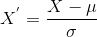Bevezetés a funkció méretezés
nemrég dolgoztam egy adathalmaz, hogy már több funkciót átívelő különböző nagyságrendű, tartomány, és egységek. Ez jelentős akadály, mivel néhány gépi tanulási algoritmus nagyon érzékeny ezekre a funkciókra.
biztos vagyok benne, hogy a legtöbb embernek szembe kellett néznie ezzel a kérdéssel a projektjeiben vagy a tanulási utazásában., Például az egyik jellemző teljesen kilogrammban van, míg a másik grammban van, a másik liter, stb. Hogyan használhatjuk ezeket a funkciókat, ha annyira különböznek attól, amit bemutatnak?
itt fordultam a szolgáltatás méretezésének fogalmához. Ez egy fontos része az adatok előfeldolgozás szakaszában, de láttam egy csomó kezdő figyelmen kívül hagyni (kárára a gépi tanulási modell).,

itt van a furcsa dolog a funkciók skálázásáról – javítja (jelentősen) egyes gépi tanulási algoritmusok teljesítményét, és egyáltalán nem működik mások számára. Mi lehet az oka ennek a furcsaságnak?
továbbá mi a különbség a normalizáció és a szabványosítás között? Ez a két leggyakrabban használt jellemző méretezési technika a gépi tanulásban, de megértésükben kétértelműség létezik. Mikor kell használni melyik technikát?,
ezekre a kérdésekre válaszolok, valamint a szolgáltatás méretezéséről szóló cikkben. Mi is végre funkció méretezés Python, hogy kapsz egy gyakorlat megértése, hogyan működik a különböző gépi tanulási algoritmusok.
Megjegyzés: feltételezem, hogy ismeri a Python és a Core gépi tanulási algoritmusokat., Ha új vagy ebben, javaslom, keresztül az alábbi tanfolyamok:
- Python Adatok Tudomány
- Minden szabad Gépi Tanulás Tanfolyamok által Analytics Vidhya
- Alkalmazott Gépi Tanulási
Tartalomjegyzék
- – Miért Használjuk a Funkció Méretezés?
- mi a normalizálás?
- mi a szabványosítás?
- a nagy kérdés-normalizálni vagy szabványosítani?,
- végrehajtási funkció méretezés Python
- normalizáció segítségével Sklearn
- szabványosítás segítségével Sklearn
- alkalmazása funkció méretezés gépi tanulási algoritmusok
- K-legközelebbi szomszédok (KNN)
- Support Vector Regressor
- döntés fa
miért kell használni funkció méretezés?
az első kérdés, amellyel foglalkoznunk kell-miért kell méretezni a változókat az adatkészletünkben? Egyes gépi tanulási algoritmusok érzékenyek a funkciók méretezésére, míg mások gyakorlatilag invariánsak., Hadd magyarázzam el ezt részletesebben.
gradiens Descent alapú algoritmusok
gépi tanulási algoritmusok, például lineáris regresszió, logisztikai regresszió, neurális hálózat stb. ez a gradiens leereszkedést optimalizálási technikaként használja, ezért az adatokat méretezni kell. Vessen egy pillantást az alábbi gradiens Süllyedés képletére:

az X funkcióérték jelenléte a képletben befolyásolja a gradiens Süllyedés lépésméretét. A funkciók tartományának különbsége különböző lépésméreteket okoz minden egyes funkcióhoz., Annak biztosítása érdekében, hogy a gradiens leereszkedés zökkenőmentesen mozogjon a minimumok felé, valamint hogy a gradiens Süllyedés lépései minden funkció esetében azonos sebességgel frissüljenek, az adatokat méretezzük, mielőtt a modellbe táplálnánk.
a hasonló léptékű funkciók segíthetik a gradiens leereszkedését gyorsabban a minima felé.
távolság alapú algoritmusok
távolság algoritmusok, mint a KNN, K-means, és SVM leginkább befolyásolja a funkciók körét., Ennek oka az, hogy a színfalak mögött az adatpontok közötti távolságokat használják hasonlóságuk meghatározására.
például, mondjuk, hogy van egy adatokat tartalmazó középiskolai CGPA pontszámok a diákok (kezdve 0-5), valamint a jövőbeli jövedelem (ezer Rúpia):

