Introduzione
Ordinare i dati significa organizzarli in un certo ordine, spesso in una struttura dati simile a un array. È possibile utilizzare vari criteri di ordinamento, quelli comuni sono l’ordinamento dei numeri dal minimo al massimo o viceversa, o l’ordinamento lessicografico delle stringhe. È anche possibile definire i propri criteri, e andremo in modi pratici di farlo entro la fine di questo articolo.,
Se sei interessato a come funziona l’ordinamento, tratteremo vari algoritmi, da soluzioni inefficienti ma intuitive, ad algoritmi efficienti che sono effettivamente implementati in Java e in altri linguaggi.
Esistono vari algoritmi di ordinamento e non sono tutti ugualmente efficienti. Analizzeremo la loro complessità temporale per confrontarli e vedere quali eseguono meglio.,
La lista degli algoritmi imparerete qui non è affatto esaustiva, ma abbiamo compilato una lista di alcuni dei più comuni e più efficienti per aiutarti a iniziare:
- Bubble Sort
- Insertion Sort
- Ordinamento per Selezione
- Merge Sort
- Heapsort
- Quicksort
- Ordinamento in Java
Nota: Questo articolo non avere a che fare con concorrenti ordinamento, in quanto è pensato per i principianti.
Bubble Sort
Spiegazione
Bubble sort funziona scambiando elementi adiacenti se non sono nell’ordine desiderato., Questo processo si ripete dall’inizio della matrice fino a quando tutti gli elementi sono in ordine.
Sappiamo che tutti gli elementi sono in ordine quando riusciamo a fare l’intera iterazione senza scambiare affatto – quindi tutti gli elementi che abbiamo confrontato erano nell’ordine desiderato con i loro elementi adiacenti e, per estensione, l’intero array.
Ecco i passaggi per ordinare una matrice di numeri dal minimo al massimo:
-
4 2 1 5 3: I primi due elementi sono nell’ordine sbagliato, quindi li scambiamo.
-
2 4 1 5 3: Anche i secondi due elementi sono nell’ordine sbagliato, quindi scambiamo.,
-
2 1 4 5 3: Questi due sono nel giusto ordine, 4< 5, quindi li lasciamo soli.
-
2 1 4 5 3: Un altro scambio.
-
2 1 4 3 5: Ecco l’array risultante dopo un’iterazione.
Poiché almeno uno swap si è verificato durante il primo passaggio (ce n’erano in realtà tre), dobbiamo ripetere l’intero array e ripetere lo stesso processo.
Ripetendo questo processo, fino a quando non vengono effettuati più swap, avremo un array ordinato.,
Il motivo per cui questo algoritmo è chiamato Bubble Sort è perché i numeri tipo di “bolla” alla “superficie.”Se si passa di nuovo attraverso il nostro esempio, seguendo un numero particolare (4 è un ottimo esempio), lo vedrai lentamente muoversi verso destra durante il processo.
Tutti i numeri si spostano nei rispettivi punti a poco a poco, da sinistra a destra, come bolle che lentamente salgono da un corpo d’acqua.
Se vuoi leggere un articolo dettagliato e dedicato per Bubble Sort, ti abbiamo coperto!,
Implementazione
Implementeremo Bubble Sort in modo simile a quello che abbiamo definito a parole. La nostra funzione entra in un ciclo while in cui passa attraverso l’intero array scambiando secondo necessità.
Assumiamo che l’array sia ordinato, ma se ci dimostriamo sbagliati durante l’ordinamento (se si verifica uno scambio), passiamo attraverso un’altra iterazione. Il ciclo while continua quindi fino a quando non riusciamo a passare attraverso l’intero array senza scambiare:
Quando usiamo questo algoritmo dobbiamo stare attenti a come affermiamo la nostra condizione di swap.,
Ad esempio, se avessi usatoa >= aavrebbe potuto finire con un ciclo infinito, perché per elementi uguali questa relazione sarebbe sempretrue, e quindi scambiarli sempre.
