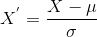Introduksjon til Funksjonen Skalering
jeg var nylig arbeider med et dataset som hadde flere funksjoner som spenner over ulike grader av størrelse, rekkevidde og enheter. Dette er en betydelig hindring som noen maskinlæring algoritmer er svært sensitive for disse funksjonene.
jeg er sikker på at de fleste av dere må ha møtt dette problemet i ditt prosjekt eller din reise for å lære., For eksempel, en funksjon som er helt i kilo, mens den andre er i gram, en annen er liter, og så videre. Hvordan kan vi bruke disse funksjonene når de varierer så mye i forhold til hva de er å presentere?
Dette er hvor jeg viste til konseptet med funksjonen skalering. Det er en avgjørende del av data preprosessering scenen, men jeg har sett mange nybegynnere har utsikt over det (til skade på maskinen sin læringsmodell).,

Her er den nysgjerrige ting om funksjonen skalering – det bedrer (betydelig) ytelsen av noen algoritmer for maskinlæring og fungerer ikke i det hele tatt for andre. Hva kan være grunnen til at bak denne egenskap?
Også, hva er forskjellen mellom normalisering og standardisering? Disse er to av de mest brukte funksjonen skalering teknikker i maskinlæring men en grad av tvetydighet som eksisterer i deres forståelse. Når bør du bruke som teknikk?,
jeg vil svare på disse spørsmålene og mer i denne artikkelen på funksjonen skalering. Vi vil også implementere funksjonen skalering i Python for å gi deg en praksis forståelse av hvordan det fungerer for ulike algoritmer for maskinlæring.
Merk: jeg antar at du er kjent med Python og core maskinlæring algoritmer., Hvis du er ny til dette, anbefaler jeg å gå gjennom under kurs:
- Python for Data Vitenskap
- Alle gratis Machine Learning Kurs ved Analytics Vidhya
- Brukt maskinlæring
Innholdsfortegnelse
– >
- Hvorfor Skal vi Bruke Funksjonen Skalering?
- Hva er Normalisering?
- Hva er Standardisering?
- Det Store Spørsmålet – Normalisere eller Standardisere?,
- Gjennomføre Funksjonen Skalering i Python
- Normalisering ved hjelp av Sklearn
- Standardisering ved hjelp av Sklearn
- å Anvende Funksjonen Skalering å maskinlæring Algoritmer
- K-Nærmeste Naboer (KNN)
- Support Vector Regressor
- Avgjørelse Treet
Hvorfor Skal vi Bruke Funksjonen Skalering?
Det første spørsmålet vi må ta – hvorfor trenger vi å skalere variabler i vårt datasett? Noen algoritmer for maskinlæring er følsomme for funksjonen skalering, mens andre er tilnærmet upåvirkede til det., La meg forklare det nærmere.
Gradient Nedstigningen Basert Algoritmer
algoritmer for maskinlæring som lineær regresjon, logistisk regresjon, nevrale nettverk, etc. som bruker gradient avstamning som en optimalisering av teknikk krever data for å skaleres. Ta en titt på formelen for gradient nedstigningen nedenfor:

tilstedeværelsen av funksjonen verdien X i formelen vil påvirke trinn størrelse på gradient avstamning. Forskjellen i områder av funksjoner vil føre til ulike trinn størrelser for hver funksjon., For å sikre at overgangen nedstigningen går jevnt mot minima, og at fremgangsmåten for gradient nedstigningen er oppdatert til samme pris for alle funksjoner, kan vi skalere data før du mater den til modellen.
etter å Ha funksjoner på en lignende skala kan hjelpe gradient nedstigningen konvergerer raskere mot minima.
Avstand-Baserte Algoritmer
Avstand algoritmer som KNN, K-means, og SVM er mest påvirket av de spekter av funksjoner., Dette er fordi bak kulissene de bruker avstander mellom datapunkter for å bestemme deres likhet.
For eksempel, la oss si at vi har data som inneholder high school CGPA score av studenter (alt fra 0 til 5) og deres fremtidige inntekter (i hele tusen Kroner):

