een kanssteekproefmethode is elke bemonsteringsmethode waarbij gebruik wordt gemaakt van een willekeurige selectie. Om een willekeurige selectiemethode te hebben, moet u een proces of procedure opzetten die ervoor zorgt dat de verschillende eenheden in uw populatie gelijke kansen hebben om gekozen te worden. Mensen hebben lange tijd geoefend verschillende vormen van willekeurige selectie, zoals het kiezen van een naam uit een hoed, of het kiezen van het korte strootje. Tegenwoordig hebben we de neiging om computers te gebruiken als het mechanisme voor het genereren van willekeurige getallen als basis voor willekeurige selectie.,
enkele definities
voordat ik de verschillende waarschijnlijkheidsmethoden kan uitleggen, moeten we enkele basistermen definiëren. Deze zijn:
-
Nis het nummer van de gevallen in het steekproefkader -
nis het nummer van de gevallen in de steekproef -
NCn= het aantal combinaties (subsets) vannuitN -
f = n/Nwordt de sampling-fractie
Dat is het., Met deze termen gedefinieerd kunnen we beginnen met het definiëren van de verschillende kanssteekproeven methoden.
eenvoudige willekeurige bemonstering
De eenvoudigste vorm van willekeurige bemonstering wordt eenvoudige willekeurige bemonstering genoemd. Best lastig, hè? Hier is de korte beschrijving van eenvoudige willekeurige bemonstering:
- doelstelling:
neenheden selecteren uitNzodanig dat elkeNCneen gelijke kans heeft om geselecteerd te worden. - Procedure: gebruik een tabel met willekeurige getallen, een computer-generator voor willekeurige getallen of een mechanisch apparaat om het monster te selecteren.,
een enigszins gefaseerde, indien nauwkeurig, definitie. Laten we kijken of we het een beetje reëler kunnen maken.

Hoe selecteren we een eenvoudige willekeurige steekproef? Laten we aannemen dat we wat onderzoek doen met een klein servicebureau dat de visie van klanten op de kwaliteit van de dienstverlening in het afgelopen jaar wil beoordelen. Eerst moeten we het sampling frame organiseren. Om dit te bereiken, gaan we door de administratie van het Agentschap om elke cliënt te identificeren in de afgelopen 12 maanden. Als we geluk hebben, het Agentschap heeft goede nauwkeurige geautomatiseerde gegevens en kan snel een dergelijke lijst te produceren., Dan moeten we het monster nemen. Bepaal het aantal klanten dat u in de uiteindelijke steekproef wilt hebben. In het belang van het voorbeeld, laten we zeggen dat u wilt selecteren 100 clients te onderzoeken en dat er 1000 clients in de afgelopen 12 maanden. Vervolgens is de bemonsteringsfractie f = n/N = 100/1000 = .10 (of 10%). Om het monster te tekenen, heb je verschillende opties. Je zou de lijst van 1000 klanten kunnen printen, dan in aparte strips scheuren, de strips in een hoed doen, ze goed mengen, je ogen sluiten en de eerste 100 eruit halen., Maar deze mechanische procedure zou vervelend zijn en de kwaliteit van het monster zou afhangen van hoe grondig je ze gemengd en hoe willekeurig je bereikt in. Misschien een betere procedure zou zijn om het soort bal machine die populair is bij veel van de staat loterijen gebruiken. Je hebt drie sets ballen nodig met de nummers 0 tot en met 9, één set voor elk van de cijfers van 000 tot 999 (als we 000 selecteren, noemen we dat 1000)., Nummer de lijst met namen van 1 tot 1000 en gebruik de balmachine om de drie cijfers te selecteren die elke persoon selecteert. Het voor de hand liggende nadeel hier is dat je nodig hebt om de bal machines te krijgen. (Waar maken ze die dingen eigenlijk? Is er een balmachine industrie?).
