En sannsynlighet sampling metoden er en metode for prøvetaking som bruker noen form for tilfeldig utvalg. For å få et tilfeldig utvalg-metoden, må du sette opp en prosess eller en prosedyre som sikrer at de ulike enhetene i populasjonen har samme sannsynlighet for å bli valgt. Mennesker har lenge praktisert ulike former for tilfeldig utvalg, slik som å velge et navn ut av en lue, eller ved å velge kort strå. I disse dager, vi har en tendens til å bruke datamaskiner som mekanisme for å generere tilfeldige tall som grunnlag for tilfeldig utvalg.,
Noen Definisjoner
Før jeg kan forklare de ulike sannsynlighet metoder vi har for å definere noen grunnleggende begreper. Disse er:
-
Ner antall tilfeller i prøvetaking frame -
ner nummeret av sakene i utvalget -
NCn= antall kombinasjoner (undergrupper) avnfraN -
f = n/Ner sampling brøkdel
det er det., Med de betingelsene som er definert vi kan begynne å definere de ulike sannsynlighet for prøvetaking metoder.
Simple Random Sampling
Den enkleste formen for tilfeldig utvalg kalles simple random sampling. Ganske vanskelig, ikke sant? Her er en rask beskrivelse av enkel tilfeldig utvalg:
- Mål: for Å velge
nenheter ut avNslik at hverNCnhar en lik sjanse for å bli valgt. - Prosedyre: Bruker en tabell av tilfeldige tall, en datamaskin tilfeldig nummer generator, eller en mekanisk enhet for å velge prøven.,
En litt oppstyltet, hvis nøyaktige definisjonen. La oss se om vi kan gjøre det litt mer virkelig.

Hvordan kan vi velge et enkelt tilfeldig utvalg? La oss anta at vi har gjort noen undersøkelser med en liten service byrå som ønsker å vurdere klientenes utsikt over kvaliteten på tjenesten i løpet av siste år. Først må vi få prøvetaking ramme organisert. For å oppnå dette, vil vi gå gjennom byrå poster for å identifisere hver klient i løpet av de siste 12 måneder. Hvis vi er heldige, har byrået god nøyaktige datastyrt poster og kan raskt produsere en slik liste., Da må vi faktisk utvalgstrekkingen. Bestemme på antall klienter du ønsker å ha i den endelige prøven. På grunn av eksempel, la oss si at du ønsker å velge 100 klienter til undersøkelsen og at det var 1000 kunder i løpet av de siste 12 måneder. Deretter prøvetaking brøkdel er f = n/N = 100/1000 = .10 (eller 10%). Nå, til å faktisk trekke eksempel, har du flere alternativer. Du kan skrive ut listen over 1000 kunder, rive deretter inn i separate strimler, legg strimlene i en lue, bland dem opp virkelig bra, lukke øynene og trekke ut de første 100., Men denne mekanisk prosedyre ville være kjedelig og kvaliteten på prøven vil avhenge av hvor grundig har du blandet dem opp og tilfeldig hvordan du kom frem til i. Kanskje en bedre fremgangsmåte ville være å bruke den type ball maskin som er populære med mange av de statlige lotterier. Ville du trenger tre sett med baller nummerert fra 0 til 9, ett sett for hver av tallene fra 000 til 999 (hvis vi velger 000 vi kaller det 1000)., Antall listen over navn fra 1 til 1000 og deretter bruke ballen maskinen til å velge tre tall som velger hver person. Den åpenbare ulempen her er at du trenger å få ballen maskiner. (Hvor skal de gjøre disse ting, likevel? Er det en ball maskin-bransjen?).
ingen av disse mekaniske prosedyrer er veldig mulig, og med utvikling av rimelige datamaskiner er det en mye enklere måte. Her er en enkel prosedyre som er spesielt nyttig hvis du har navn av kunder som allerede finnes på datamaskinen., Mange programmer kan generere en serie med tilfeldige tall. La oss anta at du kan kopiere og lime inn listen over klient navn på en kolonne i et regneark i EXCEL. Deretter, i kolonnen til høyre ved siden av den lim inn funksjonen =RAND() som EXCEL måte å sette et tilfeldig tall mellom 0 og 1 i cellene. Deretter sortere både kolonner – listen over navn og tilfeldig nummer – av tilfeldige tall. Dette ordner listen i tilfeldig rekkefølge fra laveste til høyeste tilfeldig tall., Deretter er alt du trenger å gjøre er å ta de første hundre navn i denne sortert liste. ganske enkelt. Du kan sikkert oppnå det hele på under et minutt.
