en de implementatie in Python
In deze blog ‘proberen om dieper te graven in het Random Forest Taxonomie. Hier zullen we leren over ensemble leren en zullen proberen om het te implementeren met behulp van Python.,
u kunt de code hier vinden.
het is een ensemble-boom-gebaseerd leeralgoritme. De Random Forest Classifier is een verzameling beslissingsbomen uit willekeurig geselecteerde deelverzameling van trainingsset. Het aggregeert de stemmen van verschillende besluit bomen om de uiteindelijke klasse van het testobject te beslissen.
Ensemblealgoritme:
Ensemblealgoritmen zijn algoritmen die meerdere algoritmen van dezelfde of verschillende aard combineren voor het classificeren van objecten. Bijvoorbeeld, het uitvoeren van voorspelling over naïeve Bayes, SVM en besluit boom en vervolgens het nemen van de stemming voor de laatste overweging van de klasse voor testobject.,

Types of Random Forest models:
1. Random Forest Prediction for a classification problem:
f(x) = majority vote of all predicted classes over B trees
2.,n :


The 9 decision tree classifiers shown above can be aggregated into a random forest ensemble which combines their input (on the right)., De horizontale en verticale assen van de bovenstaande decision tree uitgangen kunnen worden gezien als functies x1 en x2. Bij bepaalde waarden van elk kenmerk geeft de beslissingsboom een classificatie van “blauw”, “groen”, “rood”, enz.
Deze bovenstaande resultaten worden geaggregeerd, door middel van modelstemmen of gemiddelden, in een enkel
ensemblemodel dat de output van een individuele beslissingsboom overtreft.
Kenmerken en voordelen van Random Forest :
- Het is een van de meest accurate leeralgoritmen die beschikbaar zijn. Voor veel datasets produceert het een zeer nauwkeurige classifier.,
- het werkt efficiënt op grote databases.
- het kan duizenden invoervariabelen verwerken zonder variabele deletie.
- het geeft schattingen van welke variabelen belangrijk zijn in de classificatie.
- het genereert een interne onbevooroordeelde schatting van de generalisatiefout naarmate het forest-gebouw vordert.
- het heeft een effectieve methode voor het schatten van ontbrekende gegevens en behoudt de nauwkeurigheid wanneer een groot deel van de gegevens ontbreekt.,
nadelen van Random Forest:
- Er is waargenomen dat Random forests overbezet zijn voor sommige datasets met lawaaierige classificatie – / regressietaken.
- Voor gegevens met inbegrip van categorische variabelen met een verschillend aantal niveaus, worden willekeurige forests bevooroordeeld ten gunste van die attributen met meer niveaus. Daarom zijn de variabele belangsscores van willekeurig forest niet betrouwbaar voor dit type gegevens.,div>
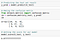
Creating a Random Forest Classification model and fitting it to the training data

Predicting the test set results and making the Confusion matrix
Conclusion :
In this blog we have learned about the Random forest classifier and its implementation., We keken naar het ensembled learning algoritme in actie en probeerden te begrijpen wat Random Forest anders maakt van andere machine learning algoritmen.