Complessità temporale
Per capire la complessità temporale dell’ordinamento delle bolle, dobbiamo guardare allo scenario peggiore possibile. Qual è il numero massimo di volte in cui dobbiamo passare attraverso l’intero array prima di averlo ordinato?, Si consideri il seguente esempio:
5 4 3 2 1Nella prima iterazione, 5 “bolle fino alla superficie”, ma il resto degli elementi rimarrebbe in ordine decrescente. Dovremmo fare un’iterazione per ogni elemento tranne 1, e poi un’altra iterazione per verificare che tutto sia in ordine, quindi un totale di 5 iterazioni.
Espandi questo a qualsiasi array din elementi, e ciò significa che devi faren iterazioni., Guardando il codice, ciò significherebbe che il nostro ciclowhile può eseguire il massimo din volte.
Ognuna di questen volte stiamo iterando attraverso l’intero array (for-loop nel codice), il che significa che la complessità temporale del caso peggiore sarebbe O(n^2).
Nota: La complessità temporale sarebbe sempre O(n^2) se non fosse per il controllo booleano sorted, che termina l’algoritmo se non ci sono swap all’interno del ciclo interno, il che significa che l’array è ordinato.,
Insertion Sort
Spiegazione
L’idea alla base dell’Insertion Sort sta dividendo l’array nei sottoarray ordinati e non ordinati.
La parte ordinata è di lunghezza 1 all’inizio e corrisponde al primo elemento (più a sinistra) nell’array. Iteriamo attraverso l’array e durante ogni iterazione, espandiamo la porzione ordinata dell’array di un elemento.
All’espansione, posizioniamo il nuovo elemento nella sua posizione corretta all’interno del sottoarray ordinato. Lo facciamo spostando tutti gli elementi a destra fino a quando non incontriamo il primo elemento che non dobbiamo spostare.,
Ad esempio, se nel seguente array la parte in grassetto viene ordinata in ordine crescente, si verifica quanto segue:
-
3 5 7 8 4 2 1 9 6: Prendiamo 4 e ricordiamo che è quello che dobbiamo inserire. Dal momento che 8 > 4, ci spostiamo.
-
3 5 7 x 8 2 1 9 6: Dove il valore di x non è di importanza cruciale, poiché verrà sovrascritto immediatamente (o di 4 se è il suo posto appropriato o di 7 se spostiamo). Poiché 7 > 4, spostiamo.,
-
3 5 x 7 8 2 1 9 6
-
3 x 5 7 8 2 1 9 6
-
3 4 5 7 8 2 1 9 6
Dopo questo processo, la porzione ordinata è stata espansa di un elemento, ora abbiamo cinque anziché quattro elementi. Ogni iterazione fa questo e alla fine avremo l’intero array ordinato.
Se vuoi leggere un articolo dettagliato e dedicato per l’ordinamento di inserimento, ti abbiamo coperto!,
Implementazione
Complessità temporale
Ancora una volta, dobbiamo guardare lo scenario peggiore per il nostro algoritmo, e sarà di nuovo l’esempio in cui l’intero array sta scendendo.
Questo perché in ogni iterazione, dovremo spostare l’intero elenco ordinato di uno, che è O(n). Dobbiamo farlo per ogni elemento in ogni array, il che significa che sarà limitato da O(n^2).
