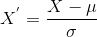Inleiding tot functie schalen
Ik werkte onlangs met een dataset die meerdere functies had, variërend van grootte, bereik en eenheden. Dit is een belangrijk obstakel aangezien enkele machine het leren algoritmen hoogst gevoelig voor deze eigenschappen zijn.
Ik weet zeker dat de meesten van jullie dit probleem hebben ondervonden in jullie projecten of jullie leertraject., Bijvoorbeeld, een functie is volledig in kilogram, terwijl de andere is in gram, een andere is liters, enzovoort. Hoe kunnen we deze functies gebruiken als ze zo sterk variëren in termen van wat ze presenteren?
Dit is waar ik me richtte op het concept van functieschaling. Het is een cruciaal onderdeel van de data preprocessing fase, maar ik heb gezien dat veel beginners over het hoofd (ten koste van hun machine learning model).,

Hier is het merkwaardige aan het schalen van functies – het verbetert (aanzienlijk) de prestaties van sommige machine learning-algoritmen en werkt helemaal niet voor anderen. Wat kan de reden zijn achter deze gril?
Wat is ook het verschil tussen normalisatie en standaardisatie? Dit zijn twee van de meest gebruikte eigenschap schalen technieken in machine het leren maar een niveau van ambiguïteit bestaat in hun begrip. Wanneer moet je welke techniek gebruiken?,
Ik zal deze vragen en meer beantwoorden in dit artikel over schalen van functies. We zullen ook feature scaling implementeren in Python om u een praktijk inzicht te geven in hoe het werkt voor verschillende machine learning algoritmen.
opmerking: Ik neem aan dat u bekend bent met Python en core machine learning algoritmen., Als dit nieuw voor u is, raad ik u aan om de volgende cursussen te doorlopen:
- Python for Data Science
- Alle Gratis Machine Learning cursussen van Analytics Vidhya
- toegepast Machine Learning
inhoudsopgave
- waarom zouden we Functieschaling gebruiken?
- Wat is normalisatie?
- Wat is standaardisatie?de grote vraag-normaliseren of standaardiseren?,
- implementatie van Functieschaling in Python
- normalisatie gebruikmakend van Sklearn
- standaardisatie gebruikmakend van Sklearn
- toepassing van Functieschaling op Machine Learning-algoritmen
- K-Dichtstbijzijnde buren (KNN)
- ondersteuning Vectorregressor
- beslissingsboom
waarom zouden we gebruiken functie schalen?
de eerste vraag die we moeten beantwoorden – waarom moeten we de variabelen in onze dataset schalen? Sommige machine learning algoritmen zijn gevoelig voor functie schalen, terwijl anderen zijn vrijwel invariant om het., Ik zal dat nader toelichten.
op Gradiëntafdaling gebaseerde algoritmen
machine learning-algoritmen zoals lineaire regressie, logistieke regressie, neuraal netwerk, enz. die gradiëntafdaling gebruiken als optimalisatietechniek vereisen dat gegevens worden geschaald. Neem een kijkje in de onderstaande formule voor gradiëntafdaling:

de aanwezigheid van feature waarde X in de formule zal de stapgrootte van de gradiëntafdaling beïnvloeden. Het verschil in bereik van functies zal verschillende stapgroottes voor elke functie veroorzaken., Om ervoor te zorgen dat de gradiëntafdaling soepel naar de minima beweegt en dat de stappen voor gradiëntafdaling voor alle functies met dezelfde snelheid worden bijgewerkt, schalen we de gegevens voordat we ze aan het model toevoeren.
het hebben van functies op een vergelijkbare schaal kan helpen de gradiëntafdaling sneller naar de minima te convergeren.
op afstand gebaseerde algoritmen
Op afstand gebaseerde algoritmen zoals KNN, K-means en SVM worden het meest beïnvloed door het bereik van functies., Dit komt omdat ze achter de schermen afstanden tussen datapunten gebruiken om hun gelijkenis te bepalen.
bijvoorbeeld, laten we zeggen dat we gegevens hebben met middelbare school CGPA scores van studenten (variërend van 0 tot 5) en hun toekomstige inkomen (in duizenden roepies):

aangezien beide functies verschillende schalen hebben, is er een kans dat een hoger gewicht wordt gegeven aan functies met een hogere magnitude. Dit zal de prestaties van de machine learning algoritme beà nvloeden en natuurlijk, we willen niet dat ons algoritme wordt bevooroordeeld naar één functie.,
daarom schalen we onze gegevens voordat we een op afstand gebaseerd algoritme gebruiken, zodat alle functies gelijkelijk bijdragen aan het resultaat.,nts A en B en tussen B en C, voor en na de schalen zoals hieronder weergegeven:
- Afstand AB voor schaling =>

