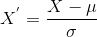Introduzione a Feature Scaling
Recentemente stavo lavorando con un set di dati con più funzionalità che coprono vari gradi di grandezza, intervallo e unità. Questo è un ostacolo significativo in quanto alcuni algoritmi di apprendimento automatico sono altamente sensibili a queste funzionalità.
Sono sicuro che la maggior parte di voi deve aver affrontato questo problema nei vostri progetti o il vostro viaggio di apprendimento., Ad esempio, una caratteristica è interamente in chilogrammi mentre l’altra è in grammi, un’altra è litri e così via. Come possiamo usare queste funzionalità quando variano così enormemente in termini di ciò che stanno presentando?
Questo è dove mi sono rivolto al concetto di ridimensionamento delle funzionalità. È una parte cruciale della fase di pre-elaborazione dei dati, ma ho visto molti principianti trascurarlo (a scapito del loro modello di apprendimento automatico).,

Ecco la cosa curiosa del ridimensionamento delle funzionalità: migliora (significativamente) le prestazioni di alcuni algoritmi di apprendimento automatico e non funziona affatto per gli altri. Quale potrebbe essere la ragione dietro questa stranezza?
Inoltre, qual è la differenza tra normalizzazione e standardizzazione? Queste sono due delle tecniche di ridimensionamento delle funzionalità più comunemente utilizzate nell’apprendimento automatico, ma esiste un livello di ambiguità nella loro comprensione. Quando dovresti usare quale tecnica?,
Risponderò a queste domande e altro in questo articolo sul ridimensionamento delle funzionalità. Implementeremo anche il ridimensionamento delle funzionalità in Python per darti una comprensione pratica di come funziona per diversi algoritmi di apprendimento automatico.
Nota: presumo che tu abbia familiarità con gli algoritmi di apprendimento automatico Python e core., Se sei nuovo a questo, ti consiglio di seguire i corsi seguenti:
- Python per la scienza dei dati
- Tutti i corsi gratuiti di apprendimento automatico di Analytics Vidhya
- Applied Machine Learning
Sommario
- Perché dovremmo usare il ridimensionamento delle funzionalità?
- Che cos’è la normalizzazione?
- Che cos’è la standardizzazione?
- La grande domanda: normalizzare o standardizzare?,
- l’Implementazione di Funzionalità di Ridimensionamento in Python
- Normalizzazione utilizzando Sklearn
- Standardizzazione utilizzando Sklearn
- Applicazione di Funzione di Scaling di Algoritmi di Machine Learning
- K-Nearest Neighbours (KNN)
- Supporto Vettoriale Regressore
- Albero di Decisione
Perché Dovremmo Utilizzare la Funzione di Scaling?
La prima domanda che dobbiamo affrontare – perché abbiamo bisogno di scalare le variabili nel nostro set di dati? Alcuni algoritmi di apprendimento automatico sono sensibili al ridimensionamento delle funzionalità mentre altri sono praticamente invarianti., Mi permetta di spiegare che in modo più dettagliato.
Algoritmi basati sulla discesa del gradiente
Algoritmi di apprendimento automatico come regressione lineare, regressione logistica, rete neurale, ecc. che utilizzano la discesa del gradiente come tecnica di ottimizzazione richiedono che i dati vengano ridimensionati. Dai un’occhiata alla formula per la discesa del gradiente qui sotto:

La presenza del valore della caratteristica X nella formula influenzerà la dimensione del passo della discesa del gradiente. La differenza di intervalli di caratteristiche causerà diverse dimensioni di passo per ogni caratteristica., Per garantire che la discesa del gradiente si muova senza intoppi verso i minimi e che i passaggi per la discesa del gradiente siano aggiornati alla stessa velocità per tutte le funzionalità, ridimensioniamo i dati prima di inviarli al modello.
Avere caratteristiche su una scala simile può aiutare la discesa del gradiente a convergere più rapidamente verso i minimi.
Algoritmi basati sulla distanza
Gli algoritmi di distanza come KNN, K-means e SVM sono maggiormente influenzati dalla gamma di funzionalità., Questo perché dietro le quinte stanno usando le distanze tra i punti dati per determinare la loro somiglianza.
Ad esempio, diciamo che abbiamo dati contenenti punteggi CGPA delle scuole superiori di studenti (che vanno da 0 a 5) e le loro entrate future (in migliaia di rupie):