Selection Sort
Spiegazione
Selection Sort divide anche l’array in un sottoarray ordinato e non ordinato., Anche se, questa volta, ordinato sottomatrice formata inserendo il minimo elemento non sottomatrice alla fine dell’array ordinato, da scambiare:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 4 5
-
1 2 3 4 5
-
1 2 3 4 5
-
1 2 3 4 5
Realizzazione
In ogni iterazione, si assume che il primo indifferenziati elemento è il minimo e si itera il resto per vedere se c’è un piccolo elemento.,
una Volta trovato il minimo corrente non parte della matrice, si scambia con il primo elemento e lo considerano una parte dell’array ordinato:
Complessità
Trovare il minimo è O(n) per la lunghezza dell’array, perché dobbiamo controllare tutti gli elementi. Dobbiamo trovare il minimo per ogni elemento dell’array, rendendo l’intero processo limitato da O(n^2).,
Merge Sort
Spiegazione
Merge Sort utilizza la ricorsione per risolvere il problema dell’ordinamento in modo più efficiente rispetto agli algoritmi precedentemente presentati, e in particolare utilizza un approccio divide et impera.
l’Utilizzo di entrambi questi concetti, si romperà l’intero array in due subarray e poi:
- Ordina la metà sinistra dell’array (ricorsivamente)
- Ordina la metà destra della matrice (ricorsivamente)
- Unisci le soluzioni
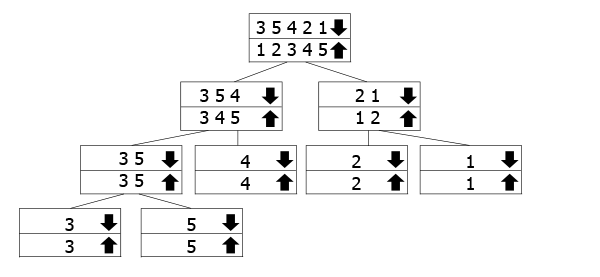
Questo albero è destinato a rappresentare come la chiamate ricorsive di lavoro., Gli array contrassegnati con la freccia giù sono quelli per cui chiamiamo la funzione, mentre stiamo unendo quelli con la freccia su che tornano su. Quindi segui la freccia verso il basso fino al fondo dell’albero, quindi torna su e unisci.
Nel nostro esempio, abbiamo l’array 3 5 3 2 1, quindi lo dividiamo in 3 5 4 e 2 1. Per ordinarli, li dividiamo ulteriormente nei loro componenti. Una volta raggiunto il fondo, iniziamo a fonderli e a ordinarli mentre andiamo.,
Se vuoi leggere un articolo dettagliato e dedicato per Merge Sort, ti abbiamo coperto!
Implementazione
La funzione principale funziona praticamente come descritto nella spiegazione. Stiamo solo passando gli indicileft eright che sono indici dell’elemento più sinistro e più destro del sottoarray che vogliamo ordinare. Inizialmente, questi dovrebbero essere 0earray.length-1, a seconda dell’implementazione.,
La base della nostra ricorsione assicura che usciamo quando abbiamo finito, o quandorighteleft si incontrano. Troviamo un punto mediomid, e ordiniamo i subarray a sinistra ea destra di esso in modo ricorsivo, alla fine fondendo le nostre soluzioni.
Se ricordi la nostra grafica ad albero, potresti chiederti perché non creiamo due nuovi array più piccoli e li trasmettiamo invece. Questo perché su array molto lunghi, ciò causerebbe un enorme consumo di memoria per qualcosa che è essenzialmente inutile.,
Merge Sort già non funziona sul posto a causa della fase di unione, e questo servirebbe solo a peggiorare la sua efficienza della memoria. La logica del nostro albero di ricorsione rimane altrimenti la stessa, tuttavia, dobbiamo solo seguire gli indici che stiamo usando:
Per unire i sottoarray ordinati in uno, dovremo calcolare la lunghezza di ciascuno e creare array temporanei per copiarli, in modo da poter cambiare liberamente il nostro array principale.
Dopo la copia, passiamo attraverso l’array risultante e assegniamo il minimo corrente., Poiché i nostri subarray sono ordinati, abbiamo appena scelto il minore dei due elementi che non sono stati scelti finora, e spostare l’iteratore per quel subarray in avanti:
Complessità temporale
Se vogliamo derivare la complessità degli algoritmi ricorsivi, dovremo ottenere un po ‘ di mathy.
