Introduction
Sorteerdata betekent het rangschikken in een bepaalde volgorde, vaak in een array – achtige datastructuur. U kunt verschillende ordercriteria gebruiken, gemeenschappelijke zijn het sorteren van nummers van minst naar Grootste of vice versa, of het sorteren van strings lexicografisch. U kunt zelfs uw eigen criteria te definiëren, en we zullen gaan in praktische manieren om dat te doen tegen het einde van dit artikel.,
Als u geïnteresseerd bent in hoe Sorteren werkt, behandelen we verschillende algoritmen, van inefficiënte maar intuïtieve oplossingen tot efficiënte algoritmen die daadwerkelijk worden geïmplementeerd in Java en andere talen.
Er zijn verschillende sorteeralgoritmen, en ze zijn niet allemaal even efficiënt. We zullen hun tijdscomplexiteit analyseren om ze te vergelijken en te zien welke het beste presteren.,
De lijst van algoritmen je leert hier is niet uitputtend, maar we hebben samengesteld een aantal van de meest voorkomende en meest efficiënte systemen om u te helpen de slag te gaan:
- Bubble Sort
- Insertion Sort
- Selectie Sorteren
- Merge Sort
- Heapsort
- Quicksort
- Sorteren in Java
Opmerking: in Dit artikel zal niet te maken hebben met gelijktijdige sorteren, want het is bedoeld voor beginners.
Bubble Sort
uitleg
Bubble sort werkt door aangrenzende elementen te verwisselen als ze niet in de gewenste volgorde staan., Dit proces herhaalt zich vanaf het begin van de array totdat alle elementen in orde zijn.
we weten dat alle elementen in orde zijn als we erin slagen om de hele iteratie te doen zonder te wisselen – dan waren alle elementen die we vergeleken in de gewenste volgorde met hun aangrenzende elementen, en bij uitbreiding, de hele array.
Hier zijn de stappen voor het sorteren van een array van getallen van minst naar grootste:
-
4 2 1 5 3: De eerste twee elementen staan in de verkeerde volgorde, dus we wisselen ze om.
-
2 4 1 5 3: De tweede twee elementen staan ook in de verkeerde volgorde, dus we wisselen.,
-
2 1 4 5 3: Deze twee zijn in de juiste volgorde, 4 < 5, dus we laten ze met rust.
-
2 1 4 5 3: een andere swap.
-
2 1 4 3 5: Hier is de resulterende array na één iteratie.
omdat er minstens één swap plaatsvond tijdens de eerste pass (er waren er eigenlijk drie), moeten we de hele array opnieuw doorlopen en hetzelfde proces herhalen.
door dit proces te herhalen, totdat er geen swaps meer worden gemaakt, hebben we een gesorteerde array.,
De reden dat dit algoritme Bubble Sort wordt genoemd is omdat de getallen een soort van” bubble up “naar het” oppervlak.”Als je ons voorbeeld nog eens doorneemt en een bepaald getal volgt (4 is een geweldig voorbeeld), zie je het langzaam naar rechts bewegen tijdens het proces.
alle getallen bewegen beetje bij beetje naar hun respectievelijke plaatsen, van links naar rechts, zoals bubbels die langzaam opstijgen uit een waterlichaam.
Als u een gedetailleerd, speciaal artikel voor Bubble Sort wilt lezen, dan hebben we het voor u!,
implementatie
We gaan Bubble Sort implementeren op dezelfde manier als we het in woorden hebben uitgelegd. Onze functie komt in een while lus waarin het door de gehele array swapping gaat als dat nodig is.
