Innledning
Sortering av data betyr å arrangere det i en bestemt rekkefølge, ofte i en array-som data struktur. Du kan bruke ulike bestilling kriterier, felles de blir sortering av tall fra minste til største eller vice-versa, eller sortering strenger lexicographically. Du kan selv definere dine egne kriterier, og vi vil gå inn i praktiske måter å gjøre det på ved slutten av denne artikkelen.,
Hvis du er interessert i hvordan sortering fungerer, vil vi dekke ulike algoritmer, ineffektiv, men intuitive løsninger, effektive algoritmer som faktisk er implementert i Java og andre språk.
Det finnes ulike sorterings-algoritmer, og de er ikke alle like effektive. Vi vil være å analysere sin tid kompleksitet for å sammenligne dem og se hvilke av dem som gjør det best.,
listen av algoritmer vil du lære her er på ingen måte uttømmende, men vi har samlet noen av de vanligste og mest effektive som skal hjelpe deg å komme i gang:
- Boble Sortere
- Innsetting Sortere
- Sorter Utvalget
- slå sammen Sortere
- Heapsort
- Quicksort
- Sortering i Java
Merk: Denne artikkelen vil ikke være å håndtere samtidige sortering, siden det er ment for nybegynnere.
Boble Sortere
Forklaring
Boble sortere fungerer ved å bytte tilstøtende elementer hvis de ikke er i ønsket rekkefølge., Denne prosessen gjentas fra begynnelsen av utvalg til alle elementene er i orden.
Vi vet at alle elementene er i orden når vi klarer å gjøre hele iterasjonen uten å bytte i det hele tatt, da alle elementer sammenlignet vi var i ønsket rekkefølge med deres tilstøtende elementer, og ved utvidelse, hele utvalg.
Her er fremgangsmåten for å sortere en array med tall fra minst til størst:
-
4 2 1 5 3: De to første elementene er i feil rekkefølge, så vi bytte dem.
-
2 4 1 5 3: De to elementene er i feil rekkefølge, så kan vi bytte.,
-
2 1 4 5 3: Disse to er i riktig rekkefølge, 4 < 5, så vi forlate dem alene.
-
2 1 4 5 3: Annen swap.
-
2 1 4 3 5: Her er den resulterende matrisen etter en iterasjon.
Fordi minst ett bytte skjedde i løpet av første pass (det var faktisk tre), vi trenger å gå gjennom hele matrisen igjen, og gjenta den samme prosessen.
Ved å gjenta denne prosessen, til det ikke er flere bytteavtaler er gjort, vil vi ha et sortert array.,
grunnen til At denne algoritmen kalles Boble-Sortering er fordi tallene slags «boble opp» til «overflaten.»Hvis du går gjennom vårt eksempel igjen, etter et bestemt antall (4 er et godt eksempel), vil du se at det sakte beveger seg til høyre under prosessen.
Alle tall flytte til sine respektive plasser bit for bit, fra venstre til høyre, som bobler sakte stiger opp fra en kropp av vann.
Hvis du ønsker å lese en detaljert, dedikert artikkel for Boble Sorter, vi har det du trenger!,
Implementering
Vi kommer til å gjennomføre Boble Sortere på en lignende måte som vi har lagt det ut i ord. Vår funksjon går en stund løkke som går gjennom hele matrisen bytte etter behov.
Vi anta at tabellen er sortert, men hvis vi er påvist feil mens sortering (hvis en swap skjer), skal vi gå gjennom en annen iterasjon. I while-løkken og holder det gående til vi klarer å passere gjennom hele matrisen uten å bytte:
Når du bruker denne algoritmen vi må være forsiktige med hvordan vi stat våre swap tilstand.,
For eksempel, hvis jeg hadde brukt a >= a det kunne ha endt opp med en uendelig løkke, fordi for like elementer dette forhold vil alltid være true, og dermed alltid bytte dem.
Tid Kompleksitet
for Å finne ut tid kompleksiteten av Boble Sorter, vi trenger å se på det verste tenkelige scenario. Hva er det maksimale antall ganger vi trenger å passere gjennom hele matrisen før vi har sortert det?, Tenk deg følgende eksempel:
5 4 3 2 1I den første iterasjonen, 5 vil «boble opp til overflaten,» men resten av elementene skulle bo i synkende rekkefølge. Vi ville ha å gjøre en iterasjon for hvert element, bortsett fra 1, og deretter en annen iterasjon for å sjekke at alt er i orden, slik at totalt 5 iterasjoner.