Siden begge funksjonene har forskjellige skalaer, det er en sjanse for at høyere weightage er gitt til funksjoner med høyere styrke. Dette vil påvirke ytelsen til maskinen læring algoritme, og selvsagt, vi ønsker ikke at våre algoritmen for å være biassed mot én funksjon.,
Derfor, vi skala våre data før ansette en avstand basert algoritme, slik at alle funksjoner bidrar like mye til resultatet.,nts A og B, og mellom B og C, før og etter skalering som vist nedenfor:
- Avstand AB før skalering =>

- Avstanden BC før skalering =>

- Avstand AB etter skalering =>

- Avstanden BC etter skalering =>

Skalering har brakt både funksjoner inn i bildet, og avstandene er nå mer sammenlignbare enn de var før vi brukt skalering.,
Treet-Baserte Algoritmer
Treet-baserte algoritmer, på den annen side, er ganske ufølsom for omfanget av funksjoner. Tenk på det, en beslutning treet er bare dele en node basert på en enkelt funksjon. Vedtaket tre deler en node på en funksjon som øker homogenitet av noden. Dette delt på en funksjon som ikke er påvirket av andre funksjoner.
Så, det er praktisk talt ingen effekt av resten av funksjonene på split. Dette er hva som gjør dem invariant til omfanget av funksjoner!
Hva er Normalisering?,
Normalisering er en skalering teknikk i hvilke verdier er flyttet og rescaled slik at de ender opp som varierer mellom 0 og 1. Det er også kjent som Min-Maks skalering.
Her er formelen for normalisering:
Her, Xmax og Xmin er maksimum og minimum verdier av funksjonen henholdsvis.,
- Når verdien av X er den minste verdien i kolonnen, telleren vil være 0, og dermed X’ er 0
- På den annen side, når verdien av X er den maksimale verdien i kolonnen, telleren er lik nevneren og dermed verdien av X’ er 1
- Hvis verdien av X er mellom minimum og maksimum verdi, da verdien av X’ er mellom 0 og 1
Hva er Standardisering?
Standardisering er en annen skalering teknikk der verdiene er sentrert rundt de mener med en enhet standardavvik., Dette betyr at gjennomsnittet av attributtet blir null, og den resulterende fordelingen har en enhet standardavvik.
Her er formelen for standardisering:
er gjennomsnittet av funksjonen verdier og
er standardavviket til den funksjonen verdier. Merk at i dette tilfellet, verdiene er ikke begrenset til et bestemt område.
Nå, det store spørsmålet i tankene dine må være når vi skal bruke normalisering og når bør vi bruke standardisering? La oss finne ut!,
Det Store Spørsmålet – Normalisere eller Standardisere?
Normalisering vs. standardisering er et evig spørsmål blant maskinlæring nykommere. La meg utdype svaret i denne delen.
- Normalisering er god å bruke når du vet at fordelingen av dine data ikke følge en Gaussisk fordeling. Dette kan være nyttig i algoritmer som ikke anta noen distribusjon av data som K-Nærmeste Naboer og Nevrale Nettverk.
- Standardisering, på den annen side, kan være nyttig i tilfeller der data følger en Gaussisk fordeling., Men dette betyr ikke nødvendigvis sant. Også, i motsetning til normalisering, standardisering har ikke former en sammenhengende spekter. Så, selv om du har uteliggere i data, vil de ikke bli påvirket av standardisering.
