Un metodo di campionamento probabilistico è un metodo di campionamento che utilizza una qualche forma di selezione casuale. Per avere un metodo di selezione casuale, è necessario impostare un processo o una procedura che assicuri che le diverse unità della popolazione abbiano uguali probabilità di essere scelte. Gli esseri umani hanno praticato a lungo varie forme di selezione casuale, come scegliere un nome da un cappello o scegliere la cannuccia corta. In questi giorni, si tende a utilizzare i computer come il meccanismo per la generazione di numeri casuali come base per la selezione casuale.,
Alcune definizioni
Prima di poter spiegare i vari metodi di probabilità dobbiamo definire alcuni termini di base. Questi sono:
-
Nè il numero di casi nel campionamento -
nè il numero di casi nel campione -
NCn= il numero di combinazioni (sottoinsiemi) dindaN -
f = n/Nè la frazione sondata
Che sia., Con questi termini definiti possiamo iniziare a definire i diversi metodi di campionamento di probabilità.
Campionamento casuale semplice
La forma più semplice di campionamento casuale è chiamata campionamento casuale semplice. Piuttosto difficile, eh? Ecco la breve descrizione del campionamento casuale semplice:
- Obiettivo: Selezionare
nunità daNin modo tale che ogniNCnabbia le stesse possibilità di essere selezionato. - Procedura: utilizzare una tabella di numeri casuali, un generatore di numeri casuali del computer o un dispositivo meccanico per selezionare il campione.,
Una definizione un po ‘ stilizzata, se accurata. Vediamo se riusciamo a renderlo un po ‘ più reale.

Come selezioniamo un semplice campione casuale? Supponiamo che stiamo facendo qualche ricerca con una piccola agenzia di servizi che desidera valutare le opinioni dei clienti sulla qualità del servizio nell’ultimo anno. Per prima cosa, dobbiamo organizzare il frame di campionamento. Per fare questo, esamineremo i registri dell’agenzia per identificare ogni cliente negli ultimi 12 mesi. Se siamo fortunati, l’agenzia ha buoni record computerizzati accurati e può produrre rapidamente una tale lista., Quindi, dobbiamo effettivamente disegnare il campione. Decidere il numero di clienti che si desidera avere nel campione finale. Per il bene dell’esempio, supponiamo che tu voglia selezionare 100 clienti da esaminare e che ci siano stati 1000 clienti negli ultimi 12 mesi. Quindi, la frazione di campionamento è f = n/N = 100/1000 = .10 (o 10%). Ora, per disegnare effettivamente il campione, hai diverse opzioni. Si potrebbe stampare la lista di 1000 clienti, strappare poi in strisce separate, mettere le strisce in un cappello, mescolarle bene, chiudere gli occhi e tirare fuori i primi 100., Ma questa procedura meccanica sarebbe noiosa e la qualità del campione dipenderebbe da quanto accuratamente li hai mescolati e da quanto casualmente hai raggiunto. Forse una procedura migliore sarebbe quella di utilizzare il tipo di macchina palla che è popolare con molte delle lotterie di stato. Avresti bisogno di tre serie di palle numerate da 0 a 9, un set per ciascuna delle cifre da 000 a 999 (se selezioniamo 000 lo chiameremo 1000)., Numerare l’elenco dei nomi da1 a1000 e quindi utilizzare la macchina a sfera per selezionare le tre cifre che seleziona ogni persona. L’ovvio svantaggio qui è che è necessario per ottenere le macchine palla. (Dove fanno quelle cose, comunque? Esiste un’industria delle macchine a sfera?).
Nessuna di queste procedure meccaniche è molto fattibile e, con lo sviluppo di computer economici, c’è un modo molto più semplice. Ecco una semplice procedura che è particolarmente utile se si hanno i nomi dei client già sul computer., Molti programmi per computer possono generare una serie di numeri casuali. Supponiamo che tu possa copiare e incollare l’elenco dei nomi dei client in una colonna in un foglio di calcolo EXCEL. Quindi, nella colonna accanto ad essa incolla la funzione=RAND() che è il modo di EXCEL di inserire un numero casuale tra0 e1 nelle celle. Quindi, ordina entrambe le colonne – l’elenco dei nomi e il numero casuale-in base ai numeri casuali. Questo riorganizza l’elenco in ordine casuale dal più basso al più alto numero casuale., Quindi, tutto ciò che devi fare è prendere i primi cento nomi in questa lista ordinata. piuttosto semplice. Probabilmente si potrebbe realizzare il tutto in meno di un minuto.
