Quanti geni ci sono in un genoma?
Modalità lettore
Abbiamo già esaminato la grande diversità nelle dimensioni del genoma in tutto il mondo vivente (vedi Tabella nella vignetta su ” Quanto sono grandi i genomi?”). Come primo passo per affinare la nostra comprensione del contenuto informativo di questi genomi, abbiamo bisogno di un senso del numero di geni che ospitano. Quando ci riferiamo ai geni penseremo a geni codificanti proteine escludendo la collezione in continua espansione di regioni codificanti RNA nei genomi.,
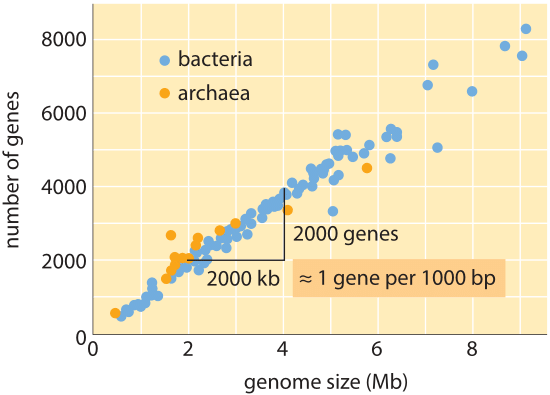
Figura 1: Numero di geni in funzione della dimensione del genoma. La figura mostra i dati per una varietà di batteri e archaea, con la pendenza della linea di dati che conferma la semplice regola empirica relativa dimensione del genoma e il numero di geni. (Adattato da M. Lynch, Le origini dell’architettura del genoma.,)
al di Sopra di tutto l’albero della vita, anche se genoma di dimensioni differire anche di 8 ordini di grandezza (da <2 kb per il virus dell’Epatite D virus (BNID 105570) >100 Gbp per il Marmo lungfish (BNID 100597) e di alcuni Fritillaria fiori (BNID 102726)), l’intervallo del numero di geni varia da meno di 5 ordini di grandezza (da virus come MS2 e QB batteriofagi avendo solo 4 geni per circa un centinaio di migliaia di grano). Molti batteri hanno diverse migliaia di geni., Questo contenuto genico è proporzionale alla dimensione del genoma e alla dimensione della proteina come mostrato di seguito. È interessante notare che i genomi eucariotici, che sono spesso mille volte o più grandi di quelli dei procarioti, contengono solo un ordine di grandezza più geni rispetto alle loro controparti procariote. L’incapacità di stimare con successo il numero di geni negli eucarioti in base alla conoscenza del contenuto genico dei procarioti è stata una delle svolte inaspettate della biologia moderna.,
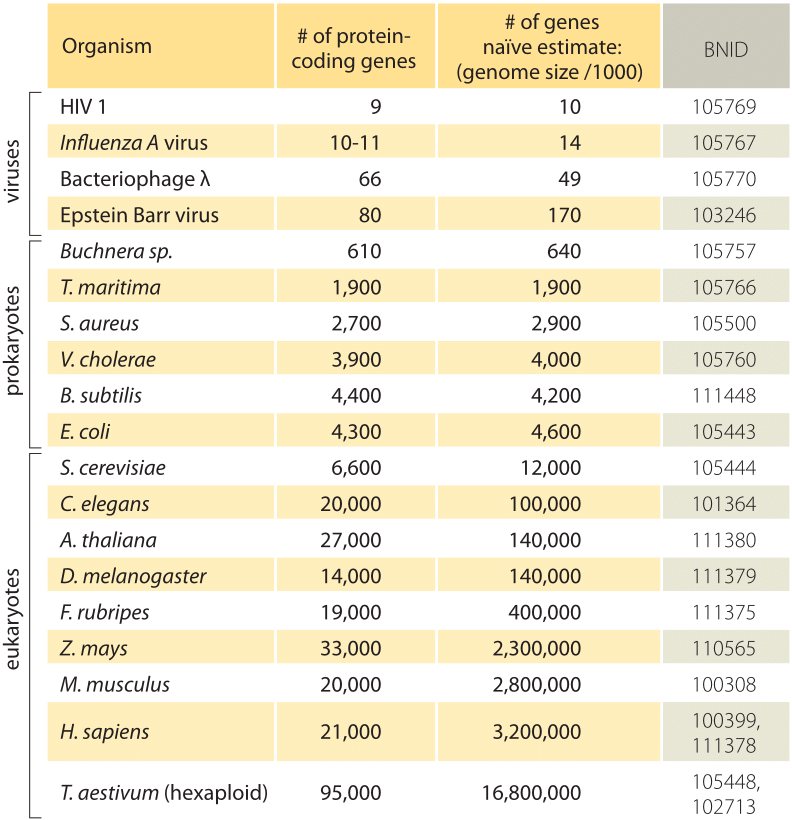
Tabella 1: Un confronto tra il numero di geni in un organismo e una stima naïve basata sulla dimensione del genoma diviso per un fattore costante di 1000bp/gene, cioè numero previsto di geni = dimensione del genoma / 1000. Si scopre che questa regola approssimativa funziona sorprendentemente bene per molti batteri e archaea, ma fallisce miseramente per gli organismi multicellulari.