We gaan ervan uit dat de array gesorteerd is, maar als het fout is bewezen tijdens het sorteren (als er een swap gebeurt), gaan we door een andere iteratie. De while-lus blijft dan doorgaan totdat we erin slagen om door de hele array te gaan zonder te ruilen:
wanneer we dit algoritme gebruiken moeten we voorzichtig zijn hoe we onze swap conditie aangeven.,
bijvoorbeeld, als ik a >= a had gebruikt, had het kunnen eindigen met een oneindige lus, omdat voor gelijke elementen deze relatie altijd true zou zijn, en ze dus altijd omwisselen.
tijdcomplexiteit
om de tijdcomplexiteit van de Bubble-sortering te achterhalen, moeten we naar het slechtst mogelijke scenario kijken. Wat is het maximum aantal keren dat we door de hele reeks moeten gaan voordat we het gesorteerd hebben?, Neem het volgende voorbeeld:
5 4 3 2 1in de eerste iteratie zal 5″ bubble up to the surface, ” maar de rest van de elementen zou blijven in aflopende volgorde. We zouden één iteratie moeten doen voor elk element behalve 1, en dan nog een iteratie om te controleren of alles in orde is, dus in totaal 5 iteraties.
breid dit uit naar elke array van n elementen, en dat betekent dat u n iteraties moet doen., Kijkend naar de code, zou dat betekenen dat onze while lus het maximum van n keer kan draaien.
elk van deze n keer dat we itereren door de hele array (for-loop in de code), wat betekent dat de slechtste tijd complexiteit O(n^2) zou zijn.
Opmerking: De tijdscomplexiteit zou altijd o (n^2) zijn zonder de sorted Booleaanse controle, die het algoritme beëindigt als er geen swaps zijn binnen de binnenste lus – wat betekent dat de array gesorteerd is.,
Invoegsoort
uitleg
het idee achter Invoegsoort is het verdelen van de array in gesorteerde en ongesorteerde subarrays.
Het gesorteerde deel is van lengte 1 Aan het begin en komt overeen met het eerste (meest linkse) element in de array. We herhalen door de array en tijdens elke iteratie breiden we het gesorteerde gedeelte van de array uit met één element.
bij het uitbreiden plaatsen we het nieuwe element op zijn juiste plaats binnen de gesorteerde subarray. We doen dit door alle elementen naar rechts te verschuiven totdat we het eerste element tegenkomen dat we niet hoeven te verschuiven.,
bijvoorbeeld, als in de volgende array het vetgedrukte deel in oplopende volgorde gesorteerd wordt, gebeurt het volgende:
-
3 5 7 8 4 2 1 9 6: We nemen 4 en onthouden dat dat is wat we moeten invoegen. Sinds 8 > 4, verschuiven we.
-
3 5 7 x 8 2 1 9 6: waarbij de waarde van x niet van cruciaal belang is, aangezien deze onmiddellijk zal worden overschreven (hetzij met 4 als het de juiste plaats is, hetzij met 7 als we verschuiven). Sinds 7 > 4, verschuiven we.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Na dit proces werd het gesorteerde gedeelte uitgebreid met één element, we hebben nu vijf in plaats van vier elementen. Elke iteratie doet dit en tegen het einde hebben we de hele array gesorteerd.
Als u een gedetailleerd, speciaal artikel wilt lezen voor het sorteren van invoegtoepassingen, dan hebben we het voor u!,
implementatie
tijdscomplexiteit
opnieuw moeten we kijken naar het slechtste scenario voor ons algoritme, en het zal opnieuw het voorbeeld zijn waar de hele array afdaalt.
Dit komt omdat we in elke iteratie de hele gesorteerde lijst met één moeten verplaatsen, Wat O(n) is. We moeten dit doen voor elk element in elke array, wat betekent dat het wordt begrensd door O (n^2).
selectie Sorteren
uitleg
selectie Sorteren verdeelt ook de array in een gesorteerde en ongesorteerde subarray., Hoewel, dit keer de gesorteerde subarray wordt gevormd door het invoegen van het minimale element van het ongesorteerde subarray aan het einde van het gesorteerde array, door het swappen van:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
Implementatie
In elke iteratie, nemen we aan dat de eerste ongesorteerd element is de minimale en doorloop de rest om te zien of er een kleiner element.,
zodra we het huidige minimum van het ongesorteerde deel van de array vinden, ruilen we het met het eerste element en beschouwen het als een deel van de gesorteerde array:
tijdscomplexiteit
het vinden van het minimum is O(n) voor de lengte van de array omdat we alle elementen moeten controleren. We moeten het minimum voor elk element van de array vinden, waardoor het hele proces begrensd wordt door O (n^2).,
Merge Sort
uitleg
Merge Sort gebruikt recursie om het probleem van Sorteren efficiënter op te lossen dan algoritmen eerder gepresenteerd, en in het bijzonder gebruikt het een verdeel en heers benadering.