Poiché entrambe le caratteristiche hanno scale diverse, c’è la possibilità che un peso maggiore sia dato a caratteristiche con grandezza maggiore. Ciò avrà un impatto sulle prestazioni dell’algoritmo di apprendimento automatico e, ovviamente, non vogliamo che il nostro algoritmo sia distorto verso una caratteristica.,
Pertanto, scaliamo i nostri dati prima di utilizzare un algoritmo basato sulla distanza in modo che tutte le funzionalità contribuiscano ugualmente al risultato.,nts A e B e tra B e C, prima e dopo il ridimensionamento, come illustrato di seguito:
- Distanza AB prima di scalare =>

- Distanza BC prima di scalare =>

- Distanza AB dopo la scalatura =>

- Distanza BC dopo la scalatura =>

Scala ha portato entrambe le caratteristiche in foto e le distanze sono ora più simili di quanto non fossero prima abbiamo applicato la scala.,
Algoritmi ad albero
Gli algoritmi ad albero, d’altra parte, sono abbastanza insensibili alla scala delle caratteristiche. Pensaci, un albero decisionale sta dividendo solo un nodo in base a una singola funzionalità. L’albero delle decisioni divide un nodo su una caratteristica che aumenta l’omogeneità del nodo. Questa divisione su una caratteristica non è influenzata da altre caratteristiche.
Quindi, non vi è praticamente alcun effetto delle funzionalità rimanenti sulla divisione. Questo è ciò che li rende invarianti alla scala delle caratteristiche!
Che cos’è la normalizzazione?,
La normalizzazione è una tecnica di ridimensionamento in cui i valori vengono spostati e ridimensionati in modo che finiscano per variare tra 0 e 1. È anche noto come ridimensionamento Min-Max.
Ecco la formula per la normalizzazione:

Qui, Xmax e Xmin sono rispettivamente i valori massimi e minimi della funzione.,
- Quando il valore di X è il valore minimo della colonna, il numeratore sarà 0, e quindi X’ 0
- d’altra parte, quando il valore di X è il valore massimo della colonna, il numeratore è uguale al denominatore e quindi il valore di X’ è 1
- Se il valore di X è compreso tra il minimo e il valore massimo, quindi il valore di X è compreso tra 0 e 1
che Cosa è la Standardizzazione?
La standardizzazione è un’altra tecnica di ridimensionamento in cui i valori sono centrati attorno alla media con una deviazione standard unitaria., Ciò significa che la media dell’attributo diventa zero e la distribuzione risultante ha una deviazione standard unitaria.
Ecco la formula per la standardizzazione:
è la media dei valori di funzionalità e
è la deviazione standard dei valori di funzionalità. Si noti che in questo caso, i valori non sono limitati a un particolare intervallo.
Ora, la grande domanda nella tua mente deve essere quando dovremmo usare la normalizzazione e quando dovremmo usare la standardizzazione? Scopriamolo!,
La grande domanda: normalizzare o standardizzare?
La normalizzazione rispetto alla standardizzazione è una domanda eterna tra i nuovi arrivati di apprendimento automatico. Permettetemi di approfondire la risposta in questa sezione.
- La normalizzazione è buona da usare quando sai che la distribuzione dei tuoi dati non segue una distribuzione gaussiana. Questo può essere utile in algoritmi che non assumono alcuna distribuzione dei dati come K-Vicini più vicini e Reti neurali.
- La standardizzazione, d’altra parte, può essere utile nei casi in cui i dati seguono una distribuzione gaussiana., Tuttavia, questo non deve essere necessariamente vero. Inoltre, a differenza della normalizzazione, la standardizzazione non ha un intervallo di delimitazione. Quindi, anche se hai valori anomali nei tuoi dati, non saranno influenzati dalla standardizzazione.
Tuttavia, alla fine della giornata, la scelta di utilizzare la normalizzazione o la standardizzazione dipenderà dal problema e dall’algoritmo di apprendimento automatico che si sta utilizzando. Non esiste una regola dura e veloce per dirti quando normalizzare o standardizzare i tuoi dati., Puoi sempre iniziare adattando il tuo modello a dati grezzi, normalizzati e standardizzati e confrontare le prestazioni per ottenere i migliori risultati.
È una buona pratica adattare lo scaler ai dati di allenamento e quindi utilizzarlo per trasformare i dati di test. Ciò eviterebbe qualsiasi perdita di dati durante il processo di test del modello. Inoltre, il ridimensionamento dei valori target non è generalmente richiesto.
Implementare il ridimensionamento delle funzionalità in Python
Ora arriva la parte divertente: mettere in pratica ciò che abbiamo imparato., Applicherò il ridimensionamento delle funzionalità ad alcuni algoritmi di apprendimento automatico sul set di dati Big Mart che ho preso la piattaforma DataHack.
Salterò i passaggi di pre-elaborazione poiché sono fuori dallo scopo di questo tutorial. Ma puoi trovarli ben spiegati in questo articolo. Questi passaggi vi permetterà di raggiungere la cima 20 percentile sulla classifica hackathon così che vale la pena di verificare!
Quindi, prima dividiamo i nostri dati in set di allenamento e test:
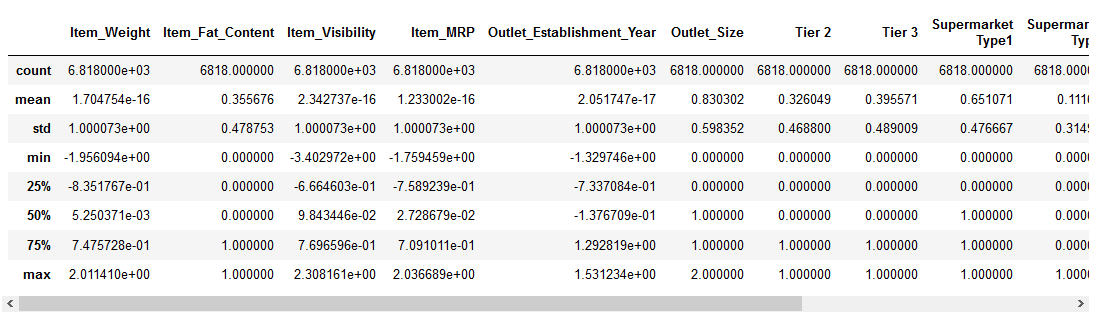
Prima di passare alla parte di ridimensionamento delle funzionalità, diamo un’occhiata ai dettagli sui nostri dati usando il pd.,describe () method:

