a valószínűségi mintavételi módszer bármilyen mintavételi módszer, amely a véletlenszerű kiválasztás valamilyen formáját használja. Annak érdekében, hogy véletlenszerű kiválasztási módszerrel rendelkezzen, be kell állítania egy olyan folyamatot vagy eljárást, amely biztosítja, hogy a lakosság különböző egységei egyenlő valószínűséggel választhatók. Az emberek már régóta gyakorolják a véletlenszerű kiválasztás különböző formáit, mint például a név kiválasztása kalapból, vagy a rövid szalma kiválasztása. Manapság hajlamosak vagyunk a számítógépeket a véletlenszerű számok generálásának mechanizmusaként használni a véletlenszerű kiválasztás alapjaként.,
néhány definíció
mielőtt megmagyaráznám a különböző valószínűségi módszereket, meg kell határoznunk néhány alapvető kifejezést. Ezek a következők:
-
Naz esetek száma a mintavételi keret -
naz esetek száma a mintában -
NCn= a kombinációk száma (alcsoport) anaN -
f = n/Na mintavételi frakció
ez van., Ezekkel a kifejezésekkel meghatározhatjuk a különböző valószínűségi mintavételi módszereket.
egyszerű véletlenszerű mintavétel
a véletlenszerű mintavétel legegyszerűbb formáját egyszerű véletlenszerű mintavételnek nevezik. Elég trükkös, mi? Itt van az egyszerű véletlenszerű mintavétel gyors leírása:
- célkitűzés: a
negységek kiválasztása aNúgy, hogy mindenNCnegyenlő esélye legyen a kiválasztásra. - eljárás: a minta kiválasztásához használjon véletlenszerű számokat, számítógépes véletlenszám-generátort vagy mechanikus eszközt.,
a kissé stilizált, ha pontos, meghatározás. Lássuk, hogy egy kicsit valóságosabbá tudjuk-e tenni.

Hogyan válasszunk ki egy egyszerű véletlenszerű mintát? Tegyük fel, hogy kutatást végzünk egy kis szolgáltató ügynökséggel, amely az ügyfelek véleményét kívánja értékelni a szolgáltatás minőségéről az elmúlt évben. Először is meg kell szerveznünk a mintavételi keretet. Ennek elérése érdekében átnézjük az ügynökség nyilvántartásait, hogy azonosítsuk az összes ügyfelet az elmúlt 12 hónapban. Ha szerencsénk van, az ügynökség jó pontos számítógépes nyilvántartásokkal rendelkezik, és gyorsan elkészíthet egy ilyen listát., Ezután meg kell rajzolnunk a mintát. Döntse el, hogy hány ügyfelet szeretne a végső mintában. A példa kedvéért tegyük fel, hogy 100 ügyfelet szeretne kiválasztani a felméréshez, és hogy az elmúlt 12 hónapban 1000 ügyfél volt. Ezután a mintavételi frakció f = n/N = 100/1000 = .10 (vagy 10%). Most, hogy valóban felhívja a mintát, több lehetősége van. Kinyomtathatja az 1000 ügyfél listáját, majd külön csíkokra tépheti, kalapba teheti a csíkokat, jól összekeverheti őket, becsukhatja a szemét, és kihúzhatja az első 100-at., De ez a mechanikai eljárás unalmas lenne, és a minta minősége attól függ, hogy milyen alaposan összekevered őket, és milyen véletlenszerűen jutottál be. Talán egy jobb eljárás lenne, hogy használja a fajta labda gép, amely népszerű a sok állami lottó. Szüksége lenne három 0-9-es számú golyóra, egy készletre a 000 999 számjegyekhez (ha kiválasztjuk a 000 ezt hívjuk 1000)., Adja meg a 1 1000 nevek listáját, majd a golyógép segítségével válassza ki az egyes személyeket kiválasztó három számjegyet. A nyilvánvaló hátránya itt az, hogy meg kell, hogy a labda gépek. (Egyébként hol készítik ezeket a dolgokat? Van egy labda gépipar?).
