Bevezetés
Az adatok rendezése azt jelenti, hogy egy bizonyos sorrendben rendezzük, gyakran egy tömb-szerű adatszerkezetben. Használhatja a különböző rendelési kritériumok, közös is, hogy válogatás számok legalább a legnagyobb, vagy fordítva, vagy válogatás húrok lexikográfiailag. Még a saját kritériumait is meghatározhatja, és ezt a cikk végére gyakorlati módokon fogjuk megtenni.,
Ha érdekel, hogyan válogatás működik, fedezzük különböző algoritmusok, a hatékony, de intuitív megoldások, hatékony algoritmusok, amelyek hajtják végre, a Java pedig más nyelv.
különböző válogatási algoritmusok léteznek, és nem mindegyik egyformán hatékony. Elemezzük az idő összetettségét, hogy összehasonlítsuk őket, és megnézzük, melyik teljesít a legjobban.,
A lista algoritmus megtudhatja, itt nem azt jelenti, kimerítő, de összeállítottunk néhány a leggyakoribb, leghatékonyabb, akik segítség az induláshoz:
- Buborék Rendezés
- Beszúrás Sort
- kiválasztásos Rendezés
- Merge Sort
- Heapsort
- Gyorsrendezés
- Rendezés Java
Megjegyzés: Ez a cikk nem foglalkozik egyidejű rendezése, hiszen ez azt jelentette, kezdőknek.
Bubble Rendezés
magyarázat
Bubble rendezés működik csere szomszédos elemek, ha ők nem a kívánt sorrendben., Ez a folyamat megismétlődik a tömb elejétől, amíg az összes elem rendben van.
tudjuk, hogy minden elem rendben van, amikor az egész iterációt egyáltalán nem cseréljük-akkor minden elem, amelyet összehasonlítottunk, a kívánt sorrendben volt a szomszédos elemekkel, kiterjesztéssel pedig az egész tömb.
Itt vannak a lépések, a tömb rendezése számok legkisebb legnagyobb:
-
4 2 1 5 3: Az első két eleme a megfelelő sorrendben, így cserélni őket.
-
2 4 1 5 3: a második két elem is rossz sorrendben van, ezért cserélünk.,
-
2 1 4 5 3: Ez a kettő a megfelelő sorrendben van, 4 < 5, tehát egyedül hagyjuk őket.
-
2 1 4 5 3: egy másik swap.
-
2 1 4 3 5: Itt van a kapott tömb egy iteráció után.
mivel legalább egy csere történt az első lépés során (valójában három volt), újra át kell mennünk az egész tömbön, és meg kell ismételnünk ugyanazt a folyamatot.
a folyamat megismétlésével, amíg nem történik több csere, lesz egy rendezett tömb.,
ennek az algoritmusnak az oka a buborék rendezés, mert a számok egyfajta “buborék fel” a ” felületre.”Ha ismét átmegy a példánkon, egy adott számot követve (a 4 nagyszerű példa), akkor a folyamat során lassan jobbra mozog.
minden szám apránként, balról jobbra mozog a megfelelő helyükre, mint például a víztestből lassan emelkedő buborékok.
Ha részletes, dedikált cikket szeretne olvasni a buborék rendezéséhez,akkor fedezünk!,
implementáció
A Bubble Sort hasonló módon fogjuk végrehajtani, mint a szavakban. A funkció belép egy ideig hurok, amelyben átmegy a teljes tömb csere szükség szerint.
feltételezzük, hogy a tömb rendezve van, de ha válogatás közben hibásnak bizonyulunk (ha swap történik), akkor egy másik iteráción megyünk keresztül. A while-loop ezután addig folytatódik, amíg nem sikerül átjutnunk az egész tömbben csere nélkül:
ennek az algoritmusnak a használatakor óvatosnak kell lennünk, hogyan állapítjuk meg swap állapotunkat.,
például, ha a a >= a végtelen hurokkal végződhetett volna, mert egyenlő elemeknél ez a kapcsolat mindig true lenne, ezért mindig cseréljük őket.