Enkelt tilfeldig utvalg er enkle å gjennomføre, og er lett å forklare til andre. Fordi simple random sampling er en rettferdig måte å å velge en prøve, er det rimelig å generalisere resultatene fra prøven tilbake til befolkningen. Enkelt tilfeldig utvalg er ikke den mest statistisk effektiv metode for prøvetaking og du kan, nettopp på grunn av flaks for uavgjort, og ikke få god representasjon av undergrupper i befolkningen., For å håndtere disse problemene, må vi ty til andre metoder for prøvetaking.
Stratifisert Tilfeldig utvalg på
Stratifisert Tilfeldig utvalg, også noen ganger kalt proporsjonal eller kvote random sampling, innebærer å dele befolkningen inn i homogene undergrupper, og så ta et enkelt tilfeldig utvalg i hver undergruppe. I mer formelle vilkår:
Det er flere viktige grunner til hvorfor du kanskje foretrekke stratifisert sampling over enkelt tilfeldig utvalg., For det første, det sikrer at du vil være i stand til å representere ikke bare den generelle befolkningen, men også viktige undergrupper av befolkningen, spesielt små minoritetsgrupper. Hvis du ønsker å være i stand til å snakke om undergrupper, kan dette være den eneste måten å effektivt forsikrer deg at du vil være i stand til. Hvis undergruppen er svært liten, kan du bruke forskjellige prøvetaking fraksjoner (f) innenfor de ulike strata til tilfeldig over-eksempel den lille gruppen (selv om du da har å vekt innen-gruppe estimater ved hjelp av prøvetaking brøkdel når du vil generelle befolkningen estimater)., Når vi bruker de samme prøvetaking brøkdel innen strata vi gjennomfører forholdsmessig stratifisert tilfeldig utvalg. Når vi bruker ulike prøvetaking fraksjoner i lag, vi kaller denne uforholdsmessig stratifisert tilfeldig utvalg. For det andre, stratifisert tilfeldig utvalg vil generelt ha mer statistisk presisjon enn enkelt tilfeldig utvalg. Dette vil bare være oppfylt hvis de lag eller grupper som er homogene. Hvis de er, kan vi forvente at variasjonen innen gruppene er lavere enn variasjonen for befolkningen som helhet. Stratifisert sampling kapitaliserer på det faktum.,
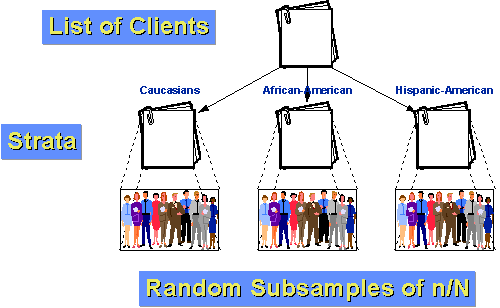
For eksempel, la oss si at bestanden av klienter for vårt byrå kan deles inn i tre grupper: Europerer, Afrikansk-Amerikansk og Spansk-Amerikanske. Videre, la oss anta at både afroamerikanere og Spansktalende Amerikanere er relativt små minoriteter av klientellet (10% og 5% henholdsvis)., Hvis vi bare hadde et enkelt tilfeldig utvalg av n=100 med et utvalg brøkdel av 10%, ville vi forvente ved en tilfeldighet alene at vi ville bare få 10 og 5 personer fra hver av våre to mindre grupper. Og, ved en tilfeldighet, at vi kunne få færre enn det! Hvis vi stratify, vi kan gjøre bedre. Først, la oss finne ut hvor mange mennesker vi ønsker å ha i hver gruppe. La oss si at vi fortsatt ønsker å ta en prøve av 100 fra en populasjon på 1000 kunder i løpet av det siste året. Men vi tror at for å kunne si noe om undergrupper vi trenger minst 25 tilfeller i hver gruppe., Så, la oss prøve 50 Kaukasiere, 25 Afrikansk-Amerikanere, og 25 Hispanic-Amerikanere. Vi vet at 10% av befolkningen, eller 100 klienter, er Afrikansk-Amerikansk. Hvis vi tilfeldig eksempel 25 av disse, vi har innen-stratum prøvetaking brøkdel av 25/100 = 25%. På samme måte vet vi at 5% eller 50 klienter Hispanic-Amerikansk. Så vår innen stratum prøvetaking brøkdel vil være 25/50 = 50%. Til slutt, ved subtraksjon vi vet at det er 850 Kaukasiske kunder. Våre innen stratum prøvetaking brøkdel for dem er 50/850 = about 5.88%., Fordi gruppene er mer homogen innen-gruppen enn i hele befolkningen som helhet, kan vi forvente en større statistisk presisjon (mindre varians). Og fordi vi stratifisert, vi vet at vi vil ha nok saker fra hver gruppe for å gjøre meningsfulle undergruppe slutninger.,e er fremgangsmåten du må følge for å oppnå et systematisk tilfeldig utvalg:
- antall enheter i populasjonen fra
1tilN - utarbeide
n(eksempel størrelse) som du ønsker eller trenger -
k = N/n= intervallet størrelse - tilfeldig velg et heltall mellom
1tilk - ta deretter hver
kthenhet

Alle av dette vil være mye klarere med et eksempel., La oss anta at vi har en befolkning som bare har N=100 mennesker i det, og at du ønsker å ta en prøve med n=20. Å bruke systematisk sampling, befolkningen, må være oppført i tilfeldig rekkefølge. Prøvetaking brøkdel ville være f = 20/100 = 20%. i dette tilfellet, intervall størrelse, k, er lik N/n = 100/20 = 5. Nå, velger du et tilfeldig heltall fra 1 to 5. I vårt eksempel, tenk deg at du valgte 4., Nå, for å velge eksempel, bør du begynne med 4th enhet i listen, og tar alle k-th enhet (hver 5., fordi k=5). Du ville være prøvetaking enheter 4, 9, 14, 19, og så videre til 100 og du vil ende opp med 20 enheter i ditt eksempel.
