e la sua implementazione in Python
In questo blog si ‘ll cercare di scavare più in profondità nella Foresta Casuale Tassonomia. Qui impareremo a conoscere l’apprendimento di ensemble e cercheremo di implementarlo usando Python.,
Puoi trovare il codice qui.
È un algoritmo di apprendimento basato su un albero di ensemble. Il classificatore di foresta casuale è un insieme di alberi decisionali dal sottoinsieme selezionato casualmente del set di allenamento. Aggrega i voti da diversi alberi decisionali per decidere la classe finale dell’oggetto di test.
Algoritmo di ensemble:
Gli algoritmi di ensemble sono quelli che combinano più algoritmi dello stesso tipo o diversi per classificare gli oggetti. Ad esempio, eseguendo la previsione su Naive Bayes, SVM e Albero decisionale e quindi prendendo il voto per l’esame finale della classe per l’oggetto di test.,

Types of Random Forest models:
1. Random Forest Prediction for a classification problem:
f(x) = majority vote of all predicted classes over B trees
2.,n :


The 9 decision tree classifiers shown above can be aggregated into a random forest ensemble which combines their input (on the right)., Gli assi orizzontale e verticale delle uscite dell’albero decisionale sopra possono essere pensati come caratteristiche x1 e x2. A determinati valori di ciascuna caratteristica, l’albero delle decisioni emette una classificazione di ” blu”, “verde”, “rosso”, ecc.
Questi risultati di cui sopra sono aggregati, attraverso i voti del modello o la media, in un singolo
modello di ensemble che finisce per sovraperformare l’output di qualsiasi singolo albero decisionale.
Caratteristiche e vantaggi di Random Forest:
- È uno degli algoritmi di apprendimento più accurati disponibili. Per molti set di dati, produce un classificatore altamente accurato.,
- Funziona in modo efficiente su database di grandi dimensioni.
- E ‘ in grado di gestire migliaia di variabili di input senza cancellazione variabile.
- Fornisce stime di quali variabili sono importanti nella classificazione.
- Genera una stima interna imparziale dell’errore di generalizzazione mentre l’edificio forestale progredisce.
- Ha un metodo efficace per stimare i dati mancanti e mantiene la precisione quando manca una grande percentuale dei dati.,
Svantaggi della foresta casuale:
- È stato osservato che le foreste casuali si adattano troppo per alcuni set di dati con compiti di classificazione / regressione rumorosi.
- Per i dati che includono variabili categoriali con diverso numero di livelli, le foreste casuali sono prevenute a favore di quegli attributi con più livelli. Pertanto, i punteggi di importanza variabile della foresta casuale non sono affidabili per questo tipo di dati.,div>
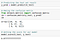
Creating a Random Forest Classification model and fitting it to the training data

Predicting the test set results and making the Confusion matrix
Conclusion :
In this blog we have learned about the Random forest classifier and its implementation., Abbiamo esaminato l’algoritmo di apprendimento integrato in azione e abbiamo cercato di capire cosa rende la Foresta casuale diversa da altri algoritmi di apprendimento automatico.