wprowadzenie
sortowanie danych oznacza uporządkowanie ich w określonej kolejności, często w strukturze danych podobnej do tablicy. Możesz użyć różnych kryteriów porządkowania, typowych dla sortowania liczb od najmniejszej do największej lub odwrotnie, lub sortowania łańcuchów leksykograficznych. Możesz nawet zdefiniować własne kryteria, a my przejdziemy do praktycznych sposobów, aby to zrobić pod koniec tego artykułu.,
Jeśli interesuje Cię, jak działa sortowanie, omówimy różne algorytmy, od nieefektywnych, ale intuicyjnych rozwiązań, po wydajne algorytmy zaimplementowane w Javie i innych językach.
istnieją różne algorytmy sortowania i nie wszystkie są równie wydajne. Będziemy analizować ich złożoność czasową, aby porównać je i zobaczyć, które z nich działają najlepiej.,
lista algorytmów, których się tutaj nauczysz, nie jest bynajmniej wyczerpująca, ale skompilowaliśmy niektóre z najczęstszych i najbardziej wydajnych algorytmów, które pomogą Ci zacząć:
- sortowanie Bąbelkowe
- sortowanie wstawiania
- sortowanie selekcji
- sortowanie scalające
- sortowanie w Javie
Uwaga: Ten artykuł nie będzie zajmuj się sortowaniem współbieżnym, ponieważ jest ono przeznaczone dla początkujących.
sortowanie Bąbelkowe
Wyjaśnienie
sortowanie Bąbelkowe działa poprzez zamianę sąsiednich elementów, jeśli nie są one w pożądanej kolejności., Proces ten powtarza się od początku tablicy, aż wszystkie elementy będą w porządku.
wiemy, że wszystkie elementy są w porządku, gdy udaje nam się wykonać całą iterację bez zamiany w ogóle – wtedy wszystkie elementy, które porównaliśmy, były w pożądanej kolejności z ich sąsiadującymi elementami, a co za tym idzie, całą tablicą.
oto kroki sortowania tablicy liczb od najmniejszej do największej:
-
4 2 1 5 3: pierwsze dwa elementy są w złej kolejności, więc zamieniamy je.
-
2 4 1 5 3: dwa drugie elementy też są w złej kolejności, więc zamieniamy.,
-
2 1 4 5 3: te dwie są w odpowiedniej kolejności, 4 < 5, więc zostawiamy je w spokoju.
-
2 1 4 5 3: kolejna Zamiana.
-
2 1 4 3 5: Oto tablica wynikowa po jednej iteracji.
ponieważ co najmniej jeden swap wystąpił podczas pierwszego przejścia (w rzeczywistości były trzy), musimy przejść przez całą tablicę ponownie i powtórzyć ten sam proces.
powtarzając ten proces, dopóki nie zostaną wykonane żadne swapy, będziemy mieli posortowaną tablicę.,
powodem, dla którego algorytm ten nazywa się sortowaniem bąbelkowym, jest to, że liczby są „bąbelkowe” do „powierzchni”.”Jeśli przejdziesz przez nasz przykład jeszcze raz, podążając za określoną liczbą (4 jest świetnym przykładem), zobaczysz, że powoli przesuwa się ona w prawo podczas procesu.
wszystkie liczby przesuwają się w odpowiednie miejsca, krok po kroku, od lewej do prawej, jak bąbelki powoli wyrastające z wody.
Jeśli chcesz przeczytać szczegółowy, dedykowany artykuł do sortowania Bubble, mamy dla ciebie!,
implementacja
zamierzamy zaimplementować sortowanie bąbelkowe w podobny sposób, jaki określiliśmy słowami. Nasza funkcja wchodzi w pętlę while, w której przechodzi przez całą zamianę tablicy w razie potrzeby.