For at dette skal fungere, er det viktig at enhetene i populasjonen er tilfeldig bestilt, minst med hensyn til de egenskapene du måler. Hvorfor ville du noen gang ønsker å bruke systematisk tilfeldig utvalg? For én ting, det er ganske enkelt å gjøre. Du trenger bare å velge en enkelt tilfeldig tall for å starte ting av., Det kan også være mer presis enn enkelt tilfeldig utvalg. Til slutt, i noen situasjoner det er rett og slett ingen enklere måte å gjøre tilfeldig utvalg. For eksempel, når jeg hadde å gjøre en studie som involverte prøvetaking fra alle bøkene i et bibliotek. Når du har valgt, ville jeg ha for å gå til hylle, finn boken, og ta opp når det siste sirkulert. Jeg visste at jeg hadde et ganske godt utvalg ramme i form av sokkelen listen (som er en kort katalogen hvor oppføringene er ordnet i den rekkefølge de forekommer på sokkelen)., For å gjøre et enkelt tilfeldig utvalg, kunne jeg ha estimert totalt antall bøker og genererte tilfeldige tall for å tegne eksempel; men hvordan skulle jeg finne bestill #74,329 lett hvis det er tall jeg har valgt? Jeg kunne ikke veldig godt telle kort før jeg kom til 74,329! Stratifying ikke ville løse det problemet heller. For eksempel, jeg kunne ha stratifisert med kortkatalog skuffen og trekkes et enkelt tilfeldig utvalg innenfor hver skuff. Men jeg vil fortsatt være fast telle kort. I stedet gjorde jeg et systematisk tilfeldig utvalg. Jeg estimert antall bøker i hele samlingen. La oss forestille seg at det var 100,000., Jeg bestemte meg for at jeg ønsket å ta en prøve av 1000 for et utvalg brøkdel av 1000/100,000 = 1%. For å få sampling interval k jeg delt N/n = 100,000/1000 = 100. Så jeg valgte et tilfeldig heltall mellom 1 og 100. La oss si at jeg fikk 57.
Neste, jeg gjorde en liten side studie for å finne ut hvor tykk tusen kortene er i kortkatalog (ta hensyn til det varierende alder på kortene)., La oss si at i gjennomsnitt fant jeg ut at to kort som var adskilt med 100 kortene var om .75 inches hverandre i katalogen skuff. Denne informasjonen ga meg alt jeg trengte for å trekke utvalget. Jeg teller til 57th hånd og registrert i telefonboken. Så, jeg tok et kompass. (Husker dem fra high-school matematikk klasse? De er morsomme lille metall instrumenter med en skarp pinne i den ene enden og en blyant på den andre som du brukte til å tegne sirkler i geometri klasse.,) Så stiller jeg inn kompasset på .75", fast pin slutten på 57th kort og pekte med blyant ende til neste kort (ca 100 bøker unna). På denne måten, jeg rundet velge 157th, 257th, 357th, og så videre. Jeg var i stand til å utføre hele utvalget prosedyre i svært lite tid å bruke dette systematisk tilfeldig utvalg tilnærming. Jeg vil nok fortsatt være det å telle kort hvis jeg hadde prøvd en annen random sampling metoden. (Ok, så jeg har ikke noe liv. Jeg fikk kompensert pent, jeg har ikke noe imot å si, for å komme opp med denne ordningen.,)
Klynge (Område) Random Sampling
problemet med tilfeldig utvalg metoder når vi har for eksempel en befolkning som er utbetalt over et stort geografisk område, er at du blir nødt til å dekke mye av grunnen geografisk for å få til hver av enhetene du har samplet. Tenk deg å ta et enkelt tilfeldig utvalg av alle innbyggere i Staten New York for å gjennomføre personlige intervjuer. Av flaks for uavgjort, vil du ende opp med respondentene som kommer fra hele staten. Din intervjuere kommer til å ha mye reising å gjøre., Det er nettopp dette problemet som klynge eller området tilfeldig utvalg ble oppfunnet.