Ezen mechanikai eljárások egyike sem nagyon megvalósítható, az olcsó számítógépek fejlesztésével sokkal könnyebb. Itt van egy egyszerű eljárás, amely különösen akkor hasznos, ha az ügyfelek neve már a számítógépen van., Sok számítógépes program véletlenszerű számok sorozatát generálhatja. Tegyük fel, hogy másolhatja és beillesztheti az ügyfélnevek listáját egy EXCEL táblázatkezelő oszlopába. Ezután a mellette lévő oszlopban illessze be a =RAND() függvényt, amely az EXCEL módja annak, hogy véletlenszerű számot helyezzen a 0 és 1 közé a cellákban. Ezután rendezze mindkét oszlopot – a nevek listáját, valamint a véletlen számot-a véletlen számokkal. Ez átrendezi a listát véletlenszerű sorrendben a legalacsonyabbról a legmagasabb véletlenszámra., Ezután mindössze annyit kell tennie, hogy az első száz nevet ebben a rendezett listában. elég egyszerű. Egy perc alatt véghez vihetnéd az egészet.
egyszerű véletlen mintavétel egyszerű elérni, és könnyen magyarázható, hogy mások. Mivel az egyszerű véletlenszerű mintavétel tisztességes módja a minta kiválasztásának, ésszerű a minta eredményeinek általánosítása a lakosságra. Egyszerű véletlen mintavétel nem a statisztikailag leghatékonyabb módszer a mintavétel, és lehet, csak azért, mert a szerencse a sorsolás, nem kap jó ábrázolása alcsoportok egy populációban., Ezeknek a kérdéseknek a kezeléséhez más mintavételi módszerekhez kell fordulnunk.
rétegzett véletlenszerű mintavétel
rétegzett véletlenszerű mintavétel, más néven arányos vagy kvóta véletlenszerű mintavétel, magában foglalja a populáció homogén alcsoportokra történő felosztását, majd egy egyszerű véletlenszerű mintát vesz minden alcsoportban. Formálisabb értelemben:
számos fő oka van annak, hogy miért részesítheti előnyben a rétegzett mintavételt az egyszerű véletlenszerű mintavételnél., Először is biztosítja, hogy nemcsak a teljes lakosságot, hanem a lakosság kulcsfontosságú alcsoportjait is képviselheti, különösen a kis kisebbségi csoportokat. Ha azt szeretnénk, hogy képes legyen beszélni alcsoportok, ez lehet az egyetlen módja annak, hogy hatékonyan biztosítani tudja, hogy képes lesz. Ha az alcsoport rendkívül kicsi, különböző mintavételi frakciókat (f) használhat a különböző rétegeken belül, hogy véletlenszerűen túlminősítse a kis csoportot (bár akkor a csoporton belüli becsléseket a mintavételi frakció segítségével kell súlyoznia, amikor a teljes népesség becslését szeretné)., Amikor ugyanazt a mintavételi frakciót használjuk a rétegeken belül, arányos rétegzett véletlenszerű mintavételt végzünk. Amikor különböző mintavételi frakciókat használunk a rétegekben, ezt aránytalanul rétegzett véletlenszerű mintavételnek nevezzük. Másodszor, a rétegzett véletlenszerű mintavétel általában nagyobb statisztikai pontossággal rendelkezik, mint az egyszerű véletlenszerű mintavétel. Ez csak akkor lesz igaz, ha a rétegek vagy csoportok homogének. Ha igen, akkor arra számítunk, hogy a csoportokon belüli változékonyság alacsonyabb, mint a lakosság egészének változékonysága. A rétegzett mintavétel kihasználja ezt a tényt.,