- Afstand BC voor schaling =>

- Afstand AB na schaling =>

- Afstand BC na schaling =>

Schalen heeft gebracht zowel de functies in het beeld en de afstanden zijn nu meer vergelijkbaar dan ze waren voordat we schaling toegepast.,
Boomgebaseerde algoritmen
Boomgebaseerde algoritmen zijn daarentegen tamelijk ongevoelig voor de schaal van de eigenschappen. Denk er eens over na, een besluit boom is alleen splitsen van een knooppunt op basis van een enkele functie. De beslissingsboom splitst een knooppunt op een functie die de homogeniteit van het knooppunt verhoogt. Deze splitsing op een functie wordt niet beïnvloed door andere functies.
Er is dus vrijwel geen effect van de resterende functies op de splitsing. Dit is wat maakt ze invariant aan de schaal van de functies!
Wat is normalisatie?,
normalisatie is een schaling techniek waarbij waarden worden verschoven en aangepast zodat ze eindigen tussen 0 en 1. Het is ook bekend als Min-Max scaling.
Hier is de formule voor normalisatie:
Hier zijn Xmax en Xmin respectievelijk de maximale en de minimale waarden van de functie.,
- wanneer de waarde van X de minimumwaarde in de kolom is, is de teller 0, en dus X’ is 0
- aan de andere kant, wanneer de waarde van X de maximumwaarde in de kolom is, is de teller gelijk aan de noemer en dus is de waarde van X’ 1
- indien de waarde van X tussen de minimum-en de maximumwaarde ligt, dan is de waarde van X’ tussen 0 en 1
Wat is standaardisatie?
standaardisatie is een andere schaaltechniek waarbij de waarden gecentreerd zijn rond het gemiddelde met een standaarddeviatie per eenheid., Dit betekent dat het gemiddelde van de eigenschap nul wordt en dat de resulterende verdeling een standaardafwijking per eenheid heeft.
Hier is de formule voor standaardisatie:
is het gemiddelde van de featurewaarden en
is de standaardafwijking van de featurewaarden. Merk op dat in dit geval de waarden niet beperkt zijn tot een bepaald bereik.
nu, de grote vraag in je gedachten moet zijn wanneer moeten we normalisatie gebruiken en wanneer moeten we standaardisatie gebruiken? Laten we dat uitzoeken!,
de grote vraag-normaliseren of standaardiseren?
normalisatie Versus standaardisatie is een eeuwige vraag onder machine learning nieuwkomers. Laat ik het antwoord in deze sectie toelichten.
- normalisatie is goed om te gebruiken als u weet dat de distributie van uw gegevens geen Gaussiaanse distributie volgt. Dit kan nuttig zijn in algoritmen die geen distributie van de gegevens zoals K-Dichtstbijzijnde buren en neurale netwerken veronderstellen.
- standaardisatie kan daarentegen nuttig zijn in gevallen waarin de gegevens een Gaussiaanse distributie volgen., Dit hoeft echter niet per se waar te zijn. In tegenstelling tot normalisatie heeft standaardisatie geen begrenzend bereik. Dus, zelfs als je uitschieters in uw gegevens, zullen ze niet worden beïnvloed door standaardisatie.
echter, aan het einde van de dag, de keuze van het gebruik van normalisatie of standaardisatie zal afhangen van uw probleem en het machine learning algoritme dat u gebruikt. Er is geen harde en snelle regel om u te vertellen wanneer u uw gegevens moet normaliseren of standaardiseren., U kunt altijd beginnen met het aanpassen van uw model aan ruwe, genormaliseerde en gestandaardiseerde gegevens en de prestaties vergelijken voor de beste resultaten.