met beide concepten splitsen we de hele array op in twee subarrays en dan:
- Sorteer de linkerhelft van de array (recursief)
- Sorteer de rechterhelft van de array (recursief)
- voeg de oplossingen
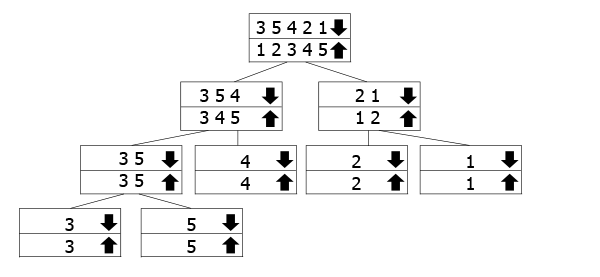
Deze boom is bedoeld om aan te geven hoe de recursieve aanroepen werk., De arrays gemarkeerd met de pijl omlaag zijn degenen die we de functie noemen voor, terwijl we de pijl omhoog samenvoegen en weer omhoog gaan. Dus je volgt de pijl naar beneden naar de onderkant van de boom, en dan ga je terug naar boven en merge.
in ons voorbeeld hebben we de array 3 5 3 2 1, dus we verdelen het in 3 5 4 en 2 1. Om ze te sorteren, verdelen we ze verder in hun componenten. Zodra we de bodem hebben bereikt, beginnen we met samenvoegen en sorteren ze terwijl we gaan.,
Als u een gedetailleerd, speciaal artikel wilt lezen voor Merge Sort, dan hebben we het voor u!
implementatie
de kernfunctie werkt vrijwel zoals beschreven in de uitleg. We geven alleen indexen left en right die indexen zijn van het meest linkse en meest rechtse element van de subarray die we willen Sorteren. Aanvankelijk zouden deze 0 en array.length-1 moeten zijn, afhankelijk van de implementatie.,
de basis van onze recursie zorgt ervoor dat we stoppen wanneer we klaar zijn, of wanneer right en left elkaar ontmoeten. We vinden een middelpunt mid, en sorteren subarrays links en rechts ervan recursief, waardoor uiteindelijk onze oplossingen worden samengevoegd.
Als u zich onze boomgrafiek herinnert, vraagt u zich misschien af waarom we niet twee nieuwe kleinere arrays maken en ze in plaats daarvan doorgeven. Dit komt omdat op echt lange arrays, dit enorme geheugenconsumptie zou veroorzaken voor iets dat in wezen onnodig is.,
Merge Sort werkt al niet op zijn plaats vanwege de merge stap, en dit zou alleen maar dienen om de geheugenefficiëntie te verergeren. De logica van onze boom van recursie blijft anders hetzelfde, maar we hoeven alleen maar de indexen te volgen die we gebruiken:
om de gesorteerde subarrays samen te voegen tot één, moeten we de lengte van elk berekenen en tijdelijke arrays maken om ze naar te kopiëren, zodat we vrij onze hoofdarray kunnen veranderen.
na het kopiëren gaan we door de resulterende array en kennen het het huidige minimum toe., Omdat onze subarrays gesorteerd zijn, kiezen we gewoon de kleinste van de twee elementen die tot nu toe niet gekozen zijn, en verplaatsen we de iterator voor die subarray naar voren:
tijdscomplexiteit
als we de complexiteit van recursieve algoritmen willen afleiden, zullen we een beetje mathy moeten krijgen.