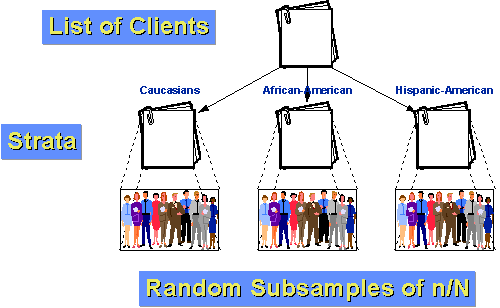
például tegyük fel, hogy ügynökségünk ügyfeleinek lakossága három csoportra osztható: kaukázusi, afro-amerikai és spanyol-amerikai. Tegyük fel továbbá, hogy mind az afroamerikaiak, mind a spanyol-amerikaiak viszonylag kis kisebbségek az ügyfélkörben (10% és 5%)., Ha csak egy egyszerű véletlen minta a n=100 egy mintavételi töredéke 10% elvárjuk véletlenül egyedül, hogy mi lenne csak 10, illetve 5 személyek mindegyike a két kisebb csoportok. És véletlenül ennél kevesebb is lehetne! Ha rétegezzük, jobban tudunk csinálni. Először is, határozzuk meg, hogy hány embert akarunk minden csoportban. Tegyük fel, hogy még mindig 100-as mintát akarunk venni az 1000 ügyfelek lakosságából az elmúlt évben. De úgy gondoljuk, hogy ahhoz, hogy bármit is mondjunk az alcsoportokról, minden csoportban legalább 25 esetre van szükségünk., Vegyünk 50 kaukázusi, 25 afroamerikai és 25 spanyol-amerikai mintát. Tudjuk, hogy a lakosság 10%-a vagy 100 ügyfél afro-amerikai. Ha ezek közül véletlenszerűen 25 mintát veszünk, akkor a 25/100 = 25%rétegen belüli mintavételi frakciónk van. Hasonlóképpen tudjuk, hogy 5% vagy 50 ügyfelek spanyol-amerikai. Tehát a rétegen belüli mintavételi frakciónk 25/50 = 50% lesz. Végül kivonással tudjuk, hogy 850 kaukázusi ügyfél van. A rétegen belüli mintavételi frakciónk 50/850 = about 5.88%., Mivel a csoportok homogénebbek a csoporton belül, mint az egész népesség egészében, nagyobb statisztikai pontosságra (kevesebb varianciára) számíthatunk. És mivel rétegeztük, tudjuk, hogy minden csoportból elég esetünk lesz ahhoz, hogy értelmes alcsoport következtetéseket vonjunk le.,e lépéseket kell követni annak érdekében, hogy egy szisztematikus véletlen minta:
- szám az egységek a lakosság
1, hogy aN - dönt a
n(mintanagyság) hogy akar vagy szükség van -
k = N/n= az intervallum mérete - véletlenszerűen kiválaszt egy egész szám között
1, hogy ak - akkor minden
kthegység

Minden sokkal érthetőbb lesz egy példával., Tegyük fel, hogy olyan népességünk van, amelyben csak N = 100 ember van, és hogy mintát akarsz venni n=20-ból. A szisztematikus mintavétel használatához a lakosságot véletlenszerű sorrendben kell felsorolni. A mintavételi frakció f = 20/100 = 20%lenne. ebben az esetben az intervallum mérete, k, egyenlő: N/n = 100/20 = 5. Most válasszon ki egy véletlenszerű egész számot a 1 to 5. Példánkban képzelje el, hogy a 4 – t választotta., Most, hogy kiválassza a mintát, kezdje a4th egységgel a listában, és vegyen be mindenk-th egységet (minden 5., mert k=5). A 4-es, 9-es, 14-es, 19-es és így tovább a 100-as mintavételi egységek lennének, és 20 egység lenne a mintában.