geen van deze mechanische procedures is zeer haalbaar en met de ontwikkeling van goedkope computers is er een veel gemakkelijkere manier. Hier is een eenvoudige procedure die vooral handig is als u de namen van de clients al op de computer., Veel computerprogramma ‘ s kunnen een reeks willekeurige getallen genereren. Laten we aannemen dat u de lijst met clientnamen kunt kopiëren en plakken in een kolom in een EXCEL-spreadsheet. Plak vervolgens in de kolom ernaast de functie =RAND() wat EXCEL ‘ s manier is om een willekeurig getal tussen 0 en 1 in de cellen te plaatsen. Sorteer vervolgens beide kolommen – de lijst met namen en het willekeurige nummer-op de willekeurige getallen. Dit herschikt de lijst in willekeurige volgorde van het laagste naar het hoogste willekeurige getal., Dan hoeft u alleen maar de eerste honderd namen in deze gesorteerde lijst te nemen. vrij simpel. Je kunt het waarschijnlijk allemaal in minder dan een minuut volbrengen.
eenvoudige willekeurige bemonstering is eenvoudig te bereiken en is gemakkelijk uit te leggen aan anderen. Omdat eenvoudige willekeurige bemonstering een eerlijke manier is om een steekproef te selecteren, is het redelijk om de resultaten van de steekproef terug naar de populatie te veralgemenen. Eenvoudige willekeurige sampling is niet de meest statistisch efficiënte methode van sampling en je kan, gewoon vanwege het geluk van de loting, geen goede vertegenwoordiging van subgroepen in een populatie krijgen., Om deze problemen aan te pakken, moeten we andere bemonsteringsmethoden gebruiken.
gestratificeerde aselecte steekproef
gestratificeerde aselecte steekproef, ook wel proportionele of quota-aselecte steekproef genoemd, omvat het verdelen van uw populatie in homogene subgroepen en vervolgens het nemen van een eenvoudige aselecte steekproef in elke subgroep. In meer formele termen:
er zijn verschillende belangrijke redenen waarom u de voorkeur geeft aan gestratificeerde bemonstering boven eenvoudige willekeurige bemonstering., Ten eerste zorgt het ervoor dat u niet alleen de totale bevolking kunt vertegenwoordigen, maar ook belangrijke subgroepen van de bevolking, met name kleine minderheidsgroepen. Als je over subgroepen wilt kunnen praten, is dit misschien de enige manier om er zeker van te zijn dat je dat kunt. Als de subgroep extreem klein is, kunt u verschillende samplingfracties (f) binnen de verschillende strata gebruiken om willekeurig de kleine groep te over-sampleen (hoewel u dan de schattingen binnen de groep moet wegen met behulp van de samplingfractie wanneer u algemene populatieschattingen wilt)., Wanneer we dezelfde bemonsteringsfractie binnen strata gebruiken, voeren we proportionele gestratificeerde aselecte bemonstering uit. Wanneer we verschillende bemonsteringsfracties gebruiken in de strata, noemen we dit onevenredige gestratificeerde willekeurige bemonstering. Ten tweede zal gestratificeerde aselecte bemonstering over het algemeen meer statistische precisie hebben dan eenvoudige aselecte bemonstering. Dit geldt alleen als de lagen of groepen homogeen zijn. Als dat zo is, verwachten we dat de variabiliteit binnen-groepen lager is dan de variabiliteit voor de populatie als geheel. Stratified sampling kapitaliseert op dat feit.,