De Masterstelling wordt gebruikt om de tijdscomplexiteit van recursieve algoritmen te achterhalen. Voor niet-recursieve algoritmen kunnen we de precieze tijdscomplexiteit meestal schrijven als een soort vergelijking, en dan gebruiken we Big-O-notatie om ze te sorteren in klassen van algoritmen die op dezelfde manier gedragen.,
het probleem met recursieve algoritmen is dat dezelfde vergelijking er ongeveer zo uit zou zien:
$$
T(n) = aT(\frac{n}{b}) + cn^k
$$
de vergelijking zelf is recursief! In deze vergelijking, a vertelt ons hoe vaak we de recursie noemen, en b vertelt ons in hoeveel delen ons probleem is verdeeld. In dit geval lijkt dat misschien een onbelangrijk onderscheid omdat ze gelijk zijn voor mergesort, maar voor sommige problemen zijn ze dat misschien niet.,
de rest van de vergelijking is de complexiteit van het samenvoegen van al deze oplossingen tot één aan het einde., De Master Stelling lost deze vergelijking voor ons:
$$
T(n) = \Bigg\{
\begin{matrix}
O(n^{log_ba}), &>b^k \\ O(n^klog n), & a = b^k \\ O(n^k), & < b^k
\end{matrix}
$$
Als T(n) runtime van het algoritme bij het sorteren van een array van lengte n, Merge Sort zou lopen twee keer voor matrices die de helft van de lengte van de originele matrix.,
dus als we a=2 hebben, b=2. De merge stap neemt o(n) geheugen, dus k=1. Dit betekent dat de vergelijking voor Merge Sort er als volgt uit zou zien:
$$
T ( n)=2T(\frac{n}{2})+cn
$$
als we de hoofdstelling toepassen, zullen we zien dat ons geval degene is waar a=b^k omdat we 2=2^1hebben. Dat betekent dat onze complexiteit O(nlog n) is. Dit is een zeer goede tijdscomplexiteit voor een sorteeralgoritme, omdat bewezen is dat een array niet sneller gesorteerd kan worden dan O(nlog n).,
hoewel de versie die we hebben getoond geheugenverslindend is, zijn er complexere versies van Merge Sort die alleen O(1) ruimte innemen.
bovendien is het algoritme zeer eenvoudig te parallelliseren, omdat recursieve aanroepen van één node volledig onafhankelijk van afzonderlijke branches kunnen worden uitgevoerd. Hoewel we niet zullen krijgen in hoe en waarom, als het buiten het toepassingsgebied van dit artikel, het is de moeite waard om in gedachten te houden de voordelen van het gebruik van dit bepaalde algoritme.,
Heapsort
uitleg
om goed te begrijpen waarom Heapsort werkt, moet u eerst de structuur begrijpen waarop het is gebaseerd – de heap. We zullen praten in termen van een binaire heap specifiek, maar je kunt het grootste deel van deze naar andere heap structuren ook generaliseren.
een heap is een boom die voldoet aan de heap-eigenschap, namelijk dat Voor elk knooppunt alle kinderen in een bepaalde relatie staan. Bovendien moet een hoop bijna compleet zijn., Een bijna complete binaire boom van depth d heeft een subboom van depth met dezelfde root die compleet is, en waarin elk knooppunt met een linkse afstammeling een complete linker subboom heeft. Met andere woorden, bij het toevoegen van een knooppunt, gaan we altijd voor de meest linkse positie in het hoogste onvolledige niveau.
als de heap een max-heap is, dan zijn alle kinderen kleiner dan de ouder, en als het een min-heap is, zijn ze allemaal groter.,
met andere woorden, als je naar beneden de boom beweegt, krijg je steeds kleinere getallen (min-heap) of Grotere en grotere getallen (max-heap). Hier is een voorbeeld van een max-heap:
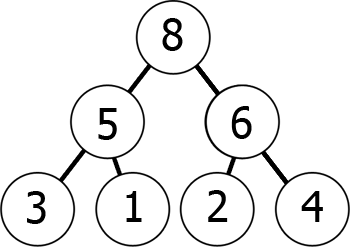
We kunnen deze max-heap in het geheugen als een array weergeven op de volgende manier:
8 5 6 3 1 2 4u kunt het zien als het lezen van de grafiek niveau voor niveau, van links naar rechts., Wat we hiermee hebben bereikt is dat als we het kth element in de array nemen, de kinderposities 2*k+1 en 2*k+2 zijn (aangenomen dat de indexering op 0 begint). U kunt dit zelf controleren.
omgekeerd is voor het elementkth de positie van de ouder altijd(k-1)/2.