Utvide dette til et utvalg av n – elementer, og det betyr at du trenger å gjøre n iterasjoner., Se på koden, ville det bety at vår while loop kan kjøre maksimalt n ganger.
Hver av de n ganger vi iterating gjennom hele array (for-løkke i koden), som betyr verste fall tid kompleksitet ville være O(n^2).
Merk: tiden kompleksitet vil alltid være O(n^2) hvis det ikke var for sorted boolean sjekk, som avslutter algoritme hvis det ikke er noen bytteavtaler i indre sløyfe – noe som betyr at tabellen er sortert.,
Innsetting Sortere
Forklaring
ideen bak Innsetting Sorter er å dele utvalg i sortert og usortert subarrays.
Den sorterte delen av lengde 1 i begynnelsen og er tilsvarende den første (venstre -) element i matrisen. Vi iterere gjennom utvalget og i løpet av hver iterasjon, vi utvide den sorterte delen av tabellen med ett element.
Ved å utvide vi legger inn nye element inn i sin rette plass i den sorterte subarray. Vi gjør dette ved å flytte alle elementene til høyre til vi møter det første elementet vi trenger ikke å skifte.,
For eksempel, hvis du er i den følgende matrisen i fet skrift del er sortert i stigende rekkefølge, skjer følgende:
-
3 5 7 8 4 2 1 9 6: Vi tar 4 og husk at det er hva vi trenger å sette inn. Siden 8 > 4, vi shift.
-
3 5 7 x 8 2 1 9 6: Hvor verdien av x er ikke av avgjørende betydning, da det vil bli overskrevet umiddelbart (enten ved 4 hvis det er passende sted eller 7 hvis vi shift). Siden 7 > 4, vi shift.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Etter denne prosessen, sortert del ble utvidet med ett element, vi har nå fem snarere enn fire elementer. Hver iterasjon gjør dette, og ved slutten vil vi ha hele tabellen er sortert.
Hvis du ønsker å lese en detaljert, dedikert artikkel for Innsetting Sorter, vi har det du trenger!,
Implementering
Tid Kompleksitet
Igjen, må vi se på den verste tilfelle scenario for våre algoritmen, og det vil igjen være eksempel der hele matrisen er synkende.
Dette er fordi i hver iterasjon, er vi nødt til å flytte hele sortert liste og en, som er O(n). Vi må gjøre dette for hvert element i hver rekke, noe som betyr at det kommer til å bli avgrenset av O(n^2).
Sorter Utvalget
Forklaring
Sorter Utvalget også deler matrisen inn i en sortert og usortert subarray., Men, denne gangen, sortert subarray er dannet ved å sette inn minimum element av usortert subarray på slutten av sortert array, ved å bytte:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
Implementering
I hver iterasjon, antar vi at den første usortert element er den minste og iterere gjennom resten for å se om det er et mindre element.,
Når vi finner den gjeldende minimum av usortert del av tabellen, vil vi bytte den med det første elementet og anser det som en del av sortert array:
Tid Kompleksitet
Finne den minste er O(n) for lengden av tabellen fordi vi må sjekke alle elementene. Vi er nødt til å finne minimum for hvert element i matrisen, noe som gjør hele prosessen avgrenset av O(n^2).,
slå sammen Sortere
Forklaring
slå sammen Sortere bruker recursion å løse problemet med å sortere mer effektivt enn algoritmer tidligere presentert, og spesielt den bruker en splitt og hersk-tilnærming.
ved Hjelp av begge disse begrepene, vi vil bryte det hele matrisen ned i to subarrays og så:
- Sorter venstre halvdel av tabellen (med undermapper)
- Sorter høyre halvdel av tabellen (med undermapper)
- slå sammen løsningene
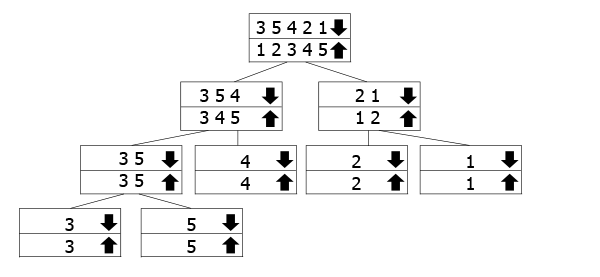
Dette treet er ment å representere hvordan rekursiv samtaler arbeid., De rekker som er merket med pil ned er de vi kaller funksjonen for, mens vi er sammenslåing pil opp-de kommer opp igjen. Så du følge pil ned til bunnen av treet, og så gå tilbake opp og slå sammen.