Mivel mind a funkciókat, különböző mérleg, van rá esély, hogy magasabb weightage adott funkciók magasabb mértékű. Ez hatással lesz a gépi tanulási algoritmus teljesítményére, és nyilvánvalóan nem akarjuk, hogy az algoritmusunk egy funkció felé haladjon.,
ezért méretezzük adatainkat, mielőtt egy távolság alapú algoritmust alkalmaznánk, hogy minden funkció egyformán hozzájáruljon az eredményhez.,az nts-t vagy B-vel, meg a között, B, C, mielőtt után a méretezés, mint alább látható:
- a Távolság AB előtt méretezés =>

- a Távolság BC előtt méretezés =>

- a Távolság AB után méretezés =>

- a Távolság BC után méretezés =>

Méretezés hozott mind a funkciókat be a képet, majd a távolságok már több hasonló, mint voltak, mielőtt alkalmazni a méretezés.,
fa alapú algoritmusok
a fa alapú algoritmusok viszont meglehetősen érzéketlenek a funkciók skálájára. Gondolj bele, egy döntési fa csak egy csomópontot oszt meg egyetlen funkció alapján. A döntési fa egy csomópontot oszt meg egy olyan funkcióra, amely növeli a csomópont homogenitását. Ezt a felosztást egy funkcióra más funkciók nem befolyásolják.
tehát a fennmaradó funkcióknak gyakorlatilag nincs hatása a felosztásra. Ez teszi őket invariánssá a funkciók skálájához!
mi a normalizálás?,
a normalizáció egy skálázási technika, amelyben az értékek eltolódnak és átméreteződnek úgy, hogy végül 0 és 1 között legyenek. Az is ismert, mint Min-Max méretezés.
itt van a normalizálás képlete:
itt az Xmax és az Xmin a szolgáltatás maximális és minimális értékei.,
- Ha az X értéke a minimális érték oszlopban, a számláló 0 lesz, így X’ 0
- másrészt, ha az X értéke a maximális érték oszlopban, a számláló eléri a nevező, így az értéke, X’ 1
- Ha az X értéke között a minimális, illetve a maximális értéket, akkor az értéke, X’ között 0, 1
Mi a Szabványosítás?
a szabványosítás egy másik skálázási technika, ahol az értékek az átlag körül helyezkednek el egy egység szórással., Ez azt jelenti, hogy az attribútum átlaga nulla lesz, a kapott eloszlásnak pedig egységnyi szórása van.
itt található a szabványosítás képlete:
a jellemzőértékek átlaga és
a jellemzőértékek szórása. Ne feledje, hogy ebben az esetben az értékek nem korlátozódnak egy adott tartományra.
most, a nagy kérdés a fejedben kell, hogy mikor kell használni a normalizáció, és mikor kell használni szabványosítás? Derítsük ki!,
A nagy kérdés-normalizálni vagy szabványosítani?
normalizáció vs. szabványosítás örök kérdés között gépi tanulás újonnan. Hadd dolgozzam ki a választ ebben a szakaszban.
- a normalizálás akkor jó, ha tudja, hogy az adatok terjesztése nem követi a Gauss-eloszlást. Ez hasznos lehet olyan algoritmusokban, amelyek nem feltételezik az adatok eloszlását, mint például a K-legközelebbi szomszédok vagy a neurális hálózatok.a
- szabványosítás viszont hasznos lehet olyan esetekben, amikor az adatok Gauss-eloszlást követnek., Ennek azonban nem feltétlenül kell igaznak lennie. A normalizációtól eltérően a szabványosításnak nincs határolási tartománya. Tehát, még akkor is, ha az adataiban kiugró adatok vannak, a szabványosítás nem érinti őket.