Dit wetende, kunt u gemakkelijk “max-heapify” elke gegeven array . Voor elk element, controleer of een van de kinderen kleiner zijn dan het., Als ze dat zijn, ruil dan een van hen met de ouder, en herhaal deze stap recursief met de ouder (omdat het nieuwe grote element nog steeds groter kan zijn dan zijn andere kind).
bladeren hebben geen kinderen, dus zijn ze triviaal max-hopen van hun eigen:
-
6 1 8 3 5 2 4: beide kinderen zijn kleiner dan de ouder, dus alles blijft hetzelfde.
-
6 1 8 3 5 2 4: omdat 5 > 1, wisselen we ze om. We stapelen recursief voor 5 nu.
-
6 5 8 3 1 2 4: beide kinderen zijn kleiner, dus er gebeurt niets.,
-
6 5 8 3 1 2 4: omdat 8 > 6, wisselen we ze om.
-
8 5 6 3 1 2 4: we hebben de heap hierboven afgebeeld!
zodra we geleerd hebben om een array te stapelen, is de rest vrij eenvoudig. We ruilen de wortel van de hoop met het einde van de array, en verkorten de array met één.,
We heapify de verkorte array opnieuw en herhaal het proces:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: verwisseld
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: verwisseld
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: verwisseld
En zo op, ik weet zeker dat je kunt zien dat het patroon in opkomst.
implementatie
tijdscomplexiteit
als we naar de functie heapify() kijken, lijkt alles in O(1) te zijn gedaan, maar dan is er die vervelende recursieve aanroep.,
hoe vaak wordt dat aangeroepen, in het slechtste geval? Nou, in het ergste geval, zal het zich verspreiden tot aan de top van de hoop. Het zal dat doen door naar de ouder van elk knooppunt te springen, dus rond de positie i/2. dat betekent dat het in het slechtste geval log n springt voordat het de top bereikt, dus de complexiteit is O(log n).
omdat heapSort() duidelijk O(n) is vanwege het itereren van for-loops door de gehele array, zou dit de totale complexiteit van Heapsort O(nlog n) maken.,
Heapsort is een in-place sort, wat betekent dat het O(1) extra ruimte nodig heeft, in tegenstelling tot Merge Sort, maar het heeft ook een aantal nadelen, zoals het moeilijk te parallelliseren zijn.
Quicksort
uitleg
Quicksort is een ander verdeel en heers algoritme. Het kiest een element van een array als de pivot en sorteert alle andere elementen eromheen, bijvoorbeeld kleinere elementen naar links, en grotere naar rechts.
Dit garandeert dat de pivot op zijn juiste plaats staat na het proces., Dan doet het algoritme recursief hetzelfde voor de linker en rechter delen van de array.
implementatie
tijdscomplexiteit
De tijdscomplexiteit van Quicksort kan worden uitgedrukt met de volgende vergelijking:
$$
T(n) = T(k) + T(n-k-1) + O(n)
$$
het slechtste scenario is wanneer het grootste of kleinste element altijd wordt gekozen voor pivot. De vergelijking zou er dan zo uitzien:
$$
T ( N) = T(0) + T(N-1) + O(N) = T(n-1) + O(n)
$$
Dit blijkt O(n^2) te zijn.,
Dit kan slecht klinken, omdat we al meerdere algoritmen hebben geleerd die in o(nlog n) tijd draaien als hun slechtste geval, maar Quicksort wordt eigenlijk zeer veel gebruikt.