Il Teorema principale viene utilizzato per capire la complessità temporale degli algoritmi ricorsivi. Per gli algoritmi non ricorsivi, di solito potremmo scrivere la complessità temporale precisa come una sorta di equazione, e quindi usiamo la notazione Big-O per ordinarli in classi di algoritmi che si comportano allo stesso modo.,
Il problema con gli algoritmi ricorsivi è che quella stessa equazione sarebbe simile a questa:
T
T(n) = aT(\frac{n}{b}) + cn^k
The
L’equazione stessa è ricorsiva! In questa equazione, a ci dice quante volte chiamiamo la ricorsione, e b ci dice in quante parti il nostro problema è diviso. In questo caso può sembrare una distinzione non importante perché sono uguali per mergesort, ma per alcuni problemi potrebbero non esserlo.,
Il resto dell’equazione è la complessità di unire tutte quelle soluzioni in una alla fine., Il Master Teorema risolve questa equazione per noi:
$$
T(n) = \Bigg\{
\begin{matrix}
O(n^{log_ba}), &>b^k \\ O(n^klog n), & a = b^k \\ O(n^k), & < b^k
\end{matrix}
$$
Se T(n) runtime dell’algoritmo di ordinamento di un array di lunghezza n Merge Sort avrebbe eseguito due volte per le matrici che sono la metà della lunghezza dell’array originale.,
Quindi se abbiamoa=2,b=2. Il passaggio di unione richiede memoria O (n), quindi k=1. Ciò significa che l’equazione per l’ordinamento di unione apparirebbe come segue:
T
T(n) = 2T(\frac{n}{2})+cn
cn
Se applichiamo il Teorema Principale, vedremo che il nostro caso è quello in cui a=b^k perché abbiamo 2=2^1. Ciò significa che la nostra complessità è O (nlog n). Questa è una complessità temporale estremamente buona per un algoritmo di ordinamento, poiché è stato dimostrato che un array non può essere ordinato più velocemente di O(nlog n).,
Mentre la versione che abbiamo mostrato consuma memoria, ci sono versioni più complesse di Merge Sort che occupano solo spazio O(1).
Inoltre, l’algoritmo è estremamente facile da parallelizzare, poiché le chiamate ricorsive da un nodo possono essere eseguite in modo completamente indipendente da rami separati. Mentre noi non essere sempre in come e perché, come è oltre lo scopo di questo articolo, vale la pena di tenere a mente i pro di utilizzare questo particolare algoritmo.,
Heapsort
Spiegazione
Per capire correttamente perché Heapsort funziona, devi prima capire la struttura su cui è basato – l’heap. Parleremo specificamente in termini di heap binario, ma è possibile generalizzare la maggior parte di questo anche ad altre strutture heap.
Un heap è un albero che soddisfa la proprietà heap, ovvero che per ogni nodo, tutti i suoi figli sono in una determinata relazione con esso. Inoltre, un heap deve essere quasi completo., Un albero binario quasi completo di profonditàd ha un sottoalbero di profonditàd-1 con la stessa radice completa e in cui ogni nodo con un discendente sinistro ha un sottoalbero sinistro completo. In altre parole, quando si aggiunge un nodo, si sceglie sempre la posizione più a sinistra nel livello incompleto più alto.
Se l’heap è un max-heap, allora tutti i bambini sono più piccoli del genitore, e se è un min-heap tutti sono più grandi.,
In altre parole, mentre si sposta verso il basso l’albero, si arriva a numeri sempre più piccoli (min-heap) o numeri sempre più grandi (max-heap). Ecco un esempio di un max-heap:
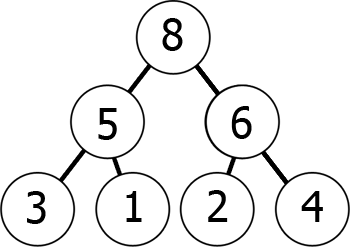
Possiamo rappresentare questo max-heap in memoria come un array nel modo seguente:
8 5 6 3 1 2 4 Puoi immaginarlo come leggendo dal grafico livello per livello, da sinistra a destra., Ciò che abbiamo ottenuto con questo è che se prendiamo l’elemento kth nell’array, le posizioni dei suoi figli sono 2*k+1 e 2*k+2 (supponendo che l’indicizzazione inizi da 0). Puoi controllare questo per te.