ahhoz, hogy ez működjön, elengedhetetlen, hogy a lakosság egységeit véletlenszerűen rendezzék, legalábbis a mért jellemzők tekintetében. Miért akarna valaha is szisztematikus véletlenszerű mintavételt használni? Egy dolog, ez elég könnyű csinálni. Csak ki kell választania egy véletlen számot a dolgok elindításához., Lehet, hogy pontosabb, mint az egyszerű véletlenszerű mintavétel. Végül, bizonyos helyzetekben egyszerűen nincs könnyebb módja a véletlenszerű mintavételnek. Például egyszer meg kellett csinálnom egy tanulmányt, amely magában foglalta a könyvtár összes könyvének mintavételét. Miután kiválasztottam, ki kell mennem a polcra, megkeresni a könyvet, és rögzíteni, amikor utoljára keringett. Tudtam, hogy meglehetősen jó mintavételi keretem van a polclista formájában (ami egy kártyakatalógus, ahol a bejegyzések a polcon előforduló sorrendben vannak elrendezve)., Ehhez egy egyszerű véletlenszerű minta, tudtam volna becsülni a könyvek száma és generált véletlen számok felhívni a mintát; de hogyan találom könyv # 74,329 könnyen, ha ez a szám én kiválasztott? Nem tudtam nagyon jól számolni a kártyákat, amíg el nem jöttem a 74,329-hez! A rétegezés sem oldaná meg ezt a problémát. Például, tudtam volna rétegzett kártyakatalógus fiók és húzott egy egyszerű véletlenszerű mintát az egyes fiókokban. De még mindig nem számoltam a kártyákat. Ehelyett szisztematikus véletlenszerű mintát készítettem. Becsültem a könyvek számát a teljes gyűjteményben. Képzeljük el, hogy 100.000 volt., Úgy döntöttem, hogy 1000 mintát akarok venni a 1000/100,000 = 1% mintavételi frakcióhoz. A k mintavételi intervallum megszerzéséhez N/n = 100,000/1000 = 100osztottam. Ezután kiválasztottam egy véletlenszerű egész számot a 1 és 100között. Tegyük fel, hogy van 57.
ezután egy kis oldalsó tanulmányt készítettem annak meghatározására, hogy milyen vastag ezer kártya van a kártyakatalógusban (figyelembe véve a kártyák különböző életkorát)., Tegyük fel, hogy átlagosan azt tapasztaltam, hogy két kártya, amelyet elválasztottak a 100 a kártyák körülbelül .75 hüvelyk távolságra vannak a katalógus fiókban. Ez az információ adott nekem mindent, amire szükségem volt a minta rajzolásához. Kézzel számoltam az 57. helyre, és rögzítettem a könyv adatait. Aztán vettem egy iránytűt. (Emlékszel a középiskolai matekórádra? Ezek a vicces kis fémeszközök, az egyik végén éles tűvel, a másikon ceruzával, amellyel köröket rajzolt a geometria osztályban.,) Ezután az iránytűt a .75" értékre állítottam, a tű végét az 57.kártyán beragasztottam, a ceruza végét pedig a következő kártyára mutattam (kb. Ily módon közelítettem a 157., 257., 357. stb. A teljes kiválasztási eljárást nagyon kevés idő alatt tudtam elvégezni ezzel a szisztematikus véletlenszerű mintavételi megközelítéssel. Valószínűleg még mindig ott lennék a kártyák számlálásakor, ha kipróbáltam volna egy másik véletlenszerű mintavételi módszert. (Oké, szóval nincs életem. Szépen kárpótoltak, nem bánom, hogy ezt a tervet kidolgoztam.,)
klaszter (terület) véletlenszerű mintavétel
a véletlenszerű mintavételi módszerekkel kapcsolatos probléma, amikor egy széles földrajzi régióban folyósított populációt kell mintát vennünk, az, hogy földrajzilag sok földet kell lefednie annak érdekében, hogy eljusson a mintavételezett egységekhez. Képzelje el, hogy egy egyszerű véletlenszerű mintát vesz New York állam összes lakosából személyes interjúk készítése érdekében. A sorsolás szerencséjével olyan válaszadókkal fog végezni, akik az egész államból származnak. Az interjúztatóknak sok utazásuk lesz., Pontosan erre a problémára találták ki a klaszter vagy a terület véletlenszerű mintavételét.
