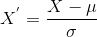Wprowadzenie do skalowania funkcji
ostatnio pracowałem z zestawem danych, który miał wiele funkcji obejmujących różne stopnie wielkości, zakresu i jednostek. Jest to istotna przeszkoda, ponieważ kilka algorytmów uczenia maszynowego jest bardzo wrażliwych na te cechy.
jestem pewien, że większość z was musiała zmierzyć się z tym problemem w swoich projektach lub swojej podróży edukacyjnej., Na przykład jedna cecha jest całkowicie w kilogramach, podczas gdy druga jest w gramach, Inna to litry i tak dalej. Jak możemy korzystać z tych funkcji, gdy różnią się tak bardzo pod względem tego, co prezentują?
tutaj zwróciłem się do koncepcji skalowania funkcji. Jest to kluczowa część etapu wstępnego przetwarzania danych, ale widziałem, że wielu początkujących przeoczyło to (ze szkodą dla ich modelu uczenia maszynowego).,

oto ciekawostka dotycząca skalowania funkcji – poprawia (znacząco) wydajność niektórych algorytmów uczenia maszynowego i w ogóle nie działa dla innych. Co może być powodem tego dziwactwa?
jaka jest różnica między normalizacją a standaryzacją? Są to dwie najczęściej używane techniki skalowania cech w uczeniu maszynowym, ale w ich rozumieniu istnieje pewien poziom niejasności. Kiedy należy użyć jakiej techniki?,
odpowiem na te pytania i więcej w tym artykule na temat skalowania funkcji. Zaimplementujemy również skalowanie funkcji w Pythonie, aby w praktyce zrozumieć, jak to działa dla różnych algorytmów uczenia maszynowego.
Uwaga: zakładam, że znasz algorytmy Pythona i core machine learning., Jeśli jesteś w tym nowy, polecam przejście przez poniższe kursy:
- Python for Data Science
- wszystkie bezpłatne kursy uczenia maszynowego przez Analytics Vidhya
- Applied Machine Learning
spis treści
- Dlaczego powinniśmy używać skalowania funkcji?
- czym jest normalizacja?
- czym jest standaryzacja?
- wielkie pytanie-normalizować czy standaryzować?,
- implementacja skalowania funkcji w Pythonie
- normalizacja przy użyciu Sklearn
- standaryzacja przy użyciu Sklearn
- zastosowanie skalowania funkcji do algorytmów uczenia maszynowego
- K-najbliżsi sąsiedzi (KNN)
- Regresor wektora wsparcia
- drzewo decyzyjne
Dlaczego powinniśmy używać skalowania funkcji?
pierwsze pytanie, którym musimy się zająć – dlaczego musimy skalować zmienne w naszym zbiorze danych? Niektóre algorytmy uczenia maszynowego są wrażliwe na skalowanie funkcji, podczas gdy inne są praktycznie niezmienne., Wyjaśnię to bardziej szczegółowo.
algorytmy oparte na obniżeniu gradientu
algorytmy uczenia maszynowego, takie jak regresja liniowa, regresja logistyczna, sieć neuronowa itp. które używają gradientu opadania jako techniki optymalizacji wymagają skalowania danych. Spójrz na formułę opadania gradientu poniżej:

obecność wartości funkcji X w formule wpłynie na rozmiar kroku opadania gradientu. Różnica w zakresach funkcji spowoduje różne rozmiary kroków dla każdej funkcji., Aby upewnić się, że opadanie gradientu przesuwa się płynnie w kierunku minima i że kroki dla opadania gradientu są aktualizowane z taką samą szybkością dla wszystkich funkcji, skalujemy dane przed przekazaniem ich do modelu.
posiadanie funkcji w podobnej skali może pomóc w szybszym zbieganiu gradientu w kierunku minima.
algorytmy oparte na odległości
algorytmy odległości, takie jak KNN, k-means I SVM, mają największy wpływ na zakres funkcji., Dzieje się tak dlatego, że za kulisami wykorzystują odległości między punktami danych w celu określenia ich podobieństwa.
na przykład, załóżmy, że mamy dane zawierające wyniki uczniów w szkole średniej CGPA (od 0 do 5) i ich przyszłe dochody (w tysiącach rupii):

ponieważ obie funkcje mają różne skale, istnieje szansa, że większa waga zostanie podana cechom o większej skali. Wpłynie to na wydajność algorytmu uczenia maszynowego i oczywiście nie chcemy, aby nasz algorytm był uprzedzony do jednej funkcji.,
dlatego skalujemy nasze dane przed zastosowaniem algorytmu opartego na odległości, aby wszystkie funkcje przyczyniały się jednakowo do wyniku.,nts A i B oraz między B I C, przed i po skalowaniu, jak pokazano poniżej:
- odległość AB przed skalowaniem =>

- odległość BC przed skalowaniem =>

- odległość ab po skalowaniu =>

- odległość BC po skalowaniu =>

skalowanie wprowadziło obie funkcje do obrazu, a odległości są teraz bardziej porównywalne niż przed zastosowaniem skalowania.,
algorytmy oparte na drzewie
algorytmy oparte na drzewie, z drugiej strony, są dość niewrażliwe na skalę funkcji. Pomyśl o tym, drzewo decyzyjne dzieli węzeł tylko na podstawie jednej funkcji. Drzewo decyzyjne dzieli węzeł na cechę, która zwiększa jednorodność węzła. Ten podział funkcji nie ma wpływu na inne funkcje.
tak więc, nie ma praktycznie żadnego wpływu pozostałych funkcji na podział. To sprawia, że są niezmienne w skali funkcji!
Co to jest normalizacja?,
normalizacja jest techniką skalowania, w której wartości są przesuwane i przeskalowane tak, że kończą się w zakresie od 0 do 1. Jest również znany jako skalowanie Min-Max.
oto wzór na normalizację:
tutaj Xmax i Xmin są wartościami maksymalnymi i minimalnymi funkcji.,
- gdy wartość X jest wartością minimalną w kolumnie, licznik będzie równy 0, a zatem X' jest 0
- z drugiej strony, gdy wartość X jest wartością maksymalną w kolumnie, licznik jest równy mianownikowi, a zatem wartość X' jest 1
- Jeśli wartość X jest między wartością minimalną a maksymalną, to wartość X' jest między 0 a 1
co jest standaryzacja?
standaryzacja jest inną techniką skalowania, w której wartości są skupione wokół średniej z jednostkowym odchyleniem standardowym., Oznacza to, że średnia atrybutu staje się zerem, a wynikowy rozkład ma jednostkowe odchylenie standardowe.
oto wzór na standaryzację:
jest średnią wartości funkcji, a
jest standardowym odchyleniem wartości funkcji. Należy pamiętać, że w tym przypadku wartości nie są ograniczone do określonego zakresu.
teraz, ważne pytanie w twoim umyśle musi być, kiedy powinniśmy używać normalizacji, a kiedy powinniśmy używać normalizacji? Przekonajmy się!,
wielkie pytanie – normalizować czy standaryzować?
normalizacja a standaryzacja to odwieczne pytanie wśród nowicjuszy uczących się maszyn. Proszę pozwolić mi rozwinąć odpowiedź w tej sekcji.
- normalizacja jest dobra do użycia, gdy wiesz, że rozkład danych nie jest zgodny z rozkładem Gaussa. Może to być przydatne w algorytmach, które nie zakładają żadnego rozkładu danych, takich jak K-najbliżsi sąsiedzi i Sieci neuronowe.
- standaryzacja, z drugiej strony, może być pomocna w przypadkach, gdy dane podążają za rozkładem Gaussa., Nie musi to jednak być koniecznie prawdą. Ponadto, w przeciwieństwie do normalizacji, standaryzacja nie ma zakresu obwiedni. Tak więc, nawet jeśli masz wartości odstające w swoich danych, nie będą one miały wpływu na standaryzację.
jednak ostatecznie wybór zastosowania normalizacji lub standaryzacji będzie zależał od problemu i używanego algorytmu uczenia maszynowego. Nie ma twardej i szybkiej reguły, która mówi ci, kiedy normalizować lub standaryzować dane., Zawsze możesz zacząć od dopasowania modelu do surowych, znormalizowanych i znormalizowanych danych i porównać wydajność, aby uzyskać najlepsze wyniki.
dobrą praktyką jest dopasowanie skalera do danych treningowych, a następnie wykorzystanie go do przekształcenia danych testowych. Pozwoli to uniknąć wycieku danych podczas procesu testowania modelu. Ponadto skalowanie wartości docelowych nie jest zwykle wymagane.
implementacja skalowania funkcji w Pythonie
teraz przychodzi zabawa – wprowadzenie tego, czego nauczyliśmy się w praktyce., Będę stosować skalowanie funkcji do kilku algorytmów uczenia maszynowego na Big Mart dataset wziąłem platformę DataHack.
pominę kroki wstępnego przetwarzania, ponieważ są one poza zakresem tego samouczka. Ale można je znaleźć starannie wyjaśnione w tym artykule. Dzięki tym krokom dotrzecie do 20 najlepszych percentyli w rankingu hackathonów, więc warto to sprawdzić!
więc najpierw Podzielmy nasze dane na zestawy treningowe i testowe:
zanim przejdziemy do części dotyczącej skalowania funkcji, spójrzmy na szczegóły dotyczące naszych danych za pomocą pd.,metoda opisz ():
widzimy, że istnieje ogromna różnica w zakresie wartości obecnych w naszych funkcjach numerycznych: Item_Visibility, Item_Weight, Item_MRP i Outlet_Establishment_Year. Spróbujmy to naprawić za pomocą skalowania funkcji!
Uwaga: zauważysz ujemne wartości w funkcji Item_Visibility, ponieważ wziąłem log-transformation, aby poradzić sobie z pochyłością w funkcji.
normalizacja korzystanie ze sklepu
aby znormalizować swoje dane, musisz zaimportować MinMaxScalar z biblioteki sklepu i zastosować go do naszego zbioru danych., Więc zróbmy to!
zobaczmy, jak normalizacja wpłynęła na nasz zbiór danych:
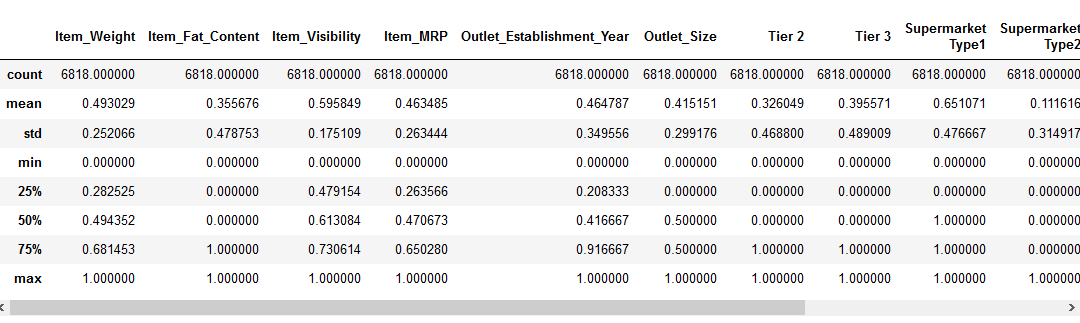
wszystkie funkcje mają teraz minimalną wartość 0 i maksymalną wartość 1. Idealnie!
Wypróbuj powyższy kod w oknie kodowania na żywo poniżej!!
następnie spróbujmy ustandaryzować nasze dane.
standaryzacja korzystanie ze sklepu
aby ujednolicić swoje dane, musisz zaimportować StandardScalar z biblioteki sklepu i zastosować go do naszego zbioru danych., Oto jak możesz to zrobić:
zauważyłbyś, że stosowałem standaryzację tylko do moich kolumn numerycznych, a nie do drugiej-Hot zakodowane funkcje. Standaryzacja funkcji zakodowanych na jednym gorąco oznaczałaby przypisanie dystrybucji do funkcji kategorycznych. Nie chcesz tego robić!
ale dlaczego nie zrobiłem tego samego podczas normalizacji danych? Ponieważ one-Hot zakodowane funkcje są już w zakresie od 0 do 1. Tak więc normalizacja nie wpłynie na ich wartość.,
przyjrzyjmy się, w jaki sposób standaryzacja zmieniła nasze dane:
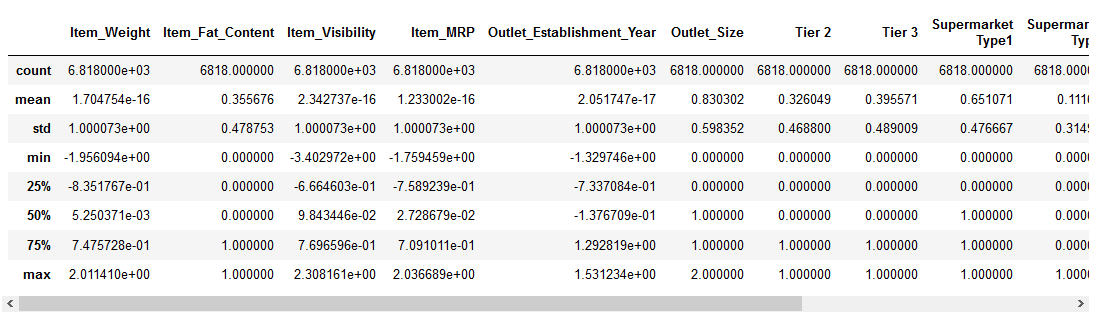
funkcje numeryczne są teraz skoncentrowane na średniej z jednostkowym odchyleniem standardowym. Super!
porównywanie bezskalowanych, znormalizowanych i znormalizowanych danych
zawsze dobrze jest wizualizować dane, aby zrozumieć obecną dystrybucję. Możemy zobaczyć porównanie naszych bezskalowanych i skalowanych danych za pomocą boxplots.
możesz dowiedzieć się więcej o wizualizacji danych tutaj.,
można zauważyć, jak skalowanie funkcji przynosi wszystko w perspektywie. Funkcje są teraz bardziej porównywalne i będą miały podobny wpływ na modele uczenia się.
zastosowanie skalowania do algorytmów uczenia maszynowego
nadszedł czas, aby wyszkolić niektóre algorytmy uczenia maszynowego na naszych danych, aby porównać wpływ różnych technik skalowania na wydajność algorytmu. Chcę zobaczyć wpływ skalowania na trzy algorytmy w szczególności: K-najbliżsi sąsiedzi, Regresor wektora wsparcia i drzewo decyzyjne.,
K-najbliżsi sąsiedzi
jak widzieliśmy wcześniej, KNN jest algorytmem opartym na odległości, na który ma wpływ zakres funkcji. Zobaczmy, jak to działa na naszych danych, przed i po skalowaniu:
widać, że skalowanie funkcji obniżyło wynik RMSE naszego modelu KNN. W szczególności znormalizowane dane działają nieco lepiej niż znormalizowane dane.
uwaga: tu mierzę RMSE, bo ten konkurs ocenia rmse.
Regresor wektora wsparcia
SVR jest kolejnym algorytmem opartym na odległości., Więc sprawdźmy, czy to działa lepiej z normalizacji lub standaryzacji:
widzimy, że skalowanie funkcji obniża wynik RMSE. A znormalizowane dane wypadły lepiej niż znormalizowane dane. Jak myślisz, dlaczego tak jest?
dokumentacja sklearn stwierdza, że SVM, z jądrem RBF, zakłada, że wszystkie funkcje są skupione wokół zera, a wariancja jest tej samej kolejności. Dzieje się tak dlatego, że cecha o wariancji większej niż innych uniemożliwia Estymator uczenia się od wszystkich cech., Świetnie!
drzewo decyzyjne
wiemy już, że drzewo decyzyjne jest niezmienne dla skalowania. Ale chciałem pokazać praktyczny przykład, jak to działa na danych:
widać, że wynik RMSE nie przesunął się o cal przy skalowaniu funkcji. Bądź więc pewny, gdy używasz algorytmów opartych na drzewie na swoich danych!,
Uwagi końcowe
w tym samouczku omówiono znaczenie stosowania skalowania funkcji na danych oraz sposób, w jaki normalizacja i standaryzacja mają różny wpływ na działanie algorytmów uczenia maszynowego
należy pamiętać, że nie ma prawidłowej odpowiedzi na pytanie, Kiedy używać normalizacji zamiast normalizacji i odwrotnie. Wszystko zależy od Twoich danych i używanego algorytmu.
w kolejnym kroku zachęcam do wypróbowania skalowania funkcji z innymi algorytmami i ustalenia, co działa najlepiej – normalizacja czy standaryzacja?, Polecam do tego celu wykorzystanie danych sprzedażowych BigMart, aby zachować ciągłość tego artykułu. I nie zapomnij podzielić się swoimi spostrzeżeniami w sekcji komentarzy poniżej!
Możesz również przeczytać ten artykuł w naszej aplikacji mobilnej