Semplice campionamento casuale è semplice da realizzare ed è facile da spiegare agli altri. Poiché il semplice campionamento casuale è un modo equo per selezionare un campione, è ragionevole generalizzare i risultati dal campione alla popolazione. Il semplice campionamento casuale non è il metodo di campionamento più statisticamente efficiente e potresti, solo a causa della fortuna del sorteggio, non ottenere una buona rappresentazione dei sottogruppi in una popolazione., Per affrontare questi problemi, dobbiamo rivolgerci ad altri metodi di campionamento.
Campionamento casuale stratificato
Il campionamento casuale stratificato, talvolta chiamato anche campionamento casuale proporzionale o contingentale, comporta la divisione della popolazione in sottogruppi omogenei e quindi l’assunzione di un semplice campione casuale in ciascun sottogruppo. In termini più formali:
Ci sono diversi motivi principali per cui si potrebbe preferire il campionamento stratificato rispetto al semplice campionamento casuale., Innanzitutto, assicura che sarai in grado di rappresentare non solo la popolazione complessiva, ma anche i sottogruppi chiave della popolazione, in particolare i piccoli gruppi minoritari. Se vuoi essere in grado di parlare di sottogruppi, questo potrebbe essere l’unico modo per assicurarti efficacemente che sarai in grado di farlo. Se il sottogruppo è estremamente piccolo, è possibile utilizzare diverse frazioni di campionamento (f) all’interno dei diversi strati per campionare in modo casuale il piccolo gruppo (anche se sarà necessario ponderare le stime all’interno del gruppo utilizzando la frazione di campionamento ogni volta che si desidera stime generali della popolazione)., Quando usiamo la stessa frazione di campionamento all’interno degli strati stiamo conducendo un campionamento casuale stratificato proporzionato. Quando usiamo diverse frazioni di campionamento negli strati, chiamiamo questo campionamento casuale stratificato sproporzionato. In secondo luogo, il campionamento casuale stratificato avrà generalmente una maggiore precisione statistica rispetto al semplice campionamento casuale. Questo sarà vero solo se gli strati o i gruppi sono omogenei. Se lo sono, ci aspettiamo che la variabilità all’interno dei gruppi sia inferiore alla variabilità per la popolazione nel suo complesso. Il campionamento stratificato capitalizza su questo fatto.,
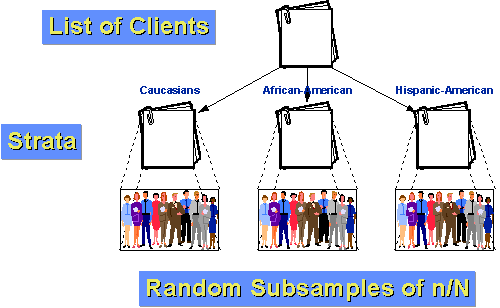
Ad esempio, diciamo che la popolazione di clienti per la nostra agenzia può essere divisa in tre gruppi: caucasico, afro-americano e ispano-americano. Inoltre, supponiamo che sia gli afroamericani che gli ispano-americani siano minoranze relativamente piccole della clientela (10% e5% rispettivamente)., Se facessimo un semplice campione casuale di n=100con una frazione di campionamento di10%, ci aspetteremmo solo per caso di ottenere solo 10 e 5 persone da ciascuno dei nostri due gruppi più piccoli. E, per caso, potremmo ottenere meno di quello! Se ci stratifichiamo, possiamo fare di meglio. Per prima cosa, determiniamo quante persone vogliamo avere in ogni gruppo. Diciamo che vogliamo ancora prendere un campione di 100 dalla popolazione di 1000 clienti nell’ultimo anno. Ma pensiamo che per dire qualcosa sui sottogruppi avremo bisogno di almeno 25 casi in ciascun gruppo., Quindi, proviamo 50 caucasici, 25 afroamericani e 25 ispano-americani. Sappiamo che il 10% della popolazione, o 100 clienti, sono afro-americani. Se campioniamo casualmente 25 di questi, abbiamo una frazione di campionamento all’interno dello strato di 25/100 = 25%. Allo stesso modo, sappiamo che 5% o 50 clienti sono ispano-americani. Quindi la nostra frazione di campionamento all’interno dello strato sarà 25/50 = 50%. Infine, per sottrazione sappiamo che ci sono 850 clienti caucasici. La nostra frazione di campionamento all’interno dello strato per loro è 50/850 = about 5.88%., Poiché i gruppi sono più omogenei all’interno del gruppo rispetto all’intera popolazione, possiamo aspettarci una maggiore precisione statistica (meno varianza). E, poiché abbiamo stratificato, sappiamo che avremo abbastanza casi da ogni gruppo per fare inferenze significative di sottogruppi.,e sono i passi da seguire per il raggiungimento di una sistematica campione casuale:
- numero di unità della popolazione
1N - decidere su
n(dimensione del campione) che si desidera o bisogno di -
k = N/n= intervallo di dimensione - selezionare casualmente un numero intero compreso tra
1k - poi prendere ogni
kthunità

Tutto questo sarà molto più chiaro con un esempio., Supponiamo di avere una popolazione che ha solo N = 100 persone e che si desidera prendere un campione di n=20. Per utilizzare il campionamento sistematico, la popolazione deve essere elencata in un ordine casuale. La frazione di campionamento sarebbe f = 20/100 = 20%. in questo caso, la dimensione dell’intervallo,k, è uguale aN/n = 100/20 = 5. Ora, seleziona un intero casuale da 1 to 5. Nel nostro esempio, immagina di aver scelto4., Ora, per selezionare il campione, iniziare con l’unità4th nell’elenco e prendere ogni unitàk-th (ogni 5, perché k=5). Campioneresti le unità 4, 9, 14, 19 e così via a 100 e finiresti con 20 unità nel tuo campione.