idő összetettsége
a buborék rendezés idő összetettségének megállapításához meg kell vizsgálnunk a lehető legrosszabb forgatókönyvet. Mi a maximális számú alkalommal kell átmenni az egész tömb, mielőtt már rendezve?, Tekintsük a következő példát:
5 4 3 2 1az első iterációban az 5 “buborékol a felszínre”, de a többi elem csökkenő sorrendben marad. Minden elemhez egy iterációt kell tennünk, kivéve az 1-et, majd egy másik iterációt, hogy ellenőrizzük, hogy minden rendben van-e, tehát összesen 5 iteráció.
bontsa ki ezt an elemekre, ami azt jelenti, hogy meg kell tennie a n iterációkat., A kódot tekintve ez azt jelentené, hogy awhile hurok an idők maximális értékét futtathatja.
mindegyik n alkalommal iteráljuk az egész tömböt (for-loop a kódban), ami azt jelenti, hogy a legrosszabb esetben az idő összetettsége O(n^2) lenne.
Megjegyzés: Az idő összetettsége mindig O(n^2) lenne, ha nem lenne a sorted logikai ellenőrzés, amely megszünteti az algoritmust, ha nincsenek swapok a belső hurokban – ami azt jelenti, hogy a tömb rendezve van.,
Beszúrási Rendezés
magyarázat
a beszúrási Rendezés mögött meghúzódó ötlet a tömböt a rendezett és rendezetlen alarráikra osztja.
a rendezett rész elején 1 hosszúságú, és megfelel a tömb első (bal-legtöbb) elemének. A tömbön keresztül iterálunk, majd minden iteráció során a tömb rendezett részét egy elemmel bővítjük.
bővítéskor az új elemet a megfelelő helyre helyezzük a rendezett alrendben. Ezt úgy tesszük, hogy az összes elemet jobbra toljuk, amíg meg nem találjuk az első elemet, amelyet nem kell váltanunk.,
például, ha a következő tömb a félkövér rész szerint van rendezve, egy növekvő sorrendben, a következő történik:
-
3 5 7 8 4 2 1 9 6: veszünk 4 emlékszem, hogy ezt kell beszúrni. Mivel 8 > 4, eltolódunk.
-
3 5 7 x 8 2 1 9 6: ahol az x értéke nem döntő fontosságú, mivel azonnal felülírják (akár 4, Ha ez a megfelelő hely, akár 7, ha eltolódunk). Mivel 7 > 4, eltolódunk.,
-
3 4 5 7 8 2 1 9 6
3 5 x 7 8 2 1 9 6
3 x 5 7 8 2 1 9 6
a folyamat után a rendezett részt egy elem kibővítette, most négy elem helyett öt van. Minden iteráció ezt teszi, és a végére az egész tömb lesz rendezve.
Ha el szeretne olvasni egy részletes, dedikált cikket a beillesztési rendezéshez, akkor fedezünk!,
implementáció
idő összetettsége
ismét meg kell vizsgálnunk az algoritmusunk legrosszabb forgatókönyvét, és ismét ez lesz a példa, ahol az egész tömb leereszkedik.
Ez azért van, mert minden iterációban az egész rendezett listát egy, ami O(n). Ezt minden tömb minden elemére meg kell tennünk, ami azt jelenti, hogy O(n^2) korlátozza.
kiválasztási Rendezés
magyarázat
kiválasztási Rendezés is osztja a tömb egy rendezett és rendezetlen alrendezés., Bár ebben az időben, a rendezett subarray képződik behelyezése a minimális eleme a rendezetlen subarray végén a rendezett tömb, a csere:
-
3 5 1 2 4
-
1 5 3 2 4
-
1 2 3 5 4
-
1 2 3 5 4
-
1 2 3 4 5
-
1 2 3 4 5
Végrehajtási
Az egyes iterációs feltételezzük, hogy az első osztályozatlan elem a minimális, illetve halad végig a többit, hogy ha van egy kisebb elem.,
miután megtaláltuk a tömb nem rendezett részének aktuális minimumát, kicseréljük az első elemre, és a rendezett tömb részének tekintjük:
idő összetettsége
a tömb hosszához a minimum O(n) megtalálása, mert ellenőriznünk kell az összes elemet. Meg kell találnunk a tömb minden egyes elemére a minimumot, így az egész folyamatot O(N^2) korlátozza.,
Merge Rendezés
magyarázat
a Merge Rendezés rekurziót használ a korábban bemutatott algoritmusoknál hatékonyabb rendezés problémájának megoldására, különös tekintettel a divide and conquer megközelítésre.