Men på slutten av dagen, kan du velge å bruke normalisering eller standardisering vil være avhengig av ditt problem og maskinlæring algoritmen du bruker. Det er ingen fast regel for å fortelle deg når du skal normalisere eller standardisere data., Du kan alltid starte ved å montere modellen for å være rå, normalisert og standardiserte data og sammenligne resultatene for best resultat.
Det er en god praksis å passe scaler på trening data og deretter bruke den til å forvandle testing data. Dette ville unngå eventuelle data lekkasje i løpet av modellen testing prosessen. Også, skalering av mål-verdiene er vanligvis ikke nødvendig.
Implementere Funksjonen Skalering i Python
Nå kommer den morsomme delen – å sette det vi har lært i praksis., Jeg vil bruke funksjonen skalering for å få maskinen læring algoritmer på den Store Mart dataset jeg har tatt DataHack plattform.
jeg vil hoppe over forbehandling trinnene siden de er utenfor omfanget av denne opplæringen. Men du kan finne dem pent forklart i denne artikkelen. Disse trinnene vil gjøre deg i stand til å nå topp 20-persentilen på hackathon leaderboard, så det er verdt å sjekke ut!
Så, la oss først delt våre data til trening og testing sett:
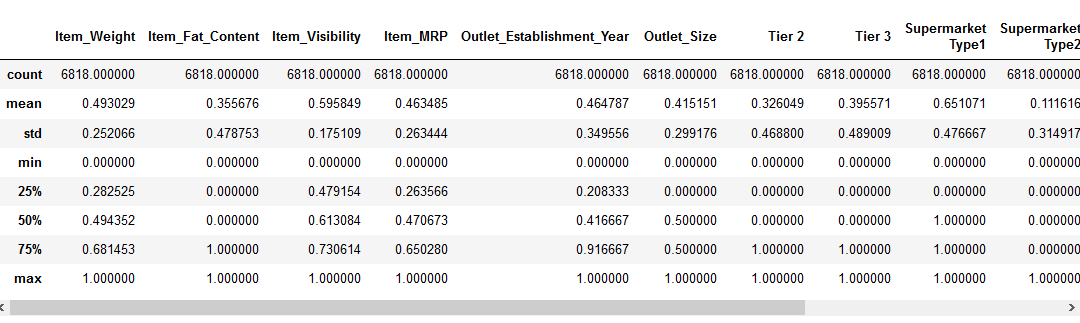
Før du flytter til funksjonen skalering del, la oss se på detaljene om våre data ved hjelp av pd.,beskrive () – metoden:
Vi kan se at det er en stor forskjell i omfanget av verdier til stede i vår numeriske funksjoner: Item_Visibility, Item_Weight, Item_MRP, og Outlet_Establishment_Year. La oss prøve og fikse det ved hjelp av funksjonen skalering!
Merk: Du vil legge merke til negative verdier i Item_Visibility funksjon fordi jeg har tatt log-transformasjon for å håndtere frafallsskjevhet i funksjon.
Normalisering ved hjelp av sklearn
for Å normalisere dine data, må du importere MinMaxScalar fra sklearn bibliotek og bruke den til vårt datasett., Så, la oss gjøre det!
La oss se hvordan normalisering har påvirket vår dataset:
Alle funksjonene nå har minimumsverdien 0 og maksimumsverdien av 1. Perfekt!
Prøv ut koden ovenfor i live koding vinduet nedenfor!!
Neste, la oss prøve å standardisere våre data.
Standardisering ved hjelp av sklearn
for Å standardisere data, må du importere StandardScalar fra sklearn bibliotek og bruke den til vårt datasett., Her er hvordan du kan gjøre det:
Du ville ha lagt merke til at jeg bare brukt standardisering til min numeriske kolonner og ikke de andre One-Hot Kodet funksjoner. Standardisere One-Hot kodet funksjoner ville bety å tilordne en distribusjon til kategoriske funksjoner. Du ønsker ikke å gjøre det!
Men hvorfor gjorde jeg ikke gjør det samme mens normalisere data? Fordi One-Hot kodet funksjoner er allerede i området mellom 0 og 1. Så, normalisering ikke ville påvirke deres verdi.,
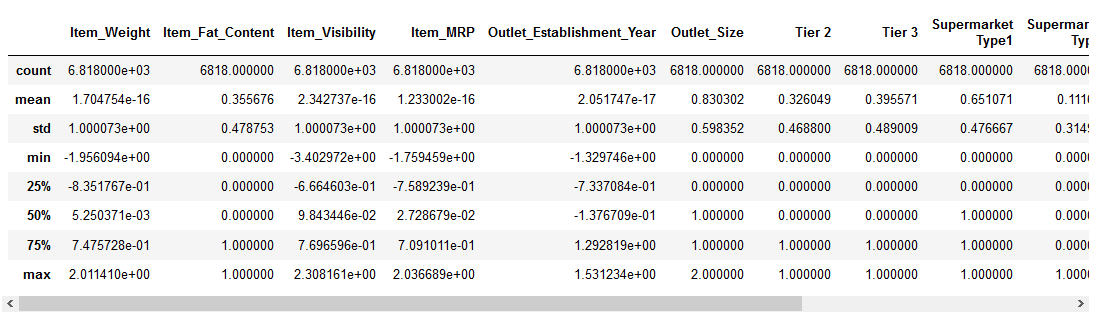