Affinché ciò funzioni, è essenziale che le unità della popolazione siano ordinate in modo casuale, almeno rispetto alle caratteristiche che si stanno misurando. Perché mai si desidera utilizzare il campionamento casuale sistematico? Per prima cosa, è abbastanza facile da fare. Devi solo selezionare un singolo numero casuale per iniziare le cose., Può anche essere più preciso del semplice campionamento casuale. Infine, in alcune situazioni non esiste semplicemente un modo più semplice per eseguire il campionamento casuale. Per esempio, una volta ho dovuto fare uno studio che ha coinvolto il campionamento da tutti i libri in una biblioteca. Una volta selezionato, dovrei andare allo scaffale, individuare il libro e registrare l’ultima volta che è circolato. Sapevo di avere un frame di campionamento abbastanza buono sotto forma di shelf list (che è un catalogo di carte in cui le voci sono disposte nell’ordine in cui si verificano sullo scaffale)., Per fare un semplice campione casuale, avrei potuto stimare il numero totale di libri e generare numeri casuali per disegnare il campione; ma come troverei facilmente book #74,329 se questo è il numero che ho selezionato? Non ho potuto contare molto bene le carte fino a quando sono arrivato a 74,329! Stratificare non risolverebbe neanche questo problema. Per esempio, avrei potuto stratificato per cassetto catalogo carta e disegnato un semplice campione casuale all’interno di ogni cassetto. Ma sarei ancora bloccato a contare le carte. Invece, ho fatto un campione casuale sistematico. Ho stimato il numero di libri nell’intera collezione. Immaginiamo fossero 100.000., Ho deciso che volevo prendere un campione di 1000 per una frazione di campionamento di 1000/100,000 = 1%. Per ottenere l’intervallo di campionamento k, ho diviso N/n = 100,000/1000 = 100. Quindi ho selezionato un numero intero casuale tra1 e100. Diciamo che ho ottenuto 57.
Successivamente, ho fatto un piccolo studio laterale per determinare quanto sono spesse mille carte nel catalogo delle carte (tenendo conto delle diverse età delle carte)., Diciamo che in media ho trovato che due carte che erano separate da100 carte erano circa .75 pollici a parte nel cassetto catalogo. Quell’informazione mi ha dato tutto il necessario per disegnare il campione. Ho contato fino al 57 ° a mano e ho registrato le informazioni del libro. Poi, ho preso una bussola. (Ricorda quelli della tua classe di matematica del liceo? Sono i piccoli strumenti di metallo divertenti con uno spillo appuntito su un’estremità e una matita dall’altra che hai usato per disegnare cerchi in classe di geometria.,) Quindi ho impostato la bussola su .75", ho bloccato l’estremità del pin sulla 57a carta e ho puntato con la matita sulla carta successiva (circa 100 libri di distanza). In questo modo, ho approssimato selezionando il 157°, 257°, 357 ° e così via. Sono stato in grado di eseguire l’intera procedura di selezione in pochissimo tempo utilizzando questo approccio sistematico di campionamento casuale. Probabilmente sarei ancora lì a contare le carte se avessi provato un altro metodo di campionamento casuale. (Ok, quindi non ho vita. Sono stato ricompensato bene, non mi dispiace dirlo, per aver inventato questo schema.,)
Cluster (Area) Campionamento casuale
Il problema con i metodi di campionamento casuale quando dobbiamo campionare una popolazione erogata in un’ampia regione geografica è che dovrai coprire un sacco di terreno geograficamente per arrivare a ciascuna delle unità campionate. Immagina di prendere un semplice campione casuale di tutti i residenti dello Stato di New York per condurre interviste personali. Con la fortuna del sorteggio si finirà con gli intervistati che provengono da tutto lo stato. I tuoi intervistatori avranno un sacco di viaggi da fare., È proprio per questo problema che è stato inventato il campionamento casuale di cluster o area.