Het is een goede praktijk om de scaler aan te passen aan de trainingsgegevens en deze vervolgens te gebruiken om de testgegevens te transformeren. Dit zou het weglekken van gegevens tijdens het modeltestproces voorkomen. Ook is het schalen van streefwaarden over het algemeen niet vereist.
implementatie van Feature Scaling in Python
nu komt het leuke deel – het in de praktijk brengen van wat we hebben geleerd., Ik zal functieschaling toepassen op een paar machine learning algoritmen op de Big Mart dataset die ik het DataHack platform heb genomen.
Ik sla de preprocessing stappen over omdat ze buiten het bereik van deze tutorial vallen. Maar je vindt ze netjes uitgelegd in dit artikel. Deze stappen zullen u toelaten om de top 20 percentiel op de hackathon leaderboard te bereiken, dus dat is de moeite waard om uit te checken!
dus, laten we eerst onze gegevens opsplitsen in trainings-en testsets:
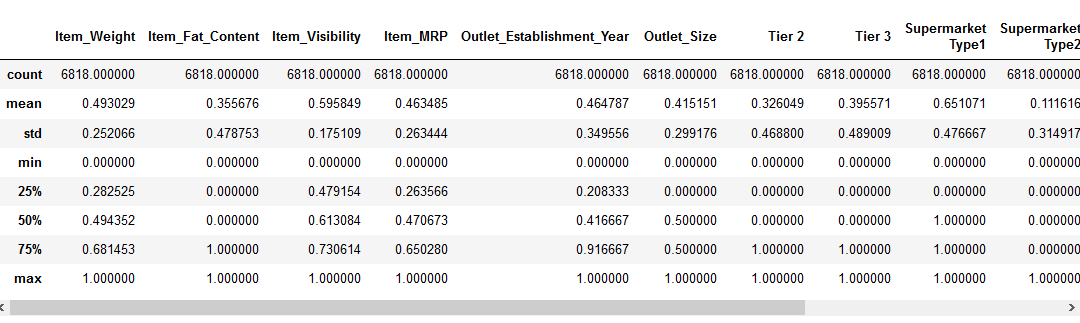
voordat we naar de functie schalen gaan, kijken we naar de details over onze gegevens met behulp van de pd.,describe () method:
We kunnen zien dat er een enorm verschil is in het bereik van waarden aanwezig in onze numerieke kenmerken: Item_Visibility, Item_Weight, Item_MRP, en Outlet_Establishment_Year. Laten we proberen en fix dat met behulp van functie scaling!
Opmerking: U zult negatieve waarden opmerken in de Item_Visibility functie omdat Ik log-transformatie heb genomen om de scheefheid in de functie aan te pakken.
normalisatie gebruikmakend van sklearn
om uw gegevens te normaliseren, moet u de MinMaxScalar importeren uit de sklearn bibliotheek en deze toepassen op onze dataset., Dus, laten we dat doen!
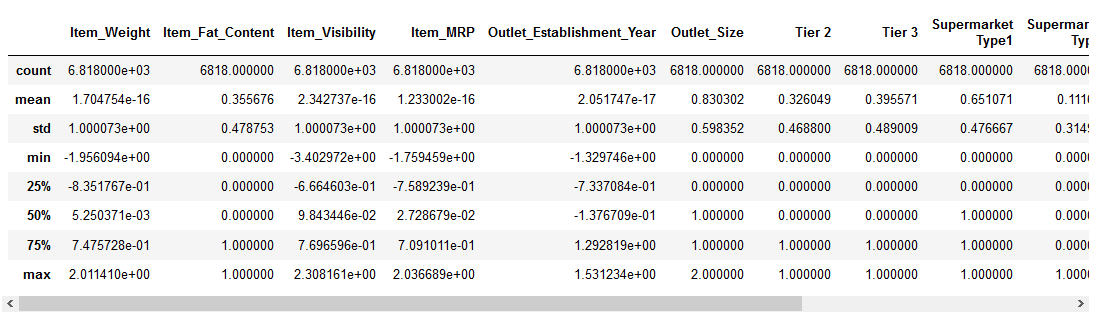
laten we eens kijken hoe normalisatie onze dataset heeft beïnvloed:
alle functies hebben nu een minimumwaarde van 0 en een maximumwaarde van 1. Perfect!
probeer de bovenstaande code uit in het live codering venster hieronder!!
vervolgens proberen we onze gegevens te standaardiseren.
standaardisatie gebruikmakend van sklearn
om uw gegevens te standaardiseren, moet u de Standaardcalar importeren uit de sklearn bibliotheek en toepassen op onze dataset., Hier is hoe je het kunt doen:
je zou gemerkt hebben dat ik alleen standaardisatie toepaste op mijn numerieke kolommen en niet de andere One-Hot gecodeerde functies. Standaardiseren van de One-Hot gecodeerde functies zou betekenen het toewijzen van een distributie aan categorische functies. Dat wil je niet doen!
maar waarom heb ik niet hetzelfde gedaan tijdens het normaliseren van de gegevens? Omdat One-Hot gecodeerde functies zijn al in het bereik tussen 0 en 1. Dus normalisatie zou hun waarde niet beïnvloeden.,
rechts, laten we eens kijken hoe standaardisatie onze gegevens heeft getransformeerd:
De numerieke kenmerken zijn nu gecentreerd op het gemiddelde met een standaarddeviatie per eenheid. Geweldig!
het vergelijken van niet-geschaalde, genormaliseerde en gestandaardiseerde gegevens