La stima più semplice del numero di geni in un genoma si svolge assumendo che la totalità dei codici del genoma per i geni di interesse., Fare ulteriori progressi con la stima, abbiamo bisogno di avere una misura del numero di amminoacidi in una tipica proteina che si intende adottare per essere circa 300, consapevoli però del fatto che, come genomi, le proteine sono disponibili in una varietà di dimensioni, viene rivelato nella vignetta sull’argomento: ”quali sono le dimensioni delle proteine?”. Sulla base di questo magro assunto, vediamo che il numero di basi necessarie per codificare la nostra proteina tipica è di circa 1000 (3 coppie di basi per aminoacido)., Quindi, all’interno di questa mentalità, il numero di geni contenuti in un genoma è stimato essere la dimensione del genoma/1000. Per i genomi batterici, questa strategia funziona sorprendentemente bene come si può vedere nella tabella 1 e Figura 1. Ad esempio, quando applicato all’E. coli K-12, genoma di 4,6 x 106 bp, questa regola empirica porta a una stima di 4600 geni, che possono essere confrontati con l’attuale migliore conoscenza di questa quantità che è 4225. Nel passare attraverso una dozzina di batteri rappresentativi e genomi arcaici nella tabella si osserva un potere predittivo altrettanto sorprendente entro circa il 10%., D’altra parte, questa strategia fallisce in modo spettacolare quando la applichiamo ai genomi eucariotici, risultando ad esempio nella stima che il numero di geni nel genoma umano dovrebbe essere 3.000.000, una sovrastima grossolana. L’inaffidabilità di questa stima aiuta a spiegare l’esistenza del pool di scommesse Genesweep che recentemente, nei primi anni 2000, aveva persone che scommettevano sul numero di geni nel genoma umano, con stime delle persone che variavano di oltre un fattore dieci.,
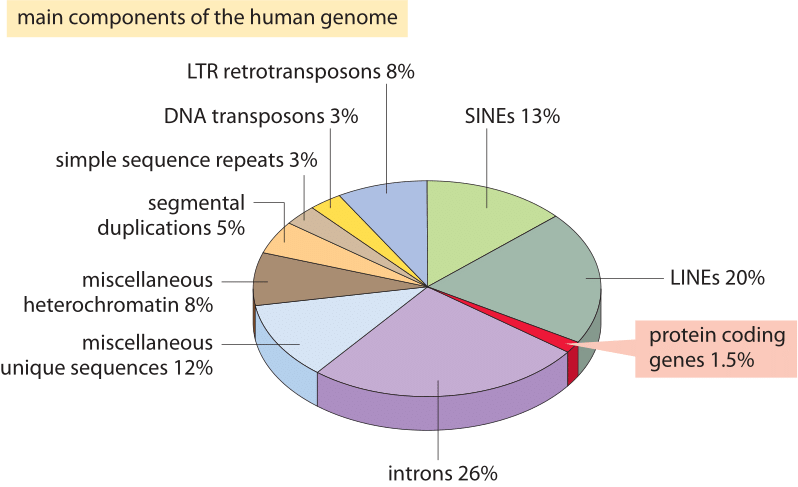
Figura 2: I diversi componenti della sequenza che compongono il genoma umano. Circa l ‘ 1,5% del genoma è costituito dalle ≈20.000 sequenze codificanti proteine che sono intervallate dagli introni non codificanti, costituendo circa il 26%. Gli elementi trasponibili sono la frazione più grande (40-50%) tra cui ad esempio elementi nucleari intervallati lunghi (linee) e elementi nucleari intervallati corti (SINEs). La maggior parte degli elementi trasponibili sono resti genomici, che sono attualmente defunti. (BNID 110283, Adattato da T. R. Gregory Nat Rev Genet., 9: 699-708, 2005 basato sul Consorzio internazionale di sequenziamento del genoma umano. Sequenziamento iniziale e analisi del genoma umano. Natura 409:860 2001.)