Dit komt omdat het een echt goede gemiddelde runtime heeft, ook begrensd door O(nlog n), en zeer efficiënt is voor een groot deel van de mogelijke ingangen.
een van de redenen waarom het de voorkeur geeft aan het samenvoegen van Sort is dat het geen extra ruimte in beslag neemt, dat het sorteren op zijn plaats wordt uitgevoerd en dat er geen dure allocatie-en deallocatieaanroepen zijn.,
Performance Comparison
dat alles gezegd hebbende, is het vaak nuttig om al deze algoritmen een paar keer op je machine te draaien om een idee te krijgen van hoe ze presteren.
ze zullen natuurlijk anders presteren met verschillende collecties die gesorteerd worden, maar zelfs met dat in gedachten, zou je in staat moeten zijn om enkele trends op te merken.
laten we alle implementaties één voor één uitvoeren, elk op een kopie van een geschud array van 10.000 gehele getallen:
We kunnen duidelijk zien dat Bubble Sorteer het slechtste is als het gaat om prestaties., Vermijd het gebruik ervan in productie als u niet kunt garanderen dat het alleen kleine collecties zal behandelen en het zal de toepassing niet vertragen.
HeapSort en QuickSort zijn de beste prestaties. Hoewel ze vergelijkbare resultaten uitvoeren, QuickSort heeft de neiging om een beetje beter en consistenter te zijn – wat klopt.
sorteren in Java
vergelijkbare Interface
Als u uw eigen typen hebt, kan het lastig worden om een apart sorteeralgoritme voor elk type te implementeren. Daarom biedt Java een interface waarmee je Collections.sort() op je eigen klassen kunt gebruiken.,
om dit te doen, moet uw klasse de interface Comparable<T> implementeren, waarbij T uw type is, en een methode genaamd .compareTo()overschrijven.
deze methode geeft een negatief geheel getal terug als this kleiner is dan het argumentelement, 0 als ze gelijk zijn, en een positief geheel getal als this groter is.
in ons voorbeeld hebben we een klas Student gemaakt, en elke student wordt geïdentificeerd door een en een jaar begonnen ze met hun studie.,
we willen ze voornamelijk Sorteren op generaties, maar ook secundair op ID ‘ s:
en hier is hoe het te gebruiken in een toepassing:
Output:
Vergelijkingsinterface
we willen misschien onze objecten Sorteren op een onorthodoxe manier voor een specifiek doel, maar we willen dat niet implementeren als het standaard gedrag van onze klasse, of we misschien wordt het sorteren van een verzameling van een ingebouwd type op een niet-standaard manier.
hiervoor kunnen we de interface Comparator gebruiken., Laten we bijvoorbeeld onze Student Klasse nemen en alleen Sorteren op ID:
als we de sorteeraanroep in main vervangen door het volgende:
Arrays.sort(a, new SortByID());uitvoer:
Hoe werkt het allemaal
Collection.sort() werkt door de onderliggende Arrays.sort() methode aan te roepen, terwijl de sortering zelf insertiesort gebruikt voor arrays korter dan 47, en QuickSort voor de rest.,
Het is gebaseerd op een specifieke twee-pivot implementatie van Quicksort die ervoor zorgt dat het de meeste typische oorzaken van afbraak in kwadratische prestaties vermijdt, volgens de jdk10 documentatie.
conclusie
sorteren is een veel voorkomende bewerking met datasets, of het nu is om ze verder te analyseren, het zoeken te versnellen met behulp van efficiëntere algoritmen die afhankelijk zijn van de gegevens die worden gesorteerd, filtergegevens, enz.
Sorteren wordt door vele talen ondersteund en de interfaces verdoezelen vaak wat er werkelijk met de programmeur gebeurt., Hoewel deze abstractie is welkom en noodzakelijk voor effectief werk, kan het soms dodelijk voor efficiëntie, en het is goed om te weten hoe verschillende algoritmen te implementeren en vertrouwd te zijn met hun voor-en nadelen, evenals hoe gemakkelijk toegang tot ingebouwde implementaties.