og dens implementering i Python
I denne bloggen vi ‘vil prøve å grave dypere inn i Random Forest Taksonomi. Her vil vi lære om ensemble læring, og vil prøve å gjennomføre det ved hjelp av Python.,
Du kan finne koden over her.
Det er et ensemble treet-basert læring algoritme. Random Forest Classifier er et sett av nøkler fra tilfeldig valgte delmengde av trening sett. Det aggregater stemmer fra forskjellige nøkler til å bestemme den endelige klasse av testen objekt.
Ensemble Algoritme :
Ensemble algoritmer er de som kombinerer mer enn én algoritmer av samme eller annen form for klassifisering av objekter. For eksempel, kjører prediksjon over Naive Bayes, SVM og Beslutning om Treet, og så ta stemme for endelig vurdering av klasse for test objekt.,

Types of Random Forest models:
1. Random Forest Prediction for a classification problem:
f(x) = majority vote of all predicted classes over B trees
2.,n :


The 9 decision tree classifiers shown above can be aggregated into a random forest ensemble which combines their input (on the right)., De horisontale og vertikale aksene av de ovennevnte avgjørelse tre utganger som kan være tenkt som har x1 og x2. På visse verdier av hver enkelt funksjon, beslutningen om tre utganger en klassifisering av «blue», «green», «rød», osv.
Disse ovennevnte resultatene er samlet, gjennom modellen stemmer eller gjennomsnitt, til en enkelt
ensemble modell som ender opp med å utklasse alle enkeltvedtak treet utgang.
Funksjoner og Fordeler av Tilfeldige Skog :
- Det er en av de mest nøyaktige læring algoritmer tilgjengelig. For mange datasett, det gir en svært nøyaktig classifier.,
- Det kjører effektivt på store databaser.
- Det kan håndtere tusenvis av input-variabler uten variabel sletting.
- Det gir estimater av hvilke variabler som er viktige i klassifiseringen.
- Det genererer en intern objektive anslag for generalisering feil som skogen bygning utvikler seg.
- Det har en effektiv metode for å estimere manglende data og opprettholder nøyaktighet når en stor andel av de data som mangler.,
Ulemper av Tilfeldige Skog :
- Tilfeldig skoger har blitt observert å overfit for noen datasett med støy klassifisering/regresjon oppgaver.
- For data, inkludert kategoriske variabler med ulikt antall nivåer, tilfeldig skog er partisk i favør av disse attributtene med flere nivåer. Derfor variabel betydning score fra random forest er ikke pålitelig for denne type data.,div>
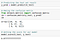
Creating a Random Forest Classification model and fitting it to the training data

Predicting the test set results and making the Confusion matrix
Conclusion :
In this blog we have learned about the Random forest classifier and its implementation., Vi så på ensembled læring algoritme i aksjon, og prøvde å forstå hva som gjør Random Forest annen form andre algoritmer for maskinlæring.