mindkettőt Használja ezeket a fogalmakat, meglesz az egész tömb le a két subarrays aztán:
- Rendezés a bal fele a array (rekurzívan)
- Rendezés a jobb fele a array (rekurzívan)
- Merge a megoldások
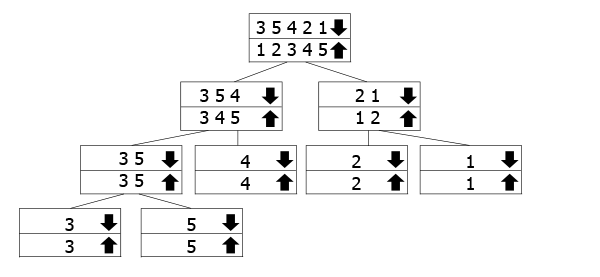
Ez a fa azt jelentette, hogy azt mutatják, hogy a rekurzív hívások munka., A lefelé mutató nyíllal jelölt tömbök azok, amelyekre a funkciót hívjuk, miközben összevonjuk a felfelé mutató nyilakat. Tehát kövesse a lefelé mutató nyilat a fa aljára,majd menjen vissza felfelé, majd egyesüljön.
példánkban a 3 5 3 2 1 tömb van, tehát 3 5 4 és 2 1. A rendezéshez tovább osztjuk őket összetevőikre. Amint elérjük az alját, elkezdjük összevonni és szétválogatni őket, ahogy haladunk.,
Ha el szeretne olvasni egy részletes, dedikált cikket a Merge rendezéshez,akkor fedezünk!
implementáció
az alapfunkció nagyjából úgy működik, ahogy azt a magyarázat tartalmazza. Mi csak halad indexek leftés right amelyek indexek a bal-a legtöbb és a jobb-legtöbb elem a subarray szeretnénk rendezni. Kezdetben ezeknek a megvalósítástól függően 0 és array.length-1 kell lenniük.,
a rekurzió alapja biztosítja a kilépést, amikor befejeztük, vagy amikor rightés left találkoznak egymással. Megtaláljuk a mid középpontot, és rekurzív módon rendezzük a subarrays-t balra és jobbra, végül egyesítve megoldásainkat.
Ha emlékszel a fa grafikánkra, akkor azon tűnődhetsz, miért NEM hozunk létre két új kisebb tömböt, és adjuk át őket helyette. Ez azért van, mert nagyon hosszú tömbökön ez hatalmas memóriafogyasztást okozna valami, ami lényegében felesleges.,
Merge Sort már nem működik a helyén, mert a merge lépés, és ez csak arra szolgál, hogy rontja a memória hatékonyságát. A rekurzió fánk logikája egyébként ugyanaz marad, bár csak az általunk használt indexeket kell követnünk:
a rendezett subarrays egyesítéséhez mindegyik hosszát ki kell számítanunk, és ideiglenes tömböket kell készíteni, hogy másoljuk őket, így szabadon megváltoztathatjuk fő tömbünket.
másolás után végigmegyünk a kapott tömbben, majd hozzárendeljük az aktuális minimumot., Mivel a subarrays rendezve, mi csak úgy döntött, a kisebb a két elem, hogy még nem választották eddig, és mozgassa az iterátor, hogy subarray előre:
idő összetettsége
Ha azt akarjuk, hogy ebből a komplexitás rekurzív algoritmusok, mi lesz, hogy egy kicsit mathy.