Het is altijd geweldig om uw gegevens te visualiseren om de aanwezige distributie te begrijpen. We kunnen de vergelijking zien tussen onze ongeschaalde en geschaalde gegevens met behulp van boxplots.
meer informatie over datavisualisatie vindt u hier.,
u kunt zien hoe het schalen van de functies alles in perspectief brengt. De functies zijn nu meer vergelijkbaar en zullen een vergelijkbaar effect hebben op de leermodellen.
schaal toepassen op Machine Learning-algoritmen
het is nu tijd om enkele machine learning-algoritmen op onze data te trainen om de effecten van verschillende schaaltechnieken op de prestaties van het algoritme te vergelijken. Ik wil het effect van schalen zien op drie algoritmen in het bijzonder: K-Dichtstbijzijnde buren, ondersteuning Vector Regressor, en Decision Tree.,
K-Dichtstbijzijnde buren
zoals we eerder zagen, is KNN een op afstand gebaseerd algoritme dat wordt beïnvloed door het bereik van functies. Laten we eens kijken hoe het presteert op onze data, voor en na het schalen:
u kunt zien dat het schalen van de functies de RMSE-score van ons KNN-model heeft verlaagd. Specifiek, de genormaliseerde gegevens presteert een tikkeltje beter dan de gestandaardiseerde gegevens.
opmerking: Ik meet hier de RMSE omdat deze wedstrijd de RMSE evalueert.
Ondersteuning Vector Regressor
SVR is een ander op afstand gebaseerd algoritme., Dus laten we eens kijken of het beter werkt met normalisatie of standaardisatie:
We kunnen zien dat het schalen van de functies de RMSE score omlaag brengt. En de gestandaardiseerde gegevens hebben beter gepresteerd dan de genormaliseerde gegevens. Waarom denk je dat dat het geval is?
de documentatie van sklearn stelt dat SVM, met de kernel RBF, ervan uitgaat dat alle functies rond nul zijn gecentreerd en dat de variantie van dezelfde orde is. Dit komt omdat een functie met een variantie groter dan die van anderen voorkomt dat de schatter van het leren van alle functies., Geweldig!
beslissingsboom
we weten al dat een beslissingsboom invariant is voor het schalen van functies. Maar ik wilde een praktisch voorbeeld laten zien van hoe het presteert op de data:
U kunt zien dat de RMSE-score geen centimeter is verschoven bij het schalen van de functies. Dus wees gerust wanneer u gebruik maakt van boom-gebaseerde algoritmen op uw gegevens!,
End Notes
Deze tutorial behandelde de relevantie van het gebruik van functieschaling op uw gegevens en hoe normalisatie en standaardisatie wisselende effecten hebben op de werking van machine learning algoritmen
houd in gedachten dat er geen juist antwoord is op wanneer normalisatie boven standaardisatie te gebruiken en vice versa. Het hangt allemaal af van uw gegevens en het algoritme dat u gebruikt.
als volgende stap moedig ik u aan om functieschaling uit te proberen met andere algoritmen en erachter te komen wat het beste werkt – normalisatie of standaardisatie?, Ik raad u aan de verkoopgegevens van BigMart voor dat doel te gebruiken om de continuïteit met dit artikel te behouden. En vergeet niet om uw inzichten te delen in de commentaren hieronder!
u kunt dit artikel ook lezen op onze mobiele APP