Nel campionamento a grappolo (cluster, abbiamo attenersi alla seguente procedura:
- dividere la popolazione in cluster (di solito lungo i confini geografici)
- in modo casuale del campione cluster
- misura di tutte le unità di campionamento cluster
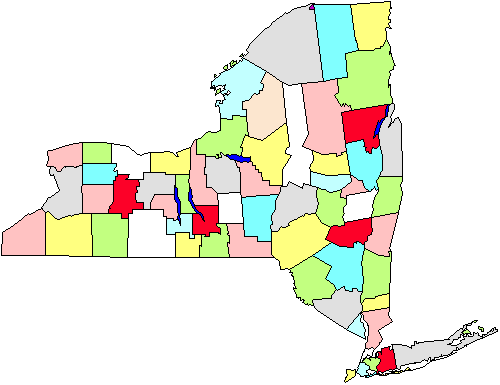
Per esempio, nella figura si vede una mappa delle contee nello Stato di New York. Diciamo che dobbiamo fare un sondaggio dei governi delle città che ci richiederà di andare personalmente nelle città., Se facciamo un semplice campione casuale a livello di stato dovremo coprire l’intero stato geograficamente. Invece, decidiamo di fare un campionamento cluster di cinque contee (contrassegnato in rosso nella figura). Una volta che questi sono selezionati, andiamo a ogni governo della città nelle cinque aree. Chiaramente questa strategia ci aiuterà a risparmiare sul nostro chilometraggio. Il campionamento di cluster o area, quindi, è utile in situazioni come questa e viene fatto principalmente per l’efficienza dell’amministrazione., Si noti inoltre che probabilmente non dobbiamo preoccuparci di utilizzare questo approccio se stiamo conducendo un sondaggio per posta o telefono perché non importa tanto (o costa di più o aumenta l’inefficienza) dove chiamiamo o inviamo lettere.
Campionamento multistadio
I quattro metodi che abbiamo trattato finora – semplice, stratificato, sistematico e cluster – sono le più semplici strategie di campionamento casuale. Nella maggior parte della ricerca sociale applicata reale, useremmo metodi di campionamento che sono considerevolmente più complessi di queste semplici variazioni., Il principio più importante qui è che possiamo combinare i semplici metodi descritti in precedenza in una varietà di modi utili che ci aiutano ad affrontare le nostre esigenze di campionamento nel modo più efficiente ed efficace possibile. Quando combiniamo metodi di campionamento, chiamiamo questo campionamento a più stadi.
Ad esempio, considera l’idea di campionare i residenti dello Stato di New York per interviste faccia a faccia. Chiaramente vorremmo fare un certo tipo di campionamento cluster come prima fase del processo. Potremmo campionare comuni o tratti di censimento in tutto lo stato., Ma nel campionamento dei cluster avremmo poi continuato a misurare tutti nei cluster che selezioniamo. Anche se stiamo campionando i tratti del censimento, potremmo non essere in grado di misurare tutti coloro che si trovano nel tratto del censimento. Quindi, potremmo impostare un processo di campionamento stratificato all’interno dei cluster. In questo caso, avremmo un processo di campionamento in due fasi con campioni stratificati all’interno di campioni di cluster. Oppure, considera il problema del campionamento degli studenti nelle scuole elementari. Potremmo iniziare con un campione nazionale di distretti scolastici stratificati per economia e livello di istruzione., All’interno di distretti selezionati, potremmo fare un semplice campione casuale di scuole. All’interno delle scuole, potremmo fare un semplice campione casuale di classi o gradi. E, all’interno delle classi, potremmo anche fare un semplice campione casuale di studenti. In questo caso, abbiamo tre o quattro fasi nel processo di campionamento e usiamo sia il campionamento casuale stratificato che semplice. Combinando diversi metodi di campionamento siamo in grado di ottenere una ricca varietà di metodi di campionamento probabilistici che possono essere utilizzati in una vasta gamma di contesti di ricerca sociale.