a fő tétel a rekurzív algoritmusok idő összetettségének kitalálására szolgál. A nem rekurzív algoritmusok esetében általában a pontos idő összetettségét valamilyen egyenletnek írhatjuk, majd a Big-O jelölést használjuk, hogy hasonló viselkedésű algoritmusok osztályaiba rendezzük őket.,
a rekurzív algoritmusok problémája az, hogy ugyanaz az egyenlet így néz ki:
$
T (n) = aT (\frac{n} {b}) + cn^k
$
maga az egyenlet rekurzív! Ebben az egyenletben a a megmondja, hogy hányszor hívjuk a rekurziót, és a b elmondja nekünk, hogy hány részre oszlik a problémánk. Ebben az esetben ez lényegtelen megkülönböztetésnek tűnhet, mivel egyenlőek az egyesülések esetében, de bizonyos problémák esetén előfordulhat, hogy nem.,
az egyenlet többi része az összes ilyen megoldás egyesítésének összetettsége a végén., A Mester Tétel megoldja ezt az egyenletet nekünk:
$$
T(n) = \Bigg\{
\begin{mátrix}
O(n^{log_ba}), &>b^k \\ O(n^klog n), & a = b^k \\ O(n^k), & < b^k
\end{mátrix}
$$
Ha T(n) futásidejű az algoritmus, amikor tömb rendezése a hossza n, Merge Sort volna futni, kétszer tömbök, amelyek hosszának a fele az eredeti tömb.,
tehát ha vana=2,b=2. Az egyesítési lépés o(n) memóriát vesz igénybe, így k=1. Ez azt jelenti, hogy az Egyesítési Rendezés egyenlete a következőképpen néz ki:
$
T(n) = 2T(\frac{n}{2})+cn
$
Ha a mester tételt alkalmazzuk, látni fogjuk, hogy esetünk az, ahol a=b^k mert 2=2^1. Ez azt jelenti, hogy bonyolultságunk O (nlog n). Ez egy rendkívül jó idő komplexitás a rendezési algoritmus számára, mivel bebizonyosodott, hogy egy tömb nem rendezhető gyorsabban, mint az O(nlog n).,
míg a bemutatott verzió memóriaigényes, vannak összetettebb változatai Merge Sort, hogy vegye fel csak O(1) helyet.
ezenkívül az algoritmus rendkívül könnyen párhuzamosítható, mivel az egyik csomópontból származó rekurzív hívások külön ágaktól függetlenül futtathatók. Bár nem fogunk belemenni, hogy hogyan és miért, mivel ez túlmutat ezen a cikken, érdemes szem előtt tartani az adott algoritmus használatának előnyeit.,
Heapsort
magyarázat
ahhoz, hogy megértsük, miért működik a Heapsort, először meg kell értenünk a struktúrát, amelyen alapul – a halom. Fogunk beszélni szempontjából egy bináris halom kifejezetten, de lehet általánosítani a legtöbb ez más halom struktúrák is.
a halom olyan fa, amely kielégíti a kupac tulajdonságát, vagyis minden csomópont esetében minden gyermeke egy adott kapcsolatban áll vele. Ezenkívül a halomnak szinte teljesnek kell lennie., Egy majdnem teljes bináris fa mélysége dvan egy altípusa mélység d-1 ugyanazzal a gyökérrel, amely teljes, és amelyben minden csomópont egy bal leszármazottja van egy teljes bal altípusa. Más szavakkal, csomópont hozzáadásakor mindig a bal szélső pozíciót keressük a legmagasabb hiányos szinten.
Ha a kupac egy max-kupac, akkor az összes gyerek kisebb, mint a szülő, és ha ez egy min-halom mindegyik nagyobb.,
más szóval, ahogy lefelé haladsz a fán, kisebb és kisebb számokra (min-heap) vagy nagyobb és nagyobb számokra (max-heap) jutsz. Íme egy példa egy max-kupacra:
ezt a Max-kupacot a memóriában tömbként ábrázolhatjuk a következő módon:
8 5 6 3 1 2 4a gráf szintről balról jobbra olvasva lehet elképzelni., Amit ezzel elértünk, az az, hogy ha a kth elemet vesszük a tömbben, akkor a gyermekek pozíciói 2*k+1 és 2*k+2 (feltételezve, hogy az indexelés 0-kor kezdődik). Ezt saját maga ellenőrizheti.