Possiamo vedere che c’è un’enorme differenza nell’intervallo di valori presenti nelle nostre caratteristiche numeriche: Item_Visibility, Item_Weight, Item_MRP e Outlet_Establishment_Year. Proviamo a risolvere il problema usando il ridimensionamento delle funzionalità!
Nota: Noterai valori negativi nella funzione Item_Visibility perché ho preso log-transformation per gestire l’asimmetria nella funzione.
Normalizzazione utilizzando sklearn
Per normalizzare i dati, è necessario importare il MinMaxScalar dalla libreria sklearn e applicarlo al nostro set di dati., Quindi, facciamolo!
Vediamo come la normalizzazione ha influenzato il nostro set di dati:
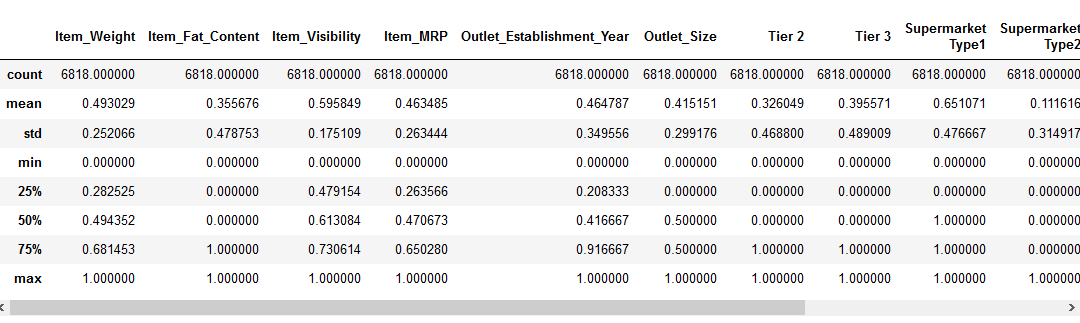
Tutte le funzionalità hanno ora un valore minimo di 0 e un valore massimo di 1. Perfetto!
Prova il codice di cui sopra nella finestra live coding qui sotto!!
Quindi, proviamo a standardizzare i nostri dati.
Standardizzazione utilizzando sklearn
Per standardizzare i dati, è necessario importare lo StandardScalar dalla libreria sklearn e applicarlo al nostro set di dati., Ecco come puoi farlo:
Avresti notato che ho applicato solo la standardizzazione alle mie colonne numeriche e non alle altre funzionalità codificate a caldo. Standardizzare le funzionalità codificate a caldo significherebbe assegnare una distribuzione alle funzionalità categoriali. Non vuoi farlo!
Ma perché non ho fatto lo stesso mentre normalizzavo i dati? Perché le funzionalità codificate a caldo sono già comprese tra 0 e 1. Quindi, la normalizzazione non influenzerebbe il loro valore.,
Giusto, diamo un’occhiata a come la standardizzazione ha trasformato i nostri dati:
Le caratteristiche numeriche sono ora centrate sulla media con una deviazione standard unitaria. Fantastico!
Confrontando dati non scalati, normalizzati e standardizzati
È sempre bello visualizzare i dati per comprendere la distribuzione presente. Possiamo vedere il confronto tra i nostri dati non ridimensionati e scalati utilizzando boxplots.
Puoi saperne di più sulla visualizzazione dei dati qui.,