A klaszter mintavétel, akkor kövesse az alábbi lépéseket:
- oszd lakosság a klaszterek (általában mentén földrajzi határok)
- véletlenszerűen mintát klaszterek
- intézkedés minden egységnek belül mintában szereplő klaszterek
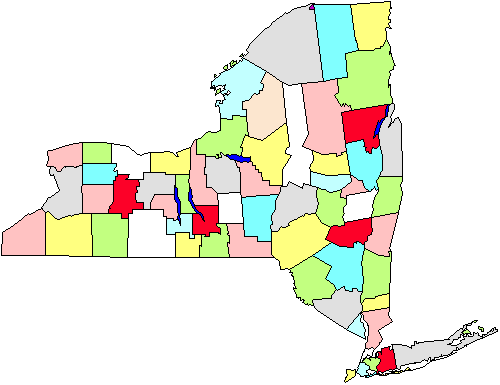
például az ábrán látjuk, hogy egy térkép a megyék New York Államban. Tegyük fel, hogy meg kell vizsgálnunk a városi önkormányzatokat, amelyek megkövetelik, hogy személyesen menjünk a városokba., Ha egy egyszerű véletlenszerű mintaállapotot készítünk, akkor földrajzilag le kell fednünk az egész államot. Ehelyett úgy döntünk, hogy öt megyéből álló klaszter-mintavételt végzünk (az ábrán piros színnel jelölve). Miután ezeket kiválasztottuk, az öt terület minden városi kormányához megyünk. Nyilvánvaló, hogy ez a stratégia segít abban, hogy takarékoskodjunk a futásteljesítményünkkel. A klaszter-vagy területmintavétel tehát ilyen helyzetekben hasznos, és elsősorban az adminisztráció hatékonysága érdekében történik., Vegye figyelembe azt is, hogy valószínűleg nem kell aggódnunk ennek a megközelítésnek a használata miatt, ha e-mailt vagy telefonos felmérést végzünk, mert nem számít annyira (vagy többe kerül, vagy nem hatékony), ahol hívunk vagy leveleket küldünk.
többlépcsős mintavétel
az eddig lefedett négy módszer-egyszerű, rétegzett, szisztematikus és Klaszter-a legegyszerűbb véletlenszerű mintavételi stratégiák. A legtöbb valódi alkalmazott társadalomkutatásban olyan mintavételi módszereket alkalmaznánk, amelyek lényegesen összetettebbek, mint ezek az egyszerű változatok., A legfontosabb elv itt az, hogy a korábban leírt egyszerű módszereket számos hasznos módon kombinálhatjuk, amelyek segítenek a mintavételi igények lehető leghatékonyabb és leghatékonyabb megoldásában. Amikor összekapcsoljuk a mintavételi módszereket, ezt a többlépcsős mintavételnek nevezzük.
például fontolja meg a New York-i állami lakosok személyes interjúk mintavételének gondolatát. Nyilvánvaló, hogy a folyamat első szakaszaként valamilyen típusú klaszter-mintavételt szeretnénk elvégezni. Lehet, hogy kóstoljuk meg a településeket vagy a népszámlálási traktusokat az egész államban., De a klaszter mintavételnél ezután mindenkit megmérünk a kiválasztott klaszterekben. Még akkor is, ha mintavételi népszámlálási traktusokat veszünk, előfordulhat, hogy nem tudjuk megmérni mindazokat, akik a népszámlálási traktusban vannak. Tehát létrehozhatunk egy rétegzett mintavételi folyamatot a klasztereken belül. Ebben az esetben lenne egy kétlépcsős mintavételi eljárás rétegzett minták belül klaszter minták. Vagy fontolja meg a diákok mintavételének problémáját az általános iskolákban. Kezdjük azzal, hogy az iskolai körzetek országos mintáját Közgazdasági és oktatási szint szerint csoportosítjuk., A kiválasztott körzetekben, csinálhatunk egy egyszerű véletlenszerű mintát az iskolákról. Az iskolákon belül, csinálhatunk egy egyszerű véletlenszerű mintát osztályokból vagy osztályokból. És az órákon belül akár egy egyszerű véletlenszerű mintát is csinálhatunk a diákokból. Ebben az esetben három vagy négy szakaszunk van a mintavételi folyamatban, mind rétegzett, mind egyszerű véletlenszerű mintavételt használunk. A különböző mintavételi módszerek kombinálásával számos valószínűségi mintavételi módszert tudunk elérni, amelyek a társadalmi kutatási kontextusok széles körében alkalmazhatók.