fordítva, akth elem esetében a szülő pozíciója mindig(k-1)/2.
ennek ismeretében könnyen “max-heapify” bármely adott tömb. Minden egyes elemnél ellenőrizze, hogy bármelyik gyermeke kisebb-e., Ha igen, cserélje ki az egyiket a szülővel, majd ismételje meg ezt a lépést a szülővel (mert az új nagy elem még mindig nagyobb lehet, mint a másik gyermeke).
a leveleknek nincs gyermeke, tehát triviálisan max-halmok saját:
-
6 1 8 3 5 2 4: mindkét gyermek kisebb, mint a szülő, tehát minden ugyanaz marad.
-
6 1 8 3 5 2 4: Mert 5 > 1, cseréljük őket. Mi rekurzívan heapify 5 Most.
-
6 5 8 3 1 2 4: mindkét gyermek kisebb, tehát semmi sem történik.,
-
6 5 8 3 1 2 4: Mivel 8 > 6, cseréljük őket.
-
8 5 6 3 1 2 4: megvan a halom a fenti képen!
miután megtanultuk egy tömb heapify-ját, a többi nagyon egyszerű. A kupac gyökerét a tömb végével cseréljük, a tömböt pedig egyenként lerövidítjük.,
Mi heapify a rövidített tömb újra, majd ismételje meg a folyamatot:
-
8 5 6 3 1 2 4
-
4 5 6 3 1 2 8: cserélték
-
6 5 4 3 1 2 8: heapified
-
2 5 4 3 1 6 8: cserélték
-
5 2 4 2 1 6 8: heapified
-
1 2 4 2 5 6 8: cserélték
És így tovább, biztos vagyok benne, hogy látni lehet a minta.
végrehajtás
idő összetettsége
amikor megnézzük a heapify() funkciót, úgy tűnik, hogy minden O-ban történik (1), de aztán ott van az a bosszantó rekurzív hívás.,
hányszor fogják ezt hívni, a legrosszabb esetben? Nos, a legrosszabb esetben egészen a kupac tetejéig terjed. Ezt úgy fogja megtenni, hogy az egyes csomópontok szülőjéhez ugrik, így a i/2pozíció körül. ez azt jelenti, hogy legrosszabb esetben a log n ugrik, mielőtt eléri a csúcsot, tehát a komplexitás O(log n).
mert heapSort() egyértelműen O(n) miatt for-hurkok iterating a teljes tömb, ez tenné a teljes komplexitás Heapsort O(nlog n).,
a Heapsort egy helyben rendezés, ami azt jelenti, hogy O(1) további helyet foglal el, szemben az Egyesítési rendezéssel, de vannak hátrányai is, például nehéz párhuzamosítani.
Quicksort
magyarázat
a Quicksort egy másik megosztási és Meghódítási algoritmus. A tömb egyik elemét választja el a pivot-tól, és a körülötte lévő összes többi elemet rendezi, például a kisebb elemeket balra, a nagyobbakat jobbra.
Ez garantálja, hogy a pivot a folyamat után a megfelelő helyen legyen., Ezután az algoritmus rekurzívan ugyanezt teszi a tömb bal és jobb oldalán.
Végrehajtási
Idő Komplexitás
Az idő összetettsége Gyorsrendezés kifejezhető a következő egyenlettel:
$$
T(n) = T(k) + T(n-k-1) + O(n)
$$
A legrosszabb eset az, amikor a legnagyobb vagy legkisebb elem mindig választottak fordítsa. Az egyenlet így néz ki:
$
T (n) = T(0) + T(n-1) + O(n) = T(n-1) + O(n)
$
ez kiderül, hogy O(n^2).,
Ez rosszul hangzik, mivel már megtanultunk több algoritmust, amelyek legrosszabb esetben O(nlog n) időben futnak, de a Quicksort valójában nagyon széles körben használják.
