i jej implementacja w Pythonie
kod znajdziesz tutaj.
jest to ensemble tree-based learning algorithm. Random Forest Classifier to zbiór drzew decyzyjnych z losowo wybranego podzbioru zestawu treningowego. Agreguje głosy z różnych drzew decyzyjnych, aby zdecydować o ostatecznej klasie testowanego obiektu.
algorytm Ensemble:
algorytmy Ensemble to te, które łączą więcej niż jeden algorytm tego samego lub innego rodzaju do klasyfikacji obiektów. Na przykład uruchamianie predykcji nad naiwnymi Bayesami, SVM i drzewem decyzyjnym, a następnie głosowanie nad ostatecznym rozpatrzeniem klasy obiektu testowego.,

Types of Random Forest models:
1. Random Forest Prediction for a classification problem:
f(x) = majority vote of all predicted classes over B trees
2.,n :


The 9 decision tree classifiers shown above can be aggregated into a random forest ensemble which combines their input (on the right)., Poziome i pionowe osie powyższych wyjść drzewa decyzyjnego można traktować jako funkcje x1 i x2. Przy pewnych wartościach każdej funkcji drzewo decyzyjne generuje klasyfikację „niebieską”, „zieloną”, „czerwoną” itp.
powyższe wyniki są agregowane, za pomocą głosów modelowych lub uśredniania, w jeden
MODEL zespołowy, który ostatecznie przewyższa wyniki każdego indywidualnego drzewa decyzyjnego.
cechy i zalety Random Forest :
- jest to jeden z najdokładniejszych dostępnych algorytmów uczenia się. Dla wielu zestawów danych tworzy bardzo dokładny klasyfikator.,
- działa wydajnie na dużych bazach danych.
- może obsługiwać tysiące zmiennych wejściowych bez usuwania zmiennych.
- podaje oszacowania, jakie zmienne są ważne w klasyfikacji.
- generuje wewnętrzne bezstronne oszacowanie błędu uogólnienia w miarę postępu budowy lasu.
- posiada skuteczną metodę szacowania brakujących danych i utrzymuje dokładność, gdy brakuje dużej części danych.,
wady losowego lasu:
- zaobserwowano, że losowe lasy nadmiernie dopasowują się do niektórych zbiorów danych z hałaśliwymi zadaniami klasyfikacji / regresji.
- dla danych zawierających zmienne kategoryczne o różnej liczbie poziomów, losowe lasy są stronnicze na korzyść tych atrybutów o większej liczbie poziomów. W związku z tym wyniki zmiennego znaczenia z losowego lasu nie są wiarygodne dla tego typu danych.,div>
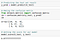
Creating a Random Forest Classification model and fitting it to the training data

Predicting the test set results and making the Confusion matrix
Conclusion :
In this blog we have learned about the Random forest classifier and its implementation., Przyjrzeliśmy się algorytmowi ensemble learning w działaniu i staraliśmy się zrozumieć, co sprawia, że Random Forest różni się od innych algorytmów uczenia maszynowego.