Rett, la oss ta en titt på hvordan standardisering har forvandlet våre data:
Den numeriske funksjoner er nå sentrert på gjennomsnittet med en enhet standardavvik. Fantastisk!
Sammenligne unscaled, normalisert og standardiserte data
Det er alltid flott å visualisere dine data for å forstå fordelingen til stede. Vi kan se sammenligningen mellom vår unscaled og graderte data ved hjelp av boxplots.
Du kan lære mer om data visualisering her.,
Du kan legge merke til hvordan skalering funksjonene bringer alt i perspektiv. Funksjonene er nå mer sammenlignbare og vil ha en lignende effekt på læring modeller.
Søker Skalering å maskinlæring Algoritmer
Det er nå tid for å trene noen algoritmer for maskinlæring på våre data å sammenligne effekten av ulike skalering teknikker på ytelsen til algoritmen. Jeg ønsker å se effekten av skalering på tre algoritmer spesielt: K-Nærmeste Naboer, Support Vector Regressor, og Vedtak Treet.,
K-Nærmeste Naboer
Som vi har sett før, KNN er en avstand-basert algoritme som er berørt av spekter av funksjoner. La oss se hvordan det utfører på våre data, før og etter skalering:
Du kan se at skalering funksjonene har brakt ned RMSE resultat av vår KNN modell. Spesielt, den normaliserte data utfører en tad litt bedre enn de standardiserte data.
Merk: jeg er måling av RMSE her fordi denne konkurransen vurderer RMSE.
Support Vector Regressor
SVR er en annen avstand-basert algoritme., Så la oss sjekke ut om det fungerer bedre med normalisering eller standardisering:
Vi kan se at skalering funksjonene gjør få ned RMSE score. Og standardiserte data har gjort det bedre enn de normaliserte data. Hvorfor tror du dette er tilfelle?
sklearn dokumentasjon som sier at SVM, med RBF-kjernen, forutsetter at alle funksjonene er sentrert rundt null og varians er av samme størrelsesorden. Dette er fordi en funksjon med et avvik større enn den andre hindrer estimator fra læring fra alle de funksjoner., Flott!
Avgjørelse Treet
Vi allerede vet at en Beslutning om treet er invariant til funksjonen skalering. Men jeg ønsket å vise et praktisk eksempel på hvordan den klarer seg på de data:
Du kan se at RMSE score har ikke flyttet seg en tomme på skalering funksjonene. Så trygg når du bruker treet-algoritmer basert på data!,
Avslutt Notater
Denne opplæringen dekket relevansen av å bruke funksjonen skalering på dine data og hvordan normalisering og standardisering har ulike effekter på arbeider av maskinlæring algoritmer
husk at det er ingen riktige svar på når du skal bruke normalisering over standardisering og vice-versa. Det hele avhenger av dine data, og de algoritmen du bruker.
Som et neste trinn, oppfordrer jeg deg til å prøve ut funksjonen skalering med andre algoritmer og finne ut hva som fungerer best – normalisering eller standardisering?, Jeg anbefaler at du bruker den BigMart Salg av data for at formålet å opprettholde kontinuitet med denne artikkelen. Og ikke glem å dele innsikt i kommentarfeltet nedenfor!
Du kan også lese denne artikkelen om vår Mobil-APP