Ez azért van, mert nagyon jó átlagos futási ideje van, amelyet O(nlog n) is határol, és nagyon hatékony a lehetséges bemenetek nagy részében.
az összevonás egyik oka az, hogy nem igényel extra helyet, az összes válogatás helyben történik, és nincs drága allokációs és deallokációs hívás.,
teljesítmény-összehasonlítás
hogy mindent elmondtak, gyakran hasznos ezeket az algoritmusokat néhányszor futtatni a gépen, hogy képet kapjanak arról, hogyan teljesítenek.
másképp fognak fellépni a különféle gyűjteményekkel, amelyeket természetesen válogatnak, de még ezt szem előtt tartva is képesnek kell lennie arra, hogy észrevegyen néhány tendenciát.
lehet, hogy a megvalósítások, egyenként egy példányát megkeverjük tömb 10.000 egész számok:
Mi nyilvánvalóan látjuk, hogy a Buborék Rendezés a legrosszabb, amikor a teljesítmény., Kerülje a gyártás során történő használatát, ha nem tudja garantálni, hogy csak kis gyűjteményeket fog kezelni, és nem akadályozza meg az alkalmazást.
HeapSort és QuickSort a legjobb teljesítmény-bölcs. Bár hasonló eredményeket produkálnak, a QuickSort általában egy kicsit jobb és következetesebb – ami stimmel.
Válogatás Java
összehasonlítható felület
Ha saját típusai vannak, nehézkes lehet egy külön rendezési algoritmus végrehajtása mindegyikhez. Ezért a Java olyan felületet biztosít, amely lehetővé teszi aCollections.sort() használatát a saját osztályain.,
ehhez az osztálynak végre kell hajtania a Comparable<T>interfészt, ahol Taz Ön típusa, és felülírja a .compareTo() nevű módszert.
Ez a módszer negatív egész számot ad vissza, ha this kisebb, mint az argumentumelem, 0 ha egyenlő, és pozitív egész szám, ha this nagyobb.
példánkban egy Student osztályt hoztunk létre, és minden diákot egy id azonosítunk, majd egy évvel elkezdtük a tanulmányaikat.,
Szeretnénk valahogy őket, elsősorban a generációk, hanem másodlagosan által Id:
Pedig itt van, hogyan kell használni az alkalmazás:
Teljesítmény:
Összehasonlító Felület
lehet, hogy valami a tárgyak egy szokatlan mód, egy-egy konkrét célra, de nem akarjuk végrehajtani, hogy az alapértelmezett viselkedés az osztályban, vagy lehet, hogy válogatás gyűjtemény egy beépített típus nem alapértelmezett módja.
ehhez a Comparator felületet használhatjuk., Például, vegyük a Student órán, de valahogy csak ID:
Ha kicseréljük az valami hívás a legfontosabb a következő:
Arrays.sort(a, new SortByID());Teljesítmény:
Hogyan Működik
Collection.sort() működik, hívja a mögöttes Arrays.sort() módszerrel, míg a válogatás saját maga használja a Beillesztés Sort a tömbök rövidebb, mint a 47-es, valamint a Gyorsrendezés a többi.,
Ez alapján egy adott két-pivot végrehajtása Quicksort, amely biztosítja, hogy elkerüli a legtöbb tipikus oka a lebomlás a másodfokú teljesítmény, szerint a jdk10 dokumentáció.
következtetés
a rendezés nagyon gyakori művelet az adatkészletekkel, függetlenül attól, hogy tovább elemezzük őket, gyorsítsuk fel a keresést hatékonyabb algoritmusok segítségével, amelyek a rendezett adatokra támaszkodnak, szűrjük az adatokat stb.
a rendezést számos nyelv támogatja, az interfészek gyakran elhomályosítják, hogy mi történik valójában a programozóval., Bár ez az absztrakció üdvözlendő és szükséges a hatékony munkához, néha halálos lehet a hatékonyság szempontjából, és jó tudni, hogyan kell különböző algoritmusokat végrehajtani, ismerni kell azok előnyeit és hátrányait, valamint hogyan lehet könnyen hozzáférni a beépített implementációkhoz.