Cosa spiega questo spettacolare fallimento della stima più ingenua e cosa ci insegna sulle informazioni organizzate nei genomi? I genomi eucariotici, in particolare quelli associati agli organismi multicellulari, sono caratterizzati da una serie di caratteristiche intriganti che interrompono la semplice immagine di codifica sfruttata nella stima naïve., Queste differenze nell’uso del genoma sono raffigurate in modo pittorico nella Figura 2 che mostra la percentuale del genoma utilizzato per scopi diversi dalla codifica proteica. Come evidente nella Figura 1, i procarioti possono compattare in modo efficiente le loro sequenze codificanti proteine in modo tale che siano quasi continue e risultino in meno del 10% dei loro genomi assegnati a DNA non codificante (12% in E. coli, BNID 105750) mentre negli esseri umani oltre il 98% (BNID 103748) non codifica proteine.,
La scoperta di questi altri usi del genoma costituiscono alcune delle più importanti intuizioni del DNA, e della biologia più in generale, degli ultimi 60 anni. Uno di questi usi alternativi per gli immobili genomici è il genoma regolatorio, vale a dire, il modo in cui grandi pezzi del genoma sono utilizzati come obiettivi per il legame delle proteine regolatorie che danno origine al controllo combinatorio così tipico dei genomi negli organismi multicellulari., Un’altra delle caratteristiche chiave dei genomi eucariotici è l’organizzazione dei loro geni in introni ed esoni, con gli esoni espressi che sono molto più piccoli degli introni interventisti e impiombati. Oltre a queste caratteristiche, ci sono retrovirus endogeni, reliquie fossili di precedenti infezioni virali e sorprendentemente, oltre il 50% del genoma è occupato dall’esistenza di elementi ripetuti e trasposoni, varie forme di cui possono forse essere interpretate come geni egoisti che hanno meccanismi per proliferare in un genoma ospite., Alcuni di questi elementi ripetitivi e trasposoni sono ancora attivi oggi, mentre altri sono rimasti una reliquia dopo aver perso la capacità di proliferare ulteriormente nel genoma.
In conclusione, i genomi possono essere suddivisi in due classi principali: compatto ed espansivo. I primi sono gene denso, con solo circa il 10% della regione non codificante e rigorosa proporzionalità tra dimensione del genoma e numero del genoma. Questo gruppo si estende a genomi di dimensioni fino a circa 10 Mbp, che coprono virus, batteri, archaea e alcuni eucarioti unicellulari., Quest’ultima classe non mostra una chiara correlazione tra dimensione del genoma e numero di geni, è composta principalmente da elementi non codificanti e copre tutti gli organismi multicellulari.