a nap végén azonban a normalizáció vagy szabványosítás használatának megválasztása az Ön problémájától és az Ön által használt gépi tanulási algoritmustól függ. Nincs nehéz és gyors szabály, hogy megmondja, mikor kell normalizálni vagy szabványosítani az adatokat., Mindig úgy kezdheti, hogy a modellt a raw, normalizált és szabványosított adatokhoz igazítja, majd a legjobb eredmény elérése érdekében összehasonlítja a teljesítményt.
Ez egy jó gyakorlat, hogy illeszkedjen a skálázó a képzési adatokat, majd használja, hogy átalakítsa a vizsgálati adatok. Ez elkerülné az adatszivárgást a modell tesztelési folyamata során. A célértékek méretezése általában nem szükséges.
végrehajtási funkció méretezés Python
most jön a szórakoztató része-üzembe, amit tanultunk a gyakorlatban., Fogok alkalmazni funkció méretezés néhány gépi tanulási algoritmusok a Big Mart adathalmaz vettem a DataHack platform.
kihagyom az előfeldolgozási lépéseket, mivel ezek nem tartoznak a bemutató hatálya alá. De megtalálja őket szépen magyarázható ebben a cikkben. Ezek a lépések lehetővé teszik, hogy elérje a felső 20 százalékos a hackathon ranglistán, így érdemes megnézni!
tehát először osszuk fel adatainkat képzési és tesztkészletekre:
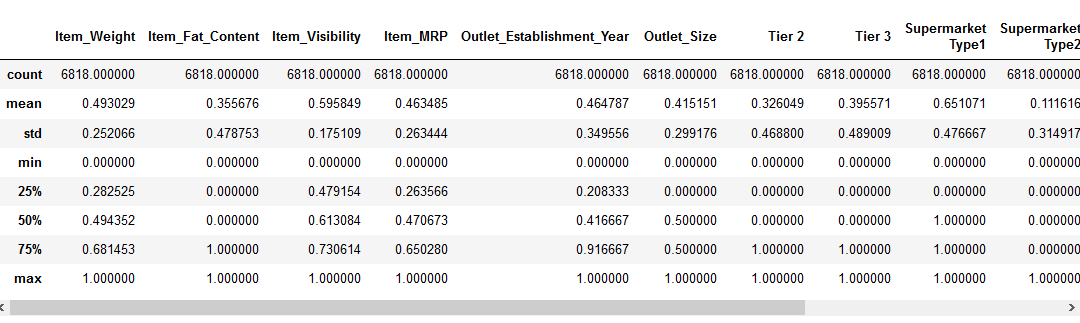
mielőtt áttérnénk a szolgáltatás méretezési részére, nézzük meg adataink részleteit a pd segítségével.,ismertesse () módszer:
láthatjuk, hogy van egy hatalmas különbség az értéktartományban jelen numerikus jellemzők: Item_Visibility, Item_Weight, Item_MRP, and Outlet_Establishment_Year. Próbáljuk meg kijavítani, hogy a funkció méretezés!
Megjegyzés: negatív értékeket fog észlelni az Item_Visibility funkcióban, mert log-átalakítást végeztem a funkció nyársságának kezelésére.
normalizáció sklearn
segítségével az adatok normalizálásához importálnia kell a minmaxscalar fájlt a sklearn könyvtárból, majd alkalmaznia kell az adatkészletünkre., Akkor csináljuk!
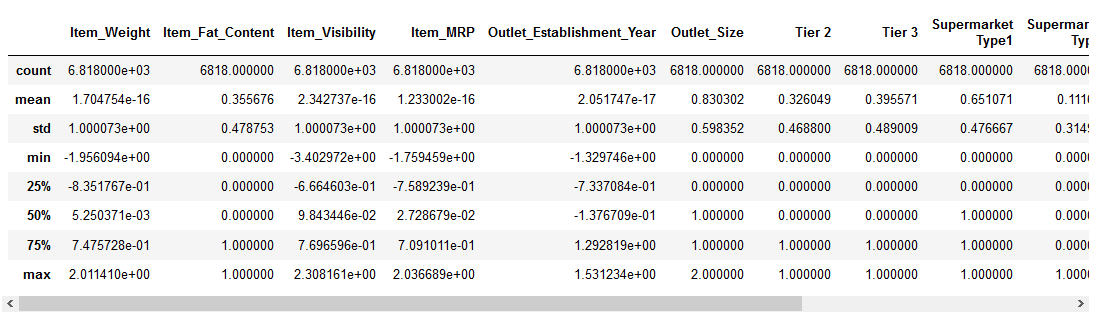
lássuk, hogyan befolyásolta a normalizálás az adatkészletünket:
minden funkciónak minimális értéke 0, maximális értéke pedig 1. Tökéletes!
próbálja ki a fenti kódot az alábbi ÉLŐ kódolási ablakban!!
ezután próbáljuk meg egységesíteni adatainkat.
szabványosítás a sklearn
használatával az adatok szabványosításához importálnia kell a StandardScalar fájlt a sklearn könyvtárból, majd alkalmaznia kell azt az adatkészletünkre., Itt van, hogyan lehet csinálni:
észrevetted volna, hogy csak a numerikus oszlopokra alkalmaztam szabványosítást, nem pedig a másik-forró kódolt funkciókat. Az Egyforrós kódolt funkciók szabványosítása azt jelentené, hogy a disztribúciót kategorikus funkciókhoz rendeljük. Nem akarod ezt tenni!
de miért nem tettem ugyanezt az adatok normalizálása közben? Mivel az Egyforrós kódolt funkciók már a 0-1 közötti tartományban vannak. Tehát a normalizálás nem befolyásolja értéküket.,
vessünk egy pillantást, hogyan szabványügyi átalakította az adatok:
A számszerű jellemzők most középpontjában az egy egységnyi szórás. Király!
Nem méretezett, normalizált és szabványosított adatok összehasonlítása
mindig nagyszerű az adatok megjelenítése, hogy megértsük a jelen eloszlást. Láthatjuk az összehasonlítást a méretezetlen és méretezett adatok között a boxplots segítségével.
az adatvizualizációról itt olvashat bővebben.,
észreveheti, hogy a funkciók méretezése mindent perspektívába hoz. A funkciók most összehasonlíthatóbbak, hasonló hatással lesznek a tanulási modellekre.
méretezés alkalmazása gépi tanulási algoritmusokra
itt az ideje, hogy néhány gépi tanulási algoritmust képezzünk adatainkra, hogy összehasonlítsuk a különböző méretezési technikák hatásait az algoritmus teljesítményére. A skálázás hatását különösen három algoritmusra szeretném látni: K-legközelebbi szomszédok, Support Vector Regressor és Decision Tree.,
k-legközelebbi szomszédok
mint korábban láttuk, a KNN egy távolság alapú algoritmus, amelyet a funkciók köre befolyásol. Lássuk, hogyan működik az adatainkon a méretezés előtt és után:
láthatjuk, hogy a funkciók méretezése csökkentette a KNN modell RMSE pontszámát. Pontosabban, a normalizált adatok egy kicsit jobban teljesítenek, mint a szabványosított adatok.
megjegyzés: itt mérem az RMSE-t, mert ez a verseny értékeli az RMSE-t.
Support Vector Regressor
SVR egy másik távolság alapú algoritmus., Tehát nézzük meg, hogy jobban működik-e a normalizálás vagy a szabványosítás:
láthatjuk, hogy a funkciók méretezése csökkenti az RMSE pontszámot. A szabványosított adatok pedig jobban teljesítettek, mint a normalizált adatok. Miért gondolod, hogy ez a helyzet?
a sklearn dokumentáció szerint az SVM az RBF kernellel azt feltételezi, hogy az összes funkció nulla körül van, a variancia pedig azonos sorrendben van. Ez azért van, mert egy olyan funkció, amelynek varianciája nagyobb, mint másoké, megakadályozza, hogy a becslő megtanulja az összes funkciót., Zseniális!
döntés fa
már tudjuk, hogy a döntés fa invariáns jellemző méretezés. De meg akartam mutatni egy gyakorlati példát arra, hogyan működik az adatokon:
láthatjuk, hogy az RMSE pontszám nem mozdult egy hüvelyk a funkciók méretezésére. Tehát biztos lehet benne, ha fa alapú algoritmusokat használ az adatain!,
a Végén Megjegyzi,
Ez a bemutató vonatkozik a relevancia a szolgáltatás segítségével méretezés az adatok, hogy a normalizálás, valamint szabványügyi különböző hatások a dolgozó a gépi tanulási algoritmusok
ne feledje, hogy nincs helyes válasz, hogy mikor kell használni a normalizálás át szabványosítás, illetve fordítva. Minden az Ön adataitól és a használt algoritmustól függ.
következő lépésként azt javaslom, hogy próbálja ki a funkciók skálázását más algoritmusokkal, és derítse ki, mi működik a legjobban-normalizáció vagy szabványosítás?, Azt javaslom, hogy használja a BigMart értékesítési adatait erre a célra, hogy fenntartsa a cikk folytonosságát. Ne felejtsd el megosztani a betekintést az alábbi megjegyzés szakaszban!
ezt a cikket a