I vårt eksempel har vi matrisen 3 5 3 2 1, så vi dele det inn 3 5 4 og 2 1. For å sortere dem, kan vi videre dele dem inn i deres komponenter. Når vi har nådd bunnen, kan vi begynne å flette opp og sortere dem mens vi går.,
Hvis du ønsker å lese en detaljert, dedikert artikkelen for å slå sammen Sorter, vi har det du trenger!
Implementering
kjernen fungerer ganske mye som er lagt ut i forklaringen. Vi er bare passerer indekser left og right som er indekser av venstre-og høyre-mest element av subarray vi ønsker å sortere. I utgangspunktet skal disse være 0 og array.length-1, avhengig av gjennomføring.,
basen vår recursion sikrer vi avslutter når vi er ferdig, eller når right og left møte hverandre. Vi finn et midtpunkt mid, og sortere subarrays venstre og høyre for det, undermapper, til slutt slå sammen våre løsninger.
Hvis du husker våre tre grafiske, du lurer kanskje på hvorfor ikke vi å opprette to nye mindre matriser og passere dem på stedet. Dette er fordi på virkelig lange rekker, ville dette føre til enorme minneforbruket for noe som egentlig unødvendig.,
slå sammen Sortere allerede fungerer ikke på stedet på grunn av de slå sammen trinn, og dette ville bare tjene til å forverre sitt minne effektivitet. Logikken i våre tre av recursion ellers forblir den samme, men vi må bare følge de indeksene vi bruker:
for Å slå sammen sortert subarrays til ett, for vi trenger for å beregne lengden av hver og gjøre midlertidige rekker å kopiere dem inn, slik at vi kan fritt endre vår største utvalg.
Etter at du har kopiert, går vi gjennom den resulterende matrisen og tilordne den gjeldende minimum., Fordi våre subarrays er sortert, vi bare valgte det minste av to elementer som ikke er valgt så langt, og flytte iterator for at subarray fremover:
Tid Kompleksitet
Hvis vi ønsker å oppnå kompleksiteten av rekursive algoritmer, vi er nødt til å få litt mathy.
Master-Teoremet er brukt til å regne ut tiden kompleksiteten av rekursive algoritmer. For ikke-rekursive algoritmer, vi kan som regel skrive nøyaktig tid kompleksitet som noen form av en ligning, og så bruker vi Big-O Notasjon for å sortere dem inn i klasser på samme måte-de oppfører seg algoritmer.,
problemet med rekursive algoritmer er at den samme ligningen ville se noe som dette:
$$
T(n) = p(\frac{n}{b}) + cn^k
$$
ligningen i seg selv er rekursiv! I denne ligningen, a forteller oss hvor mange ganger vi kaller recursion, og b forteller oss inn i hvor mange deler vårt problem er delt. I denne saken som kan virke som en ubetydelig forskjell fordi de er like for mergesort, men for noen problemer, kan de ikke være.,
resten av ligningen er kompleksiteten i å slå sammen alle de løsningene til en på slutten., Master Teorem løser denne likningen for oss:
$$
T(n) = \Bigg\{
\begin{matrise}
O(n^{log_ba}), & en>b^k \\ O(n^klog n), & a = b^k \\ O(n^k), & en < b^k
\end{matrise}
$$
Hvis T(n) er kjøretiden til algoritmen når sortere en array av lengde n, Fusjonere Sortere ville kjøre to ganger for matriser som er halve lengden av den opprinnelige matrisen.,
Så hvis vi har a=2, b=2. Flettingen trinn tar O(n) – minnet, så k=1. Dette betyr at ligningen for Fusjonere Sortere ville se ut som følger:
$$
T(n) = 2T(\frac{n}{2})+cn
$$
Hvis vi bruke Master-Teoremet, vil vi se at vårt tilfelle er den ene der a=b^k fordi vi har 2=2^1. Det betyr at våre kompleksiteten er O(nlog n). Dette er en ekstremt god tid kompleksitet for en sortering algoritme, siden det har blitt bevist at en matrise kan ikke sorteres noe raskere enn O(nlog n).,
Mens den versjonen vi har vist frem er minne tidkrevende, det er mer kompliserte versjoner av Merge Sorter som tar opp bare O(1) plass.