Puoi notare come il ridimensionamento delle funzionalità porta tutto in prospettiva. Le caratteristiche sono ora più comparabili e avranno un effetto simile sui modelli di apprendimento.
Applicare il ridimensionamento agli algoritmi di apprendimento automatico
È giunto il momento di addestrare alcuni algoritmi di apprendimento automatico sui nostri dati per confrontare gli effetti delle diverse tecniche di ridimensionamento sulle prestazioni dell’algoritmo. Voglio vedere l’effetto del ridimensionamento su tre algoritmi in particolare: K-Neighbours, Support Vector Regressor e Decision Tree.,
K-Neighbours
Come abbiamo visto prima, KNN è un algoritmo basato sulla distanza che è influenzato dalla gamma di funzionalità. Vediamo come funziona sui nostri dati, prima e dopo il ridimensionamento:

Puoi vedere che il ridimensionamento delle funzionalità ha ridotto il punteggio RMSE del nostro modello KNN. In particolare, i dati normalizzati eseguono un po ‘ meglio dei dati standardizzati.
Nota: sto misurando l’RMSE qui perché questa competizione valuta l’RMSE.
Supporto regressore vettoriale
SVR è un altro algoritmo basato sulla distanza., Quindi controlliamo se funziona meglio con la normalizzazione o la standardizzazione:

Possiamo vedere che ridimensionare le funzionalità riduce il punteggio RMSE. E i dati standardizzati hanno funzionato meglio dei dati normalizzati. Perche ‘pensi che sia cosi’?
La documentazione di sklearn afferma che SVM, con il kernel RBF, presuppone che tutte le funzionalità siano centrate attorno a zero e che la varianza sia dello stesso ordine. Questo perché una caratteristica con una varianza maggiore di quella degli altri impedisce allo stimatore di imparare da tutte le caratteristiche., Forte!
Albero delle decisioni
Sappiamo già che un albero delle decisioni è invariante al ridimensionamento delle funzionalità. Ma volevo mostrare un esempio pratico di come si comporta sui dati:

Puoi vedere che il punteggio RMSE non si è spostato di un pollice sul ridimensionamento delle funzionalità. Quindi stai tranquillo quando usi algoritmi basati su alberi sui tuoi dati!,
Note finali
Questo tutorial ha riguardato la rilevanza dell’utilizzo del ridimensionamento delle funzionalità sui dati e il modo in cui la normalizzazione e la standardizzazione hanno effetti diversi sul funzionamento degli algoritmi di apprendimento automatico
Tieni presente che non esiste una risposta corretta a quando utilizzare la normalizzazione rispetto alla standardizzazione e viceversa. Tutto dipende dai tuoi dati e dall’algoritmo che stai utilizzando.
Come passo successivo, ti incoraggio a provare il ridimensionamento delle funzionalità con altri algoritmi e capire cosa funziona meglio: normalizzazione o standardizzazione?, Vi consiglio di utilizzare i dati di vendita BigMart a tale scopo per mantenere la continuità con questo articolo. E non dimenticare di condividere le tue intuizioni nella sezione commenti qui sotto!
Puoi anche leggere questo articolo sulla nostra APP mobile