I cluster sampling, vi følger du disse trinnene:
- dele befolkningen inn i grupper (vanligvis langs geografiske grenser)
- tilfeldig eksempel klynger
- måle alle enheter innenfor utvalgte klynger
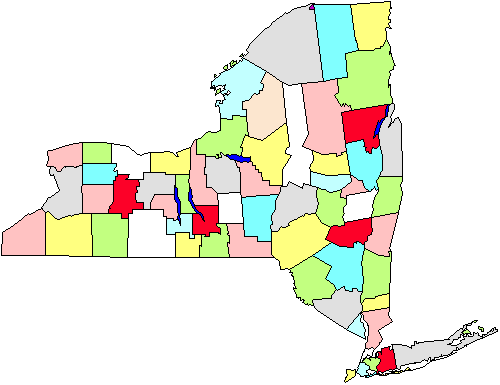
For eksempel, i figuren ser vi et kart over fylker i Staten New York. La oss si at vi har å gjøre en undersøkelse av byen regjeringer som vil kreve av oss at vi kommer til å byene personlig., Hvis vi gjør et enkelt tilfeldig utvalg state-wide vi nødt til å dekke hele staten geografisk. I stedet, vi bestemmer oss for å gjøre et cluster sampling av fem fylker (markert med rødt i figuren). Når dette er valgt, går vi til hver by regjering i fem områder. Klart denne strategien vil hjelpe oss til å økonomisere på våre kjørelengde. Klynge eller området sampling, så er nyttig i situasjoner som dette, og gjøres først og fremst for effektivisering av administrasjonen., Vær også oppmerksom på, at vi trolig trenger ikke å bekymre deg om å bruke denne metoden hvis vi gjennomfører en e-post eller telefon undersøkelsen fordi det ikke saken så mye (eller koste mer eller høyne ineffektivitet) hvor vi kan ringe eller sende brev til.
Multi-Stage Prøvetaking
De fire metodene vi har dekket så langt – enkle, stratifisert, systematisk og cluster – er den enkleste tilfeldig utvalg strategier. I de fleste virkelige applied social research, ville vi bruke prøvetaking metoder som er betydelig mer komplekse enn disse enkle varianter., Den mest viktig prinsipp her er at vi kan kombinere de enkle metodene som er beskrevet tidligere i en rekke nyttige metoder som hjelper oss å løse våre prøvetaking behov i den mest effektiv og effektiv måte som mulig. Når vi kombinerer prøvetaking metoder, kaller vi dette en multi-trinns utvalg.
For eksempel, tenk deg tanken på prøvetaking innbyggere i Staten New York for ansikt-til-ansikt intervjuer. Klart vi ønsker å gjøre noe type av cluster sampling som første trinn i prosessen. Vi kan prøve kommune eller census trakter i hele staten., Men i cluster sampling vi vil deretter gå videre til å måle alle i klynger vi velger. Selv om vi er sampling census traktater kan vi ikke være i stand til å måle alle som er i folketellingen skrift. Så, vi kan sette opp en stratifisert sampling prosess i klynger. I dette tilfellet, ville vi ha en to-trinns prøvetaking prosessen med stratifisert prøver innenfor klyngen prøver. Eller, vurdere problemet for prøvetaking elevene i klasse skoler. Vi kan begynne med et nasjonalt utvalg av skolekretser stratifisert med økonomi og utdanningsnivå., Innenfor utvalgte distrikter, kan vi gjøre et enkelt tilfeldig utvalg av skoler. I skolene, kan vi gjøre et enkelt tilfeldig utvalg av klasser eller karakterer. Og, i klasser, kan vi selv gjøre en enkel tilfeldig utvalg av studenter. I dette tilfellet har vi tre eller fire stadier i innsamlingsprosessen og vi bruker både stratifisert og enkelt tilfeldig utvalg. Ved å kombinere ulike metoder for prøvetaking vi er i stand til å oppnå et rikt utvalg av statistiske metoder for prøvetaking som kan brukes i et bredt spekter av sosiale forskning sammenhenger.