I tillegg, algoritmen er svært enkelt å parallelize, siden rekursiv anrop fra en node kan kjøres helt uavhengig av separate grener. Selv om vi ikke komme inn på hvordan og hvorfor, da det er utenfor omfanget av denne artikkelen, er det verdt å huske på fordeler av å bruke denne bestemt algoritme.,
Heapsort
Forklaring
for Å riktig forstå hvorfor Heapsort fungerer, må du først forstå strukturen er basert på haugen. Vi vil snakke i forhold til en binær haugen spesielt, men du kan generalisere det meste av dette til andre haugen strukturer, så vel.
En heap er et tre som tilfredsstiller haugen eiendom, som er at for hver node, alle sine barn er i et gitt forhold til det. I tillegg, en haug må være nesten fullstendig., En nesten komplett binære trær av dybde d har en undertreet av dybde d-1 med samme rot som er fullført, og der hver node med en venstre etterkommer har en komplett venstre undertreet. Med andre ord, når du legger til en node, vi går alltid for venstre posisjon i høyeste ufullstendig nivå.
Hvis haugen er en max-heap, så alle barn er mindre enn foreldrene, og hvis det er en min-heap alle av dem er større.,
med andre ord, når du flytter ned treet, du får mindre og mindre tall (min-heap) eller større og større antall (maks-haug). Her er et eksempel på en max-haugen:
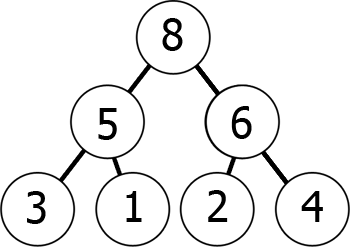
Vi kan representere denne max-haugen i minnet som en matrise på følgende måte:
8 5 6 3 1 2 4Du kan forestille det som å lese fra grafen nivå etter nivå, fra venstre til høyre., Hva vi har oppnådd med dette er at hvis vi tar den kth – element i matrisen, sine barns posisjoner er 2*k+1 og 2*k+2 (forutsatt indeksering starter på 0). Du kan sjekke dette for deg selv.
Omvendt, for kth – element foreldrenes posisjon er alltid (k-1)/2.
å Vite dette, kan du enkelt «maks-heapify» en gitt matrise. For hvert element, kan du sjekke om noen av deres barn er mindre enn det., Hvis de er, bytte en av dem med foreldre, og undermapper gjenta dette trinnet med foreldrene (fordi den nye store element kan fortsatt være større enn andre barn).
Bladene har ingen barn, så de er trivially max-hauger av sine egne:
-
6 1 8 3 5 2 4: Både barn er mindre enn foreldrene, slik at alt forblir den samme.
-
6 1 8 3 5 2 4: Fordi 5 > 1, vi bytte dem. Vi undermapper heapify for 5 nå.
-
6 5 8 3 1 2 4: Både av barn er mindre, så skjer det ingenting.,
-
6 5 8 3 1 2 4: Fordi 8 > 6, vi bytte dem.
-
8 5 6 3 1 2 4: Vi fikk haugen bildet ovenfor!
Når vi har lært å heapify en rekke resten er ganske enkel. Vi swap roten av haugen med slutten av tabellen, og redusere matrisen ved en.,
Vi heapify forkortet utvalg på nytt, og gjenta prosessen:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: byttet
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: byttet
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: byttet
Og så på, jeg er sikker på at du kan se mønster fremvoksende.
Implementering
Tid Kompleksitet
Når vi ser på heapify() funksjon, alt ser ut til å være gjort i O(1), men så er det at pesky rekursive kall.,
Hvor mange ganger vil det være kalt, i verste tilfelle scenario? Vel, worst-case, det vil formere seg hele veien til toppen av haugen. Det vil gjøre det ved å hoppe til foreldrene i hver node, så hele posisjon i/2. det betyr at det vil gjøre i verste fall logg n hopp før den når toppen, så kompleksiteten er O(log n).
Fordi heapSort() er klart O(n) på grunn av for-løkker iterating gjennom hele matrisen, ville dette gjøre den totale kompleksiteten av Heapsort O(nlog n).,
Heapsort er et in-sted sorter, noe som betyr at det tar O(1) ekstra plass, i motsetning til å Flette Sortere, men det har noen ulemper, så vel som å være vanskelig å parallelize.
Quicksort
Forklaring
Quicksort er en annen splitt og Hersk-algoritmen. Den plukker ett element i en matrise som pivot og sorterer alle de andre elementene rundt det, for eksempel mindre elementer til venstre, og større til høyre.