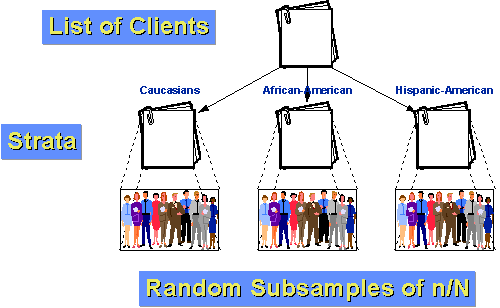
bijvoorbeeld, laten we zeggen dat de populatie van klanten voor ons agentschap kan worden onderverdeeld in drie groepen: Blank, Afro-Amerikaans en Hispanic-Amerikaans. Laten we verder aannemen dat zowel de Afro-Amerikanen als de Latijns-Amerikanen relatief kleine minderheden van de clientèle zijn (10% en 5% respectievelijk)., Als we gewoon een eenvoudige willekeurige steekproef van n=100 met een steekproeffractie van 10% zouden doen, zouden we alleen bij toeval verwachten dat we slechts 10 en 5 personen uit elk van onze twee kleinere groepen zouden krijgen. En, bij toeval, we konden minder dan dat! Als we stratificeren, kunnen we het beter doen. Laten we eerst bepalen hoeveel mensen we in elke groep willen hebben. Laten we zeggen dat we nog steeds willen nemen een steekproef van 100 van de bevolking van 1000 klanten in het afgelopen jaar. Maar we denken dat om iets over subgroepen te kunnen zeggen we minstens 25 gevallen per groep nodig hebben., Laten we 50 Kaukasiërs, 25 Afro-Amerikanen en 25 Latijns-Amerikanen bekijken. We weten dat 10% van de bevolking, of 100 klanten, Afro-Amerikaans zijn. Als we er 25 aselecte monsters van nemen, hebben we een binnenstratum bemonsteringsfractie van 25/100 = 25%. Ook weten we dat 5% of 50 klanten Spaans-Amerikaans zijn. Dus onze binnen-stratum sampling fractie zal 25/50 = 50%zijn. Door af te trekken weten we dat er 850 Blanke klanten zijn. Onze binnen-stratum bemonstering fractie voor hen is 50/850 = about 5.88%., Omdat de groepen binnen de groep homogener zijn dan over de populatie als geheel, kunnen we een grotere statistische precisie verwachten (minder variantie). En, omdat we gestratificeerd hebben, weten we dat we genoeg gevallen van elke groep zullen hebben om betekenisvolle subgroep gevolgtrekkingen te maken.,e zijn de stappen die je moet volgen om te komen tot een systematische steekproef:
- het aantal van de eenheden in de populatie van
1totN - beslissen over de
n(sample size) die u wilt of nodig -
k = N/n= het interval grootte - willekeurig selecteert u een geheel getal tussen
1totk - neem vervolgens elke
kthapparaat

dit Alles zal veel duidelijker met een voorbeeld., Laten we aannemen dat we een populatie hebben die slechts n=100 mensen bevat en dat je een monster wilt nemen van n=20. Om systematische bemonstering te gebruiken, moet de populatie in een willekeurige volgorde worden vermeld. De bemonsteringsfractie zou f = 20/100 = 20%zijn. in dit geval is de intervalgrootte, k, gelijk aan N/n = 100/20 = 5. Selecteer nu een willekeurig geheel getal uit 1 to 5. Stel je voor dat je in ons voorbeeld 4hebt gekozen., Nu, om het voorbeeld te selecteren, begin met de4th eenheid in de lijst en neem elkek-th eenheid (elke 5e, omdat k=5). Je zou eenheden 4, 9, 14, 19, enzovoort tot 100 nemen en je zou eindigen met 20 eenheden in je monster.
