se tiver os seus próprios tipos, pode tornar-se complicado implementar um algoritmo de ordenação separado para cada um. É por isso que Java fornece uma interface que lhe permite usar Collections.sort() em suas próprias classes.,
Para fazer isso, sua classe deve implementar o Comparable<T> interface, onde T é o seu tipo, e substituir um método chamado de .compareTo().
este método devolve um inteiro negativo se this for menor que o elemento argumento, 0 se forem iguais, e um inteiro positivo se this for maior.
No nosso exemplo, criamos uma classe Student, e cada aluno é identificado por uma id e um ano eles começaram seus estudos.,
queremos ordená-los, principalmente por gerações, mas também, secundariamente, pelo IDs:
E veja como usá-lo em um aplicativo:
Saída:
Comparador de Interface
Nós podemos classificar nossos objetos de uma forma pouco ortodoxa para um propósito específico, mas não queremos implementar que, como o padrão de comportamento de nossa classe, ou que poderíamos classificar de uma coleção de um tipo built-in em um local não padrão maneira.
para isso, podemos usar a interface Comparator., Por exemplo, vamos tomar o nosso Student classe e espécie apenas por ID:
Se substituir o tipo de chamada de principal, com o seguinte:
Arrays.sort(a, new SortByID());Resultado:
Como Funciona
Collection.sort() funciona chamando subjacente Arrays.sort() método, enquanto a classificação utiliza a Inserção de Classificação para matrizes menor do que 47, o Quicksort para o resto.,
é baseado em uma implementação específica de dois eixos de Quicksort que garante que evita a maioria das causas típicas de degradação em desempenho quadrático, de acordo com a documentação JDK10.
conclusão
ordenação é uma operação muito comum com conjuntos de dados, seja para analisá-los mais, acelerar a busca usando algoritmos mais eficientes que dependem dos dados a serem ordenados, filtrar dados, etc.
A ordenação é suportada por muitas línguas e as interfaces muitas vezes obscurecem o que está realmente acontecendo com o programador., Enquanto essa abstração é bem-vinda e necessária para o trabalho efetivo, às vezes, pode ser mortal para ter eficiência, e é bom saber como implementar vários algoritmos e estar familiarizados com seus prós e contras, bem como a facilidade de acesso interno implementações.