Viceversa, per l’elementokth la posizione del genitore è sempre(k-1)/2.
Sapendo questo, puoi facilmente “max-heapify” qualsiasi array dato. Per ogni elemento, controlla se uno qualsiasi dei suoi figli è più piccolo di esso., Se lo sono, scambia uno di essi con il genitore e ripeti ricorsivamente questo passaggio con il genitore (perché il nuovo elemento grande potrebbe essere ancora più grande dell’altro figlio).
Le foglie non hanno figli, quindi sono banalmente max-heap di loro:
-
6 1 8 3 5 2 4: Entrambi i bambini sono più piccoli del genitore, quindi tutto rimane lo stesso.
-
6 1 8 3 5 2 4: Perché 5> 1, li scambiamo. Abbiamo ricorsivamente heapify per 5 ora.
-
6 5 8 3 1 2 4: Entrambi i bambini sono più piccoli, quindi non succede nulla.,
-
6 5 8 3 1 2 4: Perché 8> 6, li scambiamo.
-
8 5 6 3 1 2 4: Abbiamo ottenuto il mucchio nella foto sopra!
Una volta che abbiamo imparato ad accatastare un array, il resto è piuttosto semplice. Scambiamo la radice dell’heap con la fine dell’array e accorciamo l’array di uno.,
Ci heapify accorciato matrice di nuovo, e ripetere il processo:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: scambiato
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: scambiato
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: scambiato
E così via, sono sicuro che si può vedere il modello che emerge.
Implementazione
Complessità temporale
Quando guardiamo la funzioneheapify(), tutto sembra essere fatto in O(1), ma poi c’è quella fastidiosa chiamata ricorsiva.,
Quante volte verrà chiamato, nel peggiore dei casi? Beh, nel peggiore dei casi, si propagherà fino in cima all’heap. Lo farà saltando al genitore di ogni nodo, quindi intorno alla posizione i/2. ciò significa che farà nel peggiore dei casi i salti di log n prima che raggiunga la cima, quindi la complessità è O(log n).
Poiché heapSort() è chiaramente O(n) a causa di for-loop che iterano attraverso l’intero array, ciò renderebbe la complessità totale di Heapsort O(nlog n).,
Heapsort è un ordinamento sul posto, il che significa che richiede O(1) spazio aggiuntivo, invece di Unire l’ordinamento, ma ha anche alcuni inconvenienti, come essere difficile da parallelizzare.
Quicksort
Spiegazione
Quicksort è un altro algoritmo di divisione e conquista. Sceglie un elemento di un array come perno e ordina tutti gli altri elementi attorno ad esso, ad esempio elementi più piccoli a sinistra e più grandi a destra.
Questo garantisce che il pivot sia nella sua posizione corretta dopo il processo., Quindi l’algoritmo ricorsivamente fa lo stesso per le parti sinistra e destra dell’array.
Implementazione
Complessità temporale
La complessità temporale di Quicksort può essere espressa con la seguente equazione:
T
T(n) = T(k) + T(n-k-1) + O(n)
br
Lo scenario peggiore è quando l’elemento più grande o più piccolo viene sempre scelto per pivot. L’equazione sarebbe quindi simile a questa:
T(n) = T(0) + T(n-1) + O(n) = T(n-1) + O(n)
Questo risulta essere O(n^2).,
Questo può sembrare cattivo, dato che abbiamo già imparato più algoritmi che vengono eseguiti nel tempo O(nlog n) come il loro caso peggiore, ma Quicksort è in realtà molto usato.