om dit te laten werken, is het essentieel dat de eenheden in de populatie willekeurig worden geordend, ten minste met betrekking tot de kenmerken die u meet. Waarom zou je ooit systematische willekeurige steekproeven willen gebruiken? Ten eerste is het vrij gemakkelijk om te doen. Je hoeft maar één willekeurig getal te selecteren om te beginnen., Het kan ook nauwkeuriger zijn dan eenvoudige aselecte bemonstering. Ten slotte is er in sommige situaties gewoon geen gemakkelijkere manier om willekeurige steekproeven te doen. Bijvoorbeeld, Ik moest eens een studie die bemonstering van alle boeken in een bibliotheek betrokken. Eenmaal geselecteerd, zou ik naar de plank moeten gaan, het boek lokaliseren, en opnemen wanneer het voor het laatst verspreidde. Ik wist dat ik had een vrij goede sampling frame in de vorm van de plank lijst (dat is een kaart catalogus waar de ingangen zijn gerangschikt in de volgorde waarin ze zich voordoen op de plank)., Om een eenvoudige willekeurige steekproef te doen, had ik het totale aantal boeken kunnen schatten en willekeurige getallen kunnen genereren om de steekproef te tekenen; maar hoe zou ik Boek #74,329 gemakkelijk vinden als dat het nummer is dat ik heb geselecteerd? Ik kon de kaarten niet goed tellen tot ik bij 74.329 kwam! Stratiseren zou dat probleem ook niet oplossen. Bijvoorbeeld, Ik kon gestratificeerd door Kaart catalogus lade en tekende een eenvoudige willekeurige steekproef in elke lade. Maar dan moet ik nog steeds kaarten tellen. In plaats daarvan deed ik een systematische steekproef. Ik schatte het aantal boeken in de hele collectie. Stel je voor dat het 100.000 was., Ik besloot dat ik een monster van 1000 wilde nemen voor een bemonsteringsfractie van 1000/100,000 = 1%. Om het bemonsteringsinterval te krijgen k, verdeelde ik N/n = 100,000/1000 = 100. Daarna heb ik een willekeurig geheel getal geselecteerd tussen 1 en 100. Laten we zeggen dat ik 57heb.
vervolgens heb ik een kleine studie gedaan om te bepalen hoe dik duizend kaarten zijn in de kaartencatalogus (rekening houdend met de verschillende leeftijden van de kaarten)., Laten we zeggen dat ik gemiddeld vond dat twee kaarten die gescheiden waren door 100 kaarten ongeveer .75 inches uit elkaar lagen in de catalog lade. Die informatie gaf me alles wat ik nodig had om het monster te nemen. Ik telde tot de 57ste met de hand en nam de boekinformatie op. Toen nam ik een kompas. (Herinner je die van je middelbare school wiskundeles? Het zijn de grappige kleine metalen instrumenten met een scherpe speld aan de ene kant en een potlood aan de andere kant die je gebruikte om cirkels te tekenen in de meetkundeles.,) Dan stel ik het kompas in op .75", stak de pin end in op de 57e kaart en wees met het potlood einde naar de volgende kaart (ongeveer 100 boeken verwijderd). Op deze manier benaderde ik het selecteren van de 157e, 257e, 357e, enzovoort. Ik was in staat om de hele selectieprocedure te voltooien in zeer korte tijd met behulp van deze systematische willekeurige bemonstering aanpak. Ik zou er waarschijnlijk nog steeds zijn kaarten tellen als ik een andere willekeurige steekproefmethode had geprobeerd. Oké, dus ik heb geen leven. Ik werd goed gecompenseerd, ik vind het niet erg om te zeggen, voor het bedenken van deze regeling.,)
Cluster (Area) aselecte Sampling
het probleem met aselecte samplingmethoden wanneer we een populatie moeten bemonsteren die verspreid is over een brede geografische regio is dat je een groot stuk grond geografisch moet bestrijken om bij elk van de eenheden te komen die je hebt bemonsterd. Stel je voor dat je een eenvoudige steekproef neemt van alle inwoners van de staat New York om persoonlijke interviews te houden. Door het geluk van de loting zul je eindigen met respondenten die uit alle hoeken van de staat komen. Je interviewers gaan veel reizen te doen hebben., Het is precies voor dit probleem dat cluster of gebied willekeurige bemonstering werd uitgevonden.