Dette garanterer at pivot er på sin rette plass når prosessen., Deretter algoritmen undermapper gjør det samme for venstre og høyre deler av tabellen.
Implementering
Tid Kompleksitet
Den tid kompleksiteten av Quicksort kan uttrykkes med følgende ligning:
$$
T(n) = T(k) + T(n-k-1) + O(n)
$$
Den verste tilfelle scenario er når den største eller minste elementet er alltid plukket ut til pivot. Ligningen vil da se ut som dette:
$$
T(n) = T(0) + T(n-1) + O(n) = T(n-1) + O(n)
$$
Dette viser seg å være O(n^2).,
Dette kan høres ille, som vi allerede har lært flere algoritmer som kjører i O(nlog n) tid som sine verste fall, men Quicksort er faktisk veldig mye brukt.
Dette er fordi den har en veldig god gjennomsnittlig kjøretid, også avgrenset av O(nlog n), og er svært effektivt for en stor del av mulige innganger.
En av grunnene til at det er foretrukket å Fusjonere Sorter er at det ikke tar noen ekstra plass, alle sortering er utført på stedet, og det er ikke dyrt tildeling og deallocation anrop.,
Ytelse Sammenligning
At alt blir sagt, det er ofte nyttig å kjøre alle disse algoritmene på maskinen din et par ganger for å få en idé om hvordan de utfører.
De vil utføre forskjellig med ulike samlinger som blir sortert selvfølgelig, men selv med det i tankene, bør du være i stand til å legge merke til noen trender.
La oss kjøre alle implementeringer, en etter en, hver på en kopi av et tilfeldig utvalg på 10 000 heltall:
Vi kan tydelig se at Boble-Sortering er den verste når det kommer til ytelse., Unngå å bruke den i produksjon hvis du ikke kan garantere at det vil håndtere bare små samlinger og det vil ikke stoppe programmet.
HeapSort og QuickSort er den beste ytelse-messig. Selv om de er å gi ut lignende resultater, QuickSort har en tendens til å bli litt bedre og mer konsistent – som sjekker ut.
Sortering i Java
Sammenlignbare Grensesnitt
Hvis du har dine egne typer, det kan bli tungvint å implementere en egen sortering algoritme for hver og en. Det er derfor Java gir et grensesnitt slik at du kan bruke Collections.sort() på dine egne klasser.,
for Å gjøre dette, klassen må implementere Comparable<T> grensesnitt, der T er din type, og kan overstyre en metode som kalles .compareTo().
Denne metoden returnerer et negativt heltall hvis this er mindre enn argumentet element, 0 hvis de er like, og et positivt heltall hvis this er større.
I vårt eksempel har vi laget en klasse Student, og hver student er identifisert av en id og et år de startet sine studier.,
Vi ønsker å sortere dem først og fremst av generasjoner, men også sekundært ved Id:
Og her er hvordan du skal bruke det i en søknad:
Output:
Interface Comparator
Vi kan være lurt å sortere våre objekter i en uortodoks måte for et bestemt formål, men vi ønsker ikke å implementere det som standard oppførsel i klassen vår, eller vi kan være å sortere en samling av en innebygd skriver i en ikke-standard måte.
For dette, kan vi bruke Comparator grensesnitt., For eksempel, la oss ta vår Student klasse, og liksom bare ved ID:
Hvis vi erstatte den typen samtale viktigste med følgende:
Arrays.sort(a, new SortByID());Output:
Hvordan det Hele Fungerer
Collection.sort() fungerer ved å ringe det underliggende Arrays.sort() metode, mens sortering selv bruker Innsetting Form for matriser kortere enn 47, og Quicksort for resten.,
Det er basert på en spesifikk to-pivot gjennomføring av Quicksort som sikrer at man unngår de fleste av de typiske årsaker til nedbrytning i kvadratiske ytelse, i henhold til JDK10 dokumentasjon.
Konklusjon
Sortering er en svært vanlig drift med datasett, enten det er for å analysere dem videre, raskere søk ved å bruke mer effektive algoritmer som er avhengige av data som blir sortert, filtrere data, etc.
Sortering er støttet av mange språk og grensesnitt ofte skjule hva som faktisk skjer til programmereren., Mens denne abstraksjon er velkommen og nødvendig for effektivt arbeid, kan det noen ganger være dødelig for effektivitet, og det er godt å vite hvordan å implementere ulike algoritmer og bli kjent med sine fordeler og ulemper, samt hvordan du enkelt kan få tilgang til bygget-i-implementeringer.