Questo perché ha un runtime medio davvero buono, anche limitato da O(nlog n), ed è molto efficiente per una grande porzione di input possibili.
Uno dei motivi per cui è preferibile unire l’ordinamento è che non richiede spazio aggiuntivo, tutto l’ordinamento viene eseguito sul posto e non ci sono costose chiamate di allocazione e deallocazione.,
Confronto delle prestazioni
Detto questo, è spesso utile eseguire tutti questi algoritmi sulla macchina alcune volte per avere un’idea di come si comportano.
Si esibiranno in modo diverso con diverse collezioni che vengono ordinate ovviamente, ma anche con questo in mente, dovresti essere in grado di notare alcune tendenze.
Eseguiamo tutte le implementazioni, una per una, ciascuna su una copia di un array mischiato di 10.000 interi:
Possiamo evidentemente vedere che l’ordinamento delle bolle è il peggiore quando si tratta di prestazioni., Evita di usarlo in produzione se non puoi garantire che gestirà solo piccole raccolte e non bloccherà l’applicazione.
HeapSort e QuickSort sono i migliori in termini di prestazioni. Anche se stanno emettendo risultati simili, QuickSort tende ad essere un po ‘ migliore e più coerente – che verifica.
Ordinamento in Java
Interfaccia comparabile
Se hai i tuoi tipi, potrebbe diventare complicato implementare un algoritmo di ordinamento separato per ciascuno di essi. Ecco perché Java fornisce un’interfaccia che consente di utilizzare Collections.sort() sulle proprie classi.,
Per fare ciò, la classe deve implementare l’interfaccia Comparable<T>, dove T è il tuo tipo e sovrascrivere un metodo chiamato .compareTo().
Questo metodo restituisce un numero intero negativo sethisè inferiore all’elemento argomento, 0 se sono uguali, e un numero intero positivo sethis è maggiore.
Nel nostro esempio, abbiamo fatto una classe Student, e ogni studente è identificato da un id e un anno hanno iniziato i loro studi.,
vogliamo ordinare principalmente, da generazioni, ma anche, secondariamente, da un Id:
Ed ecco come utilizzare in un’applicazione:
Uscita:
Interfaccia Comparator
Si potrebbe desiderare di ordinare i nostri oggetti in un modo poco ortodosso per uno scopo specifico, ma non vogliamo implementare il comportamento di default della nostra classe, o ci potrebbe essere l’ordinamento di una collezione di un built-in del tipo non-default.
Per questo, possiamo usare l’interfaccia Comparator., Per esempio, prendiamo il nostro Student classe e ordinare solo da ID:
Se si sostituisce il tipo di chiamata nel main con il seguente:
Arrays.sort(a, new SortByID());Uscita:
Come Funziona
Collection.sort() funziona chiamando il sottostante Arrays.sort() metodo, mentre l’ordinamento stesso utilizza Inserimento Ordina per le matrici più breve di 47, e Quicksort per il resto.,
Si basa su una specifica implementazione a due pivot di Quicksort che garantisce di evitare la maggior parte delle tipiche cause di degrado in prestazioni quadratiche, secondo la documentazione JDK10.
Conclusione
L’ordinamento è un’operazione molto comune con i set di dati, sia che si tratti di analizzarli ulteriormente, accelerare la ricerca utilizzando algoritmi più efficienti che si basano sui dati ordinati, filtrare i dati, ecc.
L’ordinamento è supportato da molte lingue e le interfacce spesso oscurano ciò che sta realmente accadendo al programmatore., Mentre questa astrazione è benvenuta e necessaria per un lavoro efficace, a volte può essere mortale per l’efficienza, ed è bene sapere come implementare vari algoritmi e avere familiarità con i loro pro e contro, nonché come accedere facilmente alle implementazioni integrate.