bij clusterbemonstering volgen we de volgende stappen:
- verdeel de populatie in clusters (meestal langs geografische grenzen)
- willekeurig steekproefclusters
- meet alle eenheden binnen bemonsterde clusters
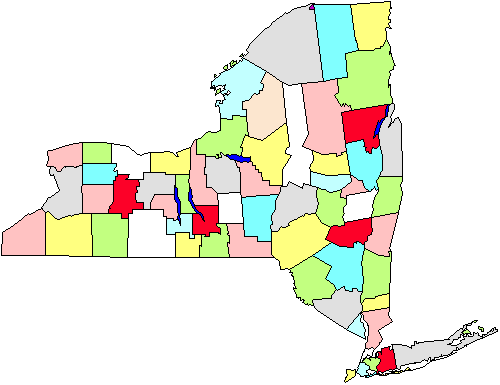
in de figuur zien we bijvoorbeeld een kaart van de county ‘ s in de staat New York. Laten we zeggen dat we een overzicht moeten maken van de stadsbesturen, waardoor we persoonlijk naar de steden moeten gaan., Als we een simpele steekproef maken, moeten we de hele staat geografisch bestrijken. In plaats daarvan besluiten we om een clusterbemonstering van vijf provincies te doen (in het rood gemarkeerd in de figuur). Zodra deze geselecteerd zijn, gaan we naar elke gemeente in de vijf gebieden. Het is duidelijk dat deze strategie ons zal helpen om te besparen op onze kilometerstand. Cluster of gebied bemonstering, dan, is nuttig in situaties als deze, en wordt voornamelijk gedaan voor efficiëntie van administratie., Merk ook op dat we ons waarschijnlijk geen zorgen hoeven te maken over het gebruik van deze aanpak als we een e-mail of telefonische enquête uitvoeren, omdat het niet zo veel uitmaakt (of meer kosten of inefficiëntie verhogen) waar we bellen of brieven naar sturen.
meerfasige bemonstering
De vier methoden die we tot nu toe hebben behandeld – eenvoudig, gestratificeerd, systematisch en cluster – zijn de eenvoudigste aselecte bemonsteringsstrategieën. In de meeste echt toegepast sociaal onderzoek, zouden we sampling methoden gebruiken die aanzienlijk complexer zijn dan deze eenvoudige variaties., Het belangrijkste principe hier is dat we de eenvoudige methoden eerder beschreven op een verscheidenheid van nuttige manieren die ons helpen om onze monstername behoeften op de meest efficiënte en effectieve manier mogelijk te combineren. Als we samplingmethoden combineren, noemen we dit meerfasige sampling.
overweeg bijvoorbeeld het idee om inwoners van de staat New York te bemonsteren voor persoonlijke interviews. Het is duidelijk dat we een soort clusterbemonstering willen doen als de eerste fase van het proces. We kunnen townships of volkstellingen in de hele staat bekijken., Maar in cluster sampling zouden we dan verder gaan met het meten van iedereen in de clusters die we selecteren. Zelfs als we census tracts bemonsteren, kunnen we misschien niet iedereen meten die in de census tract. We kunnen een gestratificeerd bemonsteringsproces opzetten binnen de clusters. In dit geval zouden we een tweetraps bemonsteringsproces hebben met gestratificeerde monsters binnen clustermonsters. Of, overweeg het probleem van het bemonsteren van studenten in lagere scholen. We zouden kunnen beginnen met een nationale steekproef van schooldistricten gestratificeerd naar economie en onderwijsniveau., In geselecteerde districten zouden we een eenvoudige steekproef van scholen kunnen maken. Binnen scholen, kunnen we een eenvoudige willekeurige steekproef van klassen of cijfers. En, binnen de lessen, kunnen we zelfs een eenvoudige willekeurige steekproef van studenten doen. In dit geval hebben we drie of vier fasen in het bemonsteringsproces en we gebruiken zowel gestratificeerde als eenvoudige willekeurige bemonstering. Door het combineren van verschillende bemonsteringsmethoden zijn we in staat om een rijke verscheidenheid aan probabilistische bemonsteringsmethoden te bereiken die kunnen worden gebruikt in een breed scala van sociale onderzoekscontexten.