Zakładamy, że tablica jest posortowana, ale jeśli okaże się, że się mylimy podczas sortowania (jeśli nastąpi Zamiana), przechodzimy przez kolejną iterację. Pętla while będzie działać, dopóki nie uda nam się przejść przez całą tablicę bez zamiany:
używając tego algorytmu musimy być ostrożni w jaki sposób określamy nasz warunek zamiany.,
na przykład, gdybym użył a >= ato mogłoby skończyć się nieskończoną pętlą, ponieważ dla równych elementów ta relacja zawsze byłaby true I dlatego zawsze je zamieniać.
złożoność czasu
aby obliczyć złożoność czasu sortowania bąbelków, musimy przyjrzeć się najgorszemu możliwemu scenariuszowi. Jaka jest maksymalna liczba razy, jaką musimy przejść przez całą tablicę, zanim ją posortujemy?, Rozważ następujący przykład:
5 4 3 2 1w pierwszej iteracji 5 będzie „bańka aż do powierzchni”, ale reszta elementów pozostanie w porządku malejącym. Musimy zrobić jedną iterację dla każdego elementu z wyjątkiem 1, a następnie kolejną iterację, aby sprawdzić, czy wszystko jest w porządku, więc w sumie 5 iteracji.
rozwiń to do dowolnej tablicyn elementów, a to oznacza, że musisz wykonaćn iteracji., Patrząc na kod, oznaczałoby to, że nasza while pętla może uruchomić maksymalnie n razy.
każdy z tychn razy iterujemy przez całą tablicę (for-loop w kodzie), co oznacza, że najgorszą złożonością czasu będzie O(N^2).
Uwaga: złożoność czasowa byłaby zawsze O (N^2), gdyby nie sprawdzanie logiczne sorted, które kończy algorytm, jeśli nie ma żadnych swapów w wewnętrznej pętli – co oznacza, że tablica jest posortowana.,
sortowanie wstawiania
Wyjaśnienie
idea sortowania wstawiania polega na podzieleniu tablicy na posortowane i niesortowane podprogramy.
posortowana część ma długość 1 na początku i odpowiada pierwszemu (najbardziej lewy) elementowi w tablicy. Przechodzimy przez tablicę i podczas każdej iteracji rozszerzamy posortowaną część tablicy o jeden element.
po rozwinięciu, umieszczamy nowy element we właściwym miejscu w posortowanym podkładzie. Robimy to, przesuwając wszystkie elementy w prawo, dopóki nie napotkamy pierwszego elementu, którego nie musimy przesuwać.,
na przykład, jeśli w poniższej tablicy pogrubiona część jest sortowana w porządku rosnącym, następuje:
-
3 5 7 8 4 2 1 9 6: bierzemy 4 i pamiętamy, że to jest to, co musimy wstawić. Od 8 > 4 zmieniamy.
-
3 5 7 x 8 2 1 9 6: gdzie wartość x nie ma kluczowego znaczenia, ponieważ zostanie natychmiast nadpisana (albo przez 4, jeśli jest to jego właściwe miejsce, albo przez 7, jeśli przesuniemy). Od 7 > 4 zmieniamy.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Po tym procesie posortowana część została rozszerzona o jeden element, teraz mamy pięć, a nie cztery elementy. Każda iteracja robi to i na koniec będziemy mieli całą tablicę posortowaną.
Jeśli chcesz przeczytać szczegółowy, dedykowany artykuł do sortowania wstawiania, mamy dla ciebie!,
implementacja
złożoność czasowa
ponownie musimy spojrzeć na najgorszy scenariusz dla naszego algorytmu i ponownie będzie to przykład, w którym cała tablica maleje.
dzieje się tak dlatego, że w każdej iteracji będziemy musieli przenieść całą posortowaną listę o jeden, czyli O (n). Musimy to zrobić dla każdego elementu w każdej tablicy, co oznacza, że będzie ograniczony przez O (N^2).
sortowanie selekcji
Wyjaśnienie
sortowanie selekcji dzieli również tablicę na posortowane i niesortowane podarray., Jednak, tym razem, posortowana tablica podrzędna jest tworzona przez wstawienie minimalnego elementu niesortowanej tablicy podrzędnej na końcu posortowanej tablicy, poprzez zamianę:
-
3 5 1 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
implementacja
w każdej iteracji zakładamy, że pierwszy nieposortowany element jest minimum i powtarzamy przez resztę, aby sprawdzić, czy istnieje mniejszy element.,
gdy znajdziemy bieżące minimum niesortowanej części tablicy, zamieniamy je na pierwszy element i uznajemy za część posortowanej tablicy:
złożoność czasu
znalezienie minimum to O(n) dla długości tablicy, ponieważ musimy sprawdzić wszystkie elementy. Musimy znaleźć minimum dla każdego elementu tablicy, czyniąc cały proces ograniczony przez O (n^2).,
sortowanie scalające
Wyjaśnienie
sortowanie scalające wykorzystuje rekurencję, aby rozwiązać problem sortowania bardziej efektywnie niż algorytmy wcześniej przedstawione, a w szczególności wykorzystuje podejście dzielenie i podbijanie.
używając obu tych pojęć, podzielimy całą tablicę na dwie podparyski, a następnie:
- posortujemy lewą połowę tablicy (rekurencyjnie)
- posortujemy prawą połowę tablicy (rekurencyjnie)
- Scalimy rozwiązania
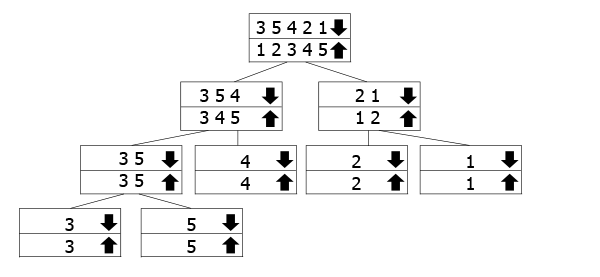
To drzewo ma reprezentować sposób, w jaki wywołania rekurencyjne działają., Tablice oznaczone strzałką w dół to te, dla których wywołujemy funkcję, podczas gdy łączymy te ze strzałkami w górę, które wracają do góry. Więc podążasz za strzałką w dół do dolnej części drzewa, a następnie wróć do góry i połącz się.
w naszym przykładzie mamy tablicę 3 5 3 2 1, więc dzielimy ją na 3 5 4I 2 1. Aby je posortować, dalej dzielimy je na ich składniki. Gdy dotrzemy do dna, zaczynamy łączyć się i sortować je.,
Jeśli chcesz przeczytać szczegółowy, dedykowany artykuł do sortowania scalonego, mamy dla ciebie!
implementacja
podstawowa funkcja działa prawie tak, jak opisano w wyjaśnieniu. Po prostu przechodzimy indeksy leftIright, które są indeksami lewego i prawego elementu podrzędnego, który chcemy sortować. Początkowo powinny to być 0 I array.length-1, w zależności od implementacji.,
baza naszej rekurencji zapewnia wyjście po zakończeniu, lub gdyright Ileft spotykają się ze sobą. Znajdujemy punkt środkowy mid I sortujemy podpunkty z lewej i prawej strony rekurencyjnie, ostatecznie łącząc nasze rozwiązania.
Jeśli pamiętasz naszą grafikę drzewa, możesz się zastanawiać, dlaczego nie utworzymy dwóch nowych mniejszych tablic i nie przekażemy ich dalej. Dzieje się tak, ponieważ na naprawdę długich tablicach spowodowałoby to ogromne zużycie pamięci dla czegoś, co jest zasadniczo niepotrzebne.,
sortowanie scalające już nie działa na miejscu ze względu na etap scalania, a to tylko pogorszyłoby jego wydajność pamięci. Logika naszego drzewa rekursji w przeciwnym razie pozostaje taka sama, ale musimy podążać za indeksami, których używamy:
aby scalić posortowane podprzestrzenie w jeden, musimy obliczyć długość każdego z nich i utworzyć tymczasowe tablice, aby je skopiować, abyśmy mogli dowolnie zmieniać naszą główną tablicę.
po skopiowaniu przechodzimy przez wynikową tablicę i przypisujemy jej bieżące minimum., Ponieważ nasze podprogramy są posortowane, wybraliśmy mniejszy z dwóch elementów, które nie zostały wybrane do tej pory, i przenieś iterator dla tego podprogramu do przodu:
złożoność czasowa
Jeśli chcemy uzyskać złożoność algorytmów rekurencyjnych, będziemy musieli trochę mathy.
The Master Theorem is used to figure out time complexity of recursive algorithms. W przypadku nie-rekurencyjnych algorytmów, zwykle możemy zapisać dokładną złożoność czasu jako jakiś rodzaj równania, a następnie używamy notacji Big-O do sortowania ich w klasy podobnie zachowujących się algorytmów.,
problem z algorytmami rekurencyjnymi polega na tym, że to samo równanie wyglądałoby mniej więcej tak:
$$
t(n) = aT(\frac{n}{B}) + cn^k
$$
samo równanie jest rekurencyjne! W tym równaniu amówi nam, ile razy wywołujemy rekurencję, ab mówi nam, na ile części nasz problem jest podzielony. W tym przypadku może się to wydawać nieistotnym rozróżnieniem, ponieważ są równe dla mergesort, ale dla niektórych problemów mogą nie być.,
reszta równania to złożoność połączenia wszystkich tych rozwiązań w jedno na końcu., The Master Theorem rozwiązuje to równanie dla nas:
$$
T(N) = \Bigg\{
\begin{matrix}
O(N^{log_ba}), & a>b^k \\ O(N^klog n), & a = b^k \\ o(n^k), & a < b^k
\End{matrix}
$$
Jeśli T(n) jest uruchomieniem algorytmu podczas sortowania tablica o długości n, sortowanie scalające będzie uruchamiane dwukrotnie dla tablic o połowie długości oryginalnej tablicy.,
więc jeśli mamy a=2, b=2. Krok scalania zajmuje pamięć o (n), więc k=1. Oznacza to, że równanie dla sortowania scalonego wyglądałoby następująco:
$$
t(n) = 2T(\frac{n}{2})+cn
$$
Jeśli zastosujemy twierdzenie główne, zobaczymy, że nasz przypadek jest taki, w którym a=b^k ponieważ mamy 2=2^1. Oznacza to, że nasza złożoność to O (nlog n). Jest to bardzo dobra złożoność czasowa dla algorytmu sortowania, ponieważ udowodniono, że tablica nie może być sortowana szybciej niż O (nlog n).,
chociaż wersja, którą zaprezentowaliśmy, pochłania pamięć, istnieją bardziej złożone wersje sortowania scalającego, które zajmują tylko O(1) miejsce.
ponadto algorytm jest niezwykle łatwy do równoległego zestawiania, ponieważ rekurencyjne wywołania z jednego węzła mogą być uruchamiane całkowicie niezależnie od oddzielnych gałęzi. Chociaż nie będziemy się zastanawiać, jak i dlaczego, ponieważ wykracza to poza zakres tego artykułu, warto pamiętać o zaletach korzystania z tego konkretnego algorytmu.,
Heapsort
Wyjaśnienie
aby prawidłowo zrozumieć, dlaczego Heapsort działa, musisz najpierw zrozumieć strukturę, na której się opiera – stertę. Będziemy mówić konkretnie o stercie binarnej, ale większość tego można uogólnić również na inne struktury sterty.
sterta jest drzewem, które spełnia właściwość sterty, która polega na tym, że dla każdego węzła wszystkie jego dzieci są w danej relacji do niego. Dodatkowo sterta musi być prawie kompletna., Prawie kompletne binarne drzewo głębokości d ma podzbiór głębokości d-1 z tym samym korzeniem, który jest kompletny, i w którym każdy węzeł z lewym potomkiem ma kompletny lewy podzbiór. Innymi słowy, gdy dodajemy węzeł, zawsze wybieramy pozycję po lewej stronie na najwyższym niepełnym poziomie.
Jeśli sterta jest stertą max, to wszystkie dzieci są mniejsze od rodzica, a jeśli jest to sterta min, wszystkie są większe.,
innymi słowy, gdy poruszasz się w dół drzewa, dostajesz mniejsze i mniejsze liczby (min-heap) lub większe i większe liczby (max-heap). Oto przykład max-heap:
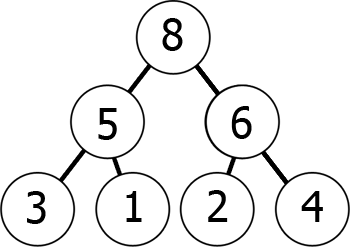
możemy reprezentować ten Max-heap w pamięci jako tablicę w następujący sposób:
8 5 6 3 1 2 4można go wyobrazić sobie jako odczyt z poziomu wykresu po poziomie, od lewej do prawej., To, co udało nam się osiągnąć, to to, że jeśli weźmiemy element kth w tablicy, jego pozycje potomne to 2*k+1 I 2*k+2 (zakładając, że indeksowanie zaczyna się od 0). Sam możesz to sprawdzić.
odwrotnie, dla elementukth pozycja rodzica jest zawsze (k-1)/2.
wiedząc o tym, możesz łatwo „max-heapify” dowolnej podanej tablicy. Dla każdego elementu sprawdź, czy któreś z jego dzieci jest od niego mniejsze., Jeśli tak, zamień jeden z nich na rodzica i rekurencyjnie powtórz ten krok z rodzicem (ponieważ nowy duży element może być większy niż jego drugi potomek).
liście nie mają dzieci, więc są trywialnie małe:
-
6 1 8 3 5 2 4: oba dzieci są mniejsze od rodzica, więc wszystko pozostaje takie samo.
-
6 1 8 3 5 2 4: Ponieważ 5 > 1, zamieniamy je. Rekurencyjnie gromadzimy teraz 5.
-
6 5 8 3 1 2 4: obie dzieci są mniejsze, więc nic się nie dzieje.,
-
6 5 8 3 1 2 4: Ponieważ 8 > 6, zamieniamy je.
-
8 5 6 3 1 2 4: mamy stertę na zdjęciu powyżej!
gdy nauczymy się układać tablicę, reszta jest dość prosta. Zamieniamy korzeń sterty na koniec tablicy i skracamy tablicę o jeden.,
ponownie ustawiamy skróconą tablicę i powtarzamy proces:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: Wymiana
-
6 5 4 3 1 2 8: Wymiana
-
2 5 4 3 1 6 8: Wymiana
-
5 2 4 2 1 6 8: Wymiana
-
1 2 4 2 5 6 8: Wymiana
i tak dalej, jestem pewien, że widać wyłaniający się wzór.
implementacja
złożoność czasu
kiedy spojrzymy na funkcję heapify(), wszystko wydaje się być zrobione w O(1), ale wtedy pojawia się to brzydkie wywołanie rekurencyjne.,
ile razy będzie to wywoływane, w najgorszym przypadku? W najgorszym wypadku będzie się rozprzestrzeniać aż na sam szczyt sterty. Zrobi to, przeskakując do rodzica każdego węzła, więc wokół pozycji i/2. oznacza to, że w najgorszym przypadku log N skoczy zanim osiągnie szczyt, więc złożoność wynosi O (log n).
ponieważheapSort() jest wyraźnie O(N) ze względu na iterację pętli for przez całą tablicę, spowodowałoby to całkowitą złożoność Heapsort O(nlog n).,
Heapsort jest sortowaniem w miejscu, co oznacza, że zajmuje O(1) dodatkowe miejsce, w przeciwieństwie do sortowania scalającego, ale ma również pewne wady, takie jak trudności w równoległym porównywaniu.
Quicksort
Wyjaśnienie
Quicksort to kolejny algorytm dzielenia i zdobywania. Wybiera jeden element tablicy jako pivot i sortuje wszystkie inne elementy wokół niego, na przykład mniejsze elementy po lewej, a większe po prawej.
gwarantuje to, że pivot znajduje się we właściwym miejscu po zakończeniu procesu., Następnie algorytm rekurencyjnie robi to samo dla lewej i prawej części tablicy.
implementacja
złożoność czasowa
złożoność czasowa Quicksort może być wyrażona następującym równaniem:
$$
t(n) = t(k) + t(n-k-1) + O(N)
$$
najgorszy scenariusz jest wtedy, gdy największy lub najmniejszy element jest zawsze wybrany dla Pivota. Równanie wyglądałoby wtedy następująco:
$$
T(n) = T(0) + T(N-1) + O(n) = T(N-1) + O(N)
$$
okazuje się, że jest to O(N^2).,
może to zabrzmieć źle, ponieważ nauczyliśmy się już wielu algorytmów, które działają w czasie O(nlog n) jako ich najgorszy przypadek, ale Quicksort jest w rzeczywistości bardzo szeroko stosowany.
dzieje się tak dlatego, że ma naprawdę dobry średni czas działania, również ograniczony Przez O(nlog n) i jest bardzo wydajny dla dużej części możliwych wejść.
jednym z powodów, dla których preferowane jest scalanie sortowania jest to, że nie zajmuje ono dodatkowego miejsca, Całe sortowanie odbywa się na miejscu i nie ma kosztownych wywołań alokacji i dealokacji.,
porównanie wydajności
to wszystko jest powiedziane, że często warto uruchomić wszystkie te algorytmy na komputerze kilka razy, aby dowiedzieć się, jak działają.
będą działać inaczej z różnymi kolekcjami, które są oczywiście sortowane, ale nawet mając to na uwadze, powinieneś być w stanie zauważyć pewne trendy.
Uruchom wszystkie implementacje, jedna po drugiej, każda na kopii tasowanej tablicy 10 000 liczb całkowitych:
widać wyraźnie, że sortowanie bąbelków jest najgorsze, jeśli chodzi o wydajność., Unikaj używania go w produkcji, jeśli nie możesz zagwarantować, że będzie obsługiwał tylko małe kolekcje i nie opóźni aplikacji.
HeapSort i QuickSort są najlepsze pod względem wydajności. Chociaż dają podobne wyniki, QuickSort wydaje się być nieco lepszy i bardziej spójny – co się sprawdza.
sortowanie w Javie
porównywalny interfejs
Jeśli masz własne typy, może to być kłopotliwe implementowanie oddzielnego algorytmu sortowania dla każdego z nich. Dlatego Java zapewnia interfejs pozwalający na używanie Collections.sort() na własnych klasach.,
aby to zrobić, twoja klasa musi zaimplementować interfejs Comparable<T>, gdzie T jest twoim typem i nadpisać metodę o nazwie .compareTo().
ta metoda zwraca ujemną liczbę całkowitą, jeśli thisjest mniejsza niż element argumentu, 0 jeśli są równe, a dodatnia liczba całkowita, jeślithis jest większa.
w naszym przykładzie stworzyliśmy klasę Student, a każdy uczeń jest identyfikowany przez id I rok, w którym rozpoczął naukę.,
chcemy sortować je przede wszystkim po pokoleniach, ale także po IDs:
i oto jak go używać w aplikacji:
Wyjście:
interfejs porównawczy
możemy chcieć sortować nasze obiekty w niekonwencjonalny sposób dla określonego celu, ale nie chcemy implementować tego jako domyślnego zachowania naszej klasy, lub możemy sortować kolekcję wbudowanego typu w sposób niestandardowy.
w tym celu możemy użyć interfejsu Comparator., Na przykład, weźmy naszą klasę Student I Sortuj tylko według ID:
Jeśli zamienimy wywołanie sortowania w main na następujące:
Arrays.sort(a, new SortByID());Wyjście:
Jak to wszystko działa
Collection.sort() działa poprzez wywołanie podstawowej metody Arrays.sort(), podczas gdy samo sortowanie używa sortowania wstawiania dla tablic krótszych niż 47, a quicksort dla reszty.,
opiera się na specyficznej, dwu-obrotowej implementacji Quicksort, która zapewnia uniknięcie większości typowych przyczyn degradacji do wydajności kwadratowej, zgodnie z dokumentacją JDK10.
podsumowanie
sortowanie jest bardzo powszechną operacją w zestawach danych, czy to w celu ich dalszej analizy, przyspieszenia wyszukiwania przy użyciu bardziej wydajnych algorytmów, które polegają na sortowaniu danych, filtrowaniu danych itp.
sortowanie jest obsługiwane przez wiele języków, a Interfejsy często zaciemniają, co naprawdę dzieje się z programistą., Chociaż ta abstrakcja jest mile widziana i niezbędna do efektywnej pracy, czasami może być zabójcza dla wydajności i dobrze jest wiedzieć, jak wdrażać różne algorytmy i znać ich wady i zalety, a także jak łatwo uzyskać